Posts Tagged ‘convertion’
Tuesday, August 28th, 2018 
As I'm currently looking for ways to maximize my incomes without taking participation in 5 days week 8 hours schedule in a Big Corporation office job (which prooved for me to be a terrible slavery) I decided to give Free Lancing a try once again.
Historically I have registrations in some of the most popular Free Lancing services Web platforms such as freelancer.com and upwork.com.
But none of them really was easy enough to handle as applying and winning a project there is usually a lot of headbanging into the walls and the platforms are full of clients that are looking for free lancers for short-term projects the work selection there required too much work, often projects offered there are seriously under-paid and its really hard to negotiate with many of the clients as they're unprofessional in the fields they're working (don't get me wrong I'm not saying many people are not very successful with this platforms, and that the platforms are not providing work for me I only say it is not really something to my liking …
In the mean time if you happen to read this article and looking for a High Quality Empoyee Cheap System Administrator or automation developmer, an IT counseling FreeLancer or a Ultra cheap WebHosting service in the European Union, I'll be very happy if you become my client.
Anyways … further on I decided to further experiment a little bit with other Free Lancing platforms (suggested by a friend Mitko Ivanov who helped me a lot with things and is continuing to help me over the last year ).
So following his kind suggestion I already tried one of the popular FreeLancing freeeup.com which is looking only for a best specialists into the fields of Marketing, Development, System Administration etc. but even though I tried hard with them the guys decided I am not matching there criteria for a the best 1% of all the people in the field of IT so my application for the platform was rejected twice over the last 1 month and a half.
Another similar new platform for free lancing that looks promising that I've learned about is toptal.com (there site Slogan is Hire FreeLance Talent from the Top 3%) so I went there and registered.
I had hit a road block there too as it seems, there website registration form was not tested enough with non-Windows operating systems with Mozilla Firefox and as it happens that I am using Debian GNU / Linux for my Desktop their drop-down menus was not working, just like some of the form on their website regular expression checks failed.
I've contacted the guys to inform them about their problems (and they kindly advised) I just give a try a registration with different browser (i.e. Google Chrome) which I immediately did and registratoin there was finally a success.
I have to say the new user application form registration of toptal also annoyed me with the stupid requirement to provide a picture in 1000px x 1000px but as this freelancing platform is still new and has way to go until it is established name in the field of freelancing such as upwork.com and I warmly excuse them.
Once registerered for them the user has to schedule an entry interview just like it goes with a standard company interview with a kind of Human Resources (HR) specialist and I guess some technical guys in order to evaluate on your value (Ha-Ha, someone else to determine your value is already crazy but all crazy employees do it still, of course I don't care as I well know that my value is much more than what they put on me).
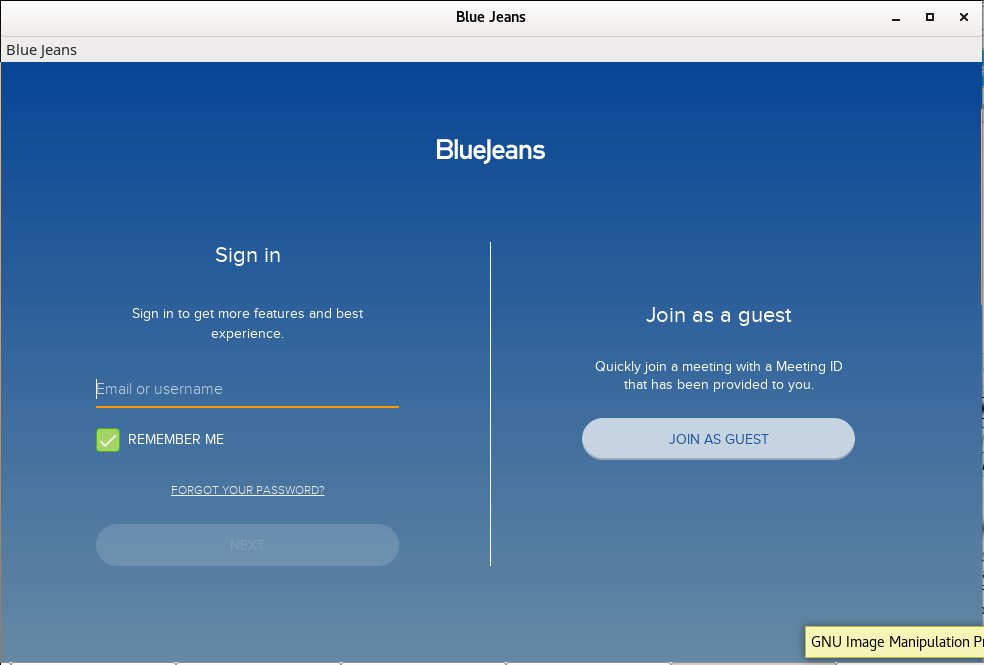
The online interview once scheduled has to be done in a Web Meeting (Online Rooms) Platform called BlueJeans similar to Cisco WebEx (that is today heavily used in Corporate world in companies such as Hewlett Packard where we used it heavily, IBM, Concentrix etc.) and others Zoom, JoinMe GotoMeeting, HighFive.
As you could guess BlueJeans (which is by the way a Cloud based meeting software – yackes !) is planned to work mainly on Windows and Mac OS Operating Systems and even though there is a BlueJeans Linux version the provided binary is only for RedHat based linuxes in the RPM binary package format, so in order for me to participate in the scheduled meeting, I either had to port the package and install it on my Debian (what triggeted me to write this article or) use a Virtual Machine such as VirtualBox or VMWare running some kind of Windows OS such as Windows 8 / 10 etc.
Even though I have a Windows 10 OS testbed in a Virtualbox container, I preferred to not use it for BlueJeans and do it the hard way and install BlueJeans on my Debian 9.5 Stretch Linux.
That appeared to be a relatively easy process, so below is how I did it:
1. Download alien convertion (tool) that allows you to convert RPM -> deb, Slackware -> Deb and Linux Standard Base (LDB) packages to deb package format
noah:~# apt-get install –yes alien
…
2. Download latest BlueJeans version from BlueJeans website
As of time of writting this article the download link for bluejeans online conferencing software is here
noah:~# wget https://swdl.bluejeans.com/desktop/linux/1.36/1.36.9/bluejeans-1.36.9.x86_64.rpm
…
3. Convert bluejeans rpm package with alien
noah:~# alien –to-deb bluejeans-*.rpm
Warning: Skipping conversion of scripts in package bluejeans: postinst postrm preinst prerm
Warning: Use the –scripts parameter to include the scripts.
bluejeans_1.36.9-2_amd64.deb generated
root@jericho:/home/hipo/Свалени# dpkg -i bluejeans_*.deb
Selecting previously unselected package bluejeans.
(Reading database … 516203 files and directories currently installed.)
Preparing to unpack bluejeans_1.36.9-2_amd64.deb …
Unpacking bluejeans (1.36.9-2) …
Setting up bluejeans (1.36.9-2) …
4. Install the deb package as usual with dpkg tool
noah: ~# dpkg -i bluejeans_*.deb
By default BlueJeans were installed under directory /opt/bluejeans
noah:~# ls -al /opt/bluejeans/bluejeans-bin
-rwxr-xr-x 1 root root 72423392 Jun 14 02:31 /opt/bluejeans/bluejeans-bin*
5. Fix missing library links if such are present in order to make BlueJeans workable
Historically I have dealt with many Linux programs that are provided only in RPM package format and I knew that often once an RPM is converted to DEB with alien due to the package dependency differences on Redhats (CentOS / Fedora etc.) there are problems with missing libraries.
This time this was the case as well, so as usual right after install I did a check up with ldd (print shared object dependencies Linux command) to find out about missing libraries and one library appeared missing.
noah:~# ldd /opt/bluejeans/bluejeans-bin
linux-vdso.so.1 (0x00007fffa2182000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007fae95f5e000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fae95d5a000)
libgtk-x11-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgtk-x11-2.0.so.0 (0x00007fae95718000)
libgdk-x11-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgdk-x11-2.0.so.0 (0x00007fae95463000)
libatk-1.0.so.0 => /usr/lib/x86_64-linux-gnu/libatk-1.0.so.0 (0x00007fae9523d000)
libpangocairo-1.0.so.0 => /usr/lib/x86_64-linux-gnu/libpangocairo-1.0.so.0 (0x00007fae95030000)
libgdk_pixbuf-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgdk_pixbuf-2.0.so.0 (0x00007fae94e0c000)
libcairo.so.2 => /usr/lib/x86_64-linux-gnu/libcairo.so.2 (0x00007fae94aef000)
libpango-1.0.so.0 => /usr/lib/x86_64-linux-gnu/libpango-1.0.so.0 (0x00007fae948aa000)
libfreetype.so.6 => /usr/lib/x86_64-linux-gnu/libfreetype.so.6 (0x00007fae945f5000)
libfontconfig.so.1 => /usr/lib/x86_64-linux-gnu/libfontconfig.so.1 (0x00007fae943b2000)
libgobject-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgobject-2.0.so.0 (0x00007fae9415e000)
libglib-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libglib-2.0.so.0 (0x00007fae93e48000)
libX11.so.6 => /usr/lib/x86_64-linux-gnu/libX11.so.6 (0x00007fae93b0a000)
libXi.so.6 => /usr/lib/x86_64-linux-gnu/libXi.so.6 (0x00007fae938fa000)
libnss3.so => /usr/lib/x86_64-linux-gnu/libnss3.so (0x00007fae935b1000)
libnssutil3.so => /usr/lib/x86_64-linux-gnu/libnssutil3.so (0x00007fae93381000)
libsmime3.so => /usr/lib/x86_64-linux-gnu/libsmime3.so (0x00007fae93154000)
libplc4.so => /usr/lib/x86_64-linux-gnu/libplc4.so (0x00007fae92f4f000)
libnspr4.so => /usr/lib/x86_64-linux-gnu/libnspr4.so (0x00007fae92d10000)
libgconf-2.so.4 => /usr/lib/x86_64-linux-gnu/libgconf-2.so.4 (0x00007fae92adf000)
libexpat.so.1 => /lib/x86_64-linux-gnu/libexpat.so.1 (0x00007fae928ad000)
libXext.so.6 => /usr/lib/x86_64-linux-gnu/libXext.so.6 (0x00007fae9269b000)
libXfixes.so.3 => /usr/lib/x86_64-linux-gnu/libXfixes.so.3 (0x00007fae92495000)
libXrender.so.1 => /usr/lib/x86_64-linux-gnu/libXrender.so.1 (0x00007fae9228b000)
libXcomposite.so.1 => /usr/lib/x86_64-linux-gnu/libXcomposite.so.1 (0x00007fae92088000)
libasound.so.2 => /usr/lib/x86_64-linux-gnu/libasound.so.2 (0x00007fae91d8a000)
libXdamage.so.1 => /usr/lib/x86_64-linux-gnu/libXdamage.so.1 (0x00007fae91b87000)
libXtst.so.6 => /usr/lib/x86_64-linux-gnu/libXtst.so.6 (0x00007fae91981000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fae91763000)
libcap.so.2 => /lib/x86_64-linux-gnu/libcap.so.2 (0x00007fae9155d000)
libudev.so.0 => not found
libdbus-1.so.3 => /lib/x86_64-linux-gnu/libdbus-1.so.3 (0x00007fae9130c000)
libnotify.so.4 => /usr/lib/x86_64-linux-gnu/libnotify.so.4 (0x00007fae91104000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007fae90d85000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007fae909f2000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007fae907db000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fae90421000)
/lib64/ld-linux-x86-64.so.2 (0x00007fae96166000)
libgmodule-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgmodule-2.0.so.0 (0x00007fae9021d000)
libgio-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgio-2.0.so.0 (0x00007fae8fe7f000)
libpangoft2-1.0.so.0 => /usr/lib/x86_64-linux-gnu/libpangoft2-1.0.so.0 (0x00007fae8fc6a000)
libfribidi.so.0 => /usr/lib/x86_64-linux-gnu/libfribidi.so.0 (0x00007fae8fa53000)
libXinerama.so.1 => /usr/lib/x86_64-linux-gnu/libXinerama.so.1 (0x00007fae8f850000)
libXrandr.so.2 => /usr/lib/x86_64-linux-gnu/libXrandr.so.2 (0x00007fae8f645000)
libXcursor.so.1 => /usr/lib/x86_64-linux-gnu/libXcursor.so.1 (0x00007fae8f43b000)
libpng16.so.16 => /usr/lib/x86_64-linux-gnu/libpng16.so.16 (0x00007fae8f208000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007fae8efea000)
libpixman-1.so.0 => /usr/lib/x86_64-linux-gnu/libpixman-1.so.0 (0x00007fae8ed44000)
libxcb-shm.so.0 => /usr/lib/x86_64-linux-gnu/libxcb-shm.so.0 (0x00007fae8eb41000)
libxcb.so.1 => /usr/lib/x86_64-linux-gnu/libxcb.so.1 (0x00007fae8e919000)
libxcb-render.so.0 => /usr/lib/x86_64-linux-gnu/libxcb-render.so.0 (0x00007fae8e70b000)
libthai.so.0 => /usr/lib/x86_64-linux-gnu/libthai.so.0 (0x00007fae8e501000)
libuuid.so.1 => /lib/x86_64-linux-gnu/libuuid.so.1 (0x00007fae8e2fa000)
libffi.so.6 => /usr/lib/x86_64-linux-gnu/libffi.so.6 (0x00007fae8e0f1000)
libpcre.so.3 => /lib/x86_64-linux-gnu/libpcre.so.3 (0x00007fae8de7f000)
libplds4.so => /usr/lib/x86_64-linux-gnu/libplds4.so (0x00007fae8dc7b000)
libgthread-2.0.so.0 => /usr/lib/x86_64-linux-gnu/libgthread-2.0.so.0 (0x00007fae8da79000)
libdbus-glib-1.so.2 => /usr/lib/x86_64-linux-gnu/libdbus-glib-1.so.2 (0x00007fae8d851000)
libsystemd.so.0 => /lib/x86_64-linux-gnu/libsystemd.so.0 (0x00007fae8d5c9000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007fae8d3a1000)
libresolv.so.2 => /lib/x86_64-linux-gnu/libresolv.so.2 (0x00007fae8d18a000)
libmount.so.1 => /lib/x86_64-linux-gnu/libmount.so.1 (0x00007fae8cf31000)
libharfbuzz.so.0 => /usr/lib/x86_64-linux-gnu/libharfbuzz.so.0 (0x00007fae8cc81000)
libXau.so.6 => /usr/lib/x86_64-linux-gnu/libXau.so.6 (0x00007fae8ca7d000)
libXdmcp.so.6 => /usr/lib/x86_64-linux-gnu/libXdmcp.so.6 (0x00007fae8c877000)
libdatrie.so.1 => /usr/lib/x86_64-linux-gnu/libdatrie.so.1 (0x00007fae8c66f000)
liblzma.so.5 => /lib/x86_64-linux-gnu/liblzma.so.5 (0x00007fae8c449000)
liblz4.so.1 => /usr/lib/x86_64-linux-gnu/liblz4.so.1 (0x00007fae8c22c000)
libgcrypt.so.20 => /lib/x86_64-linux-gnu/libgcrypt.so.20 (0x00007fae8bf10000)
libblkid.so.1 => /lib/x86_64-linux-gnu/libblkid.so.1 (0x00007fae8bcc1000)
libgraphite2.so.3 => /usr/lib/x86_64-linux-gnu/libgraphite2.so.3 (0x00007fae8ba94000)
libbsd.so.0 => /lib/x86_64-linux-gnu/libbsd.so.0 (0x00007fae8b87d000)
libgpg-error.so.0 => /lib/x86_64-linux-gnu/libgpg-error.so.0 (0x00007fae8b65d000)
As I am on my notebook with Debian 9 and on Debian / Ubuntus and other Linuxes udevd daemon and connected libraries are long time existing, it was obvious the problems to dependencies are because of missing library links (or library version inconsistencies).
To find out what kind of libudev.so* are present I used slocate package (locate) command.
noah:~# locate libudev.so
/lib/i386-linux-gnu/libudev.so.1
/lib/i386-linux-gnu/libudev.so.1.6.10
/lib/x86_64-linux-gnu/libudev.so
/lib/x86_64-linux-gnu/libudev.so.1
/lib/x86_64-linux-gnu/libudev.so.1.6.10
Obviously the missing library libudev.so.0 was present under a different name so I give a try to just create a new symbolic link from libudev.so.1 to libudev.so.0 hoping that the libudev library version Blue Jeans was compiled against did not have a missing binary objects from the ones installed on my OS.
noah:~# ln -sf /lib/x86_64-linux-gnu/libudev.so.1 /lib/x86_64-linux-gnu/libudev.so.0
noah:~# ldd /opt/bluejeans/bluejeans-bin |grep -i 'not found'
Above command did not return any missing libraries, so I went further and executed it.
6. Go start BlueJeans and register a user or use the anonymous login to be ready for the scheduled online meting
… And, Guess, what it works! 🙂
noah:~# /opt/bluejeans/bluejeans-bin
To make it easy to remember to later start the binary under a familiar name, I've also created a link into
noah:~# ln -sf /opt/bluejeans/bluejeans-bin /usr/bin/bluejeans
noah:~# sudo su – hipo
hipo@noah:~$ /usr/bin/bluejeans
Tags: command, convertion, How to, installed, libc, linuxes, noah, platforms, rpm, slavery, Web Meeting Online Rooms Platform
Posted in Company onboarding basics, File Convert Tools, Linux, Linux and FreeBSD Desktop, Various | No Comments »
Friday, April 8th, 2011 I needed to convert a bunch of files from WAV to MP3 format on my Linux desktop.
I’ve placed all my wav files to the directory /home/hipo/wav
And then I issued the small one liner script to convert the .wav files to .mp3 using the niftly lame linux mp3 convertor.
Here is how I did it:
linux-desktop:~$ cd wav
linux-desktop:/home/hipo/wav$ for i in *.wav; do
new_name=$(echo $i |sed -e 's#wav#mp3#g');
lame -V0 -h -b 160 --vbr-new "$i" "$new_name";
done
After executing the little script you might go and have a coffee, if you have thousands of files, each file convertion takes about 10-15 seconds of time (speed depends on your CPU).
Here is some output from a lame convertion to mp3 taking place:
Encoding as 8 kHz single-ch MPEG-2.5 Layer III VBR(q=0)
Frame | CPU time/estim | REAL time/estim | play/CPU | ETA
27237/27237 (100%)| 0:12/ 0:12| 0:12/ 0:12| 155.89x| 0:00
64 [27237] ***************************************************************
----------------------------------------------
kbps mono % long switch short %
64.0 100.0 84.1 8.9 7.0
If you want to save my convertion quickly for a later, download my Convert WAV to mp3 from a directory with lame shell script here
Actually there are plenty of other ways to convert wav to mp3 on Linux through mplayer, ffmpeg even with mpg123.
There are also some GUI programs that could do the convertion like winff , however for some weird reason after installing WinFF on my debian it was not able to complete convertion to mp3?!
But it doesn’t matter, the good news is I did what I wanted to via the simple lame program and the above script, hope it helps somebody out there.
Tags: coffee, Convert, convertion, convertor, cpu time, Desktop, desktop cd, download, estim, eta, ffmpeg, file, format, Frame, gui programs, hipo, linux desktop, linux mp3, mpg, mpg123, place, real time, reason, script, Shell, shell script, time, time speed, v0, VBR, WAV, wav files, wav mp3, weird reason, WinFF
Posted in Linux and FreeBSD Desktop, Linux Audio & Video | 8 Comments »
Wednesday, January 9th, 2013

Some time ago I've written a tiny article, explaining how converting of HTML or TEXT file content inside file can be converted with iconv.
Just recently, I've made mirror of a whole website with its directory structure with wget cmd. The website to be mirrored was encoded with charset Windows-1251 (which is now a bit obsolete and not very recommended to use), where my Apache Webserver to which I mirrored is configured by default to deliver file content (.html, txt, js, css …) in newer and more standard (universal cyrillic) compliant UTF-8 encoding. Thus opening in browser from my website, the website was delivered in UTF-8, whether the file content itself was with encoding Windows CP-1251; Thus I ended up seeing a lot of monkey unreadable characters instead of Slavonic letters. To deal with the inconvenience, I've used one liner script that converts all Windows-1251 charset files to UTF-8. This triggered me writting this little post, hoping the info might be useful to others in a similar situation to mine:
1. Make Mass file charset / encoding convertion with recode
On most Linux hosts, recode is probably not installed. If you're on Debian / Ubuntu Linux install it with apt;
apt-get install --yes recode
It is also installable from default repositories on Fedora, RHEL, CentOS with:
yum -y install recode
Here is recode description taken from man page:
NAME
recode – converts files between character sets
find . -name "*.html" -exec recode WINDOWS-1251..UTF-8 {} \;
If you have few file extensions whose chracter encoding needs to be converted lets say .html, .htm and .php use cmd:
find . -name "*.html" -o -name '*.htm' -o -name '*.php' -exec recode WINDOWS-1251..UTF-8 {} \;
Btw I just recently learned how one can look for few, file extensions with find under one liner the argument to pass is -o -name '*.file-extension', as you can see from example, you can look for as many different file extensions as you like with one find search command.
After completing the convertion, I've remembered that earlier I've also used iconv on a couple of occasions to convert from Cyrillic CP-1251 to Cyrillic UTF-8, thus for those who prefer to complete convertion with iconv here is an alternative a bit longer method using for cycle + mv and iconv.
2. Mass file convertion with iconv
for i in $(find . -name "*.html" -print); do
iconv -f WINDOWS-1251 -t UTF-8 $i > $i.utf-8;
mv $i $i.bak;
mv $i.utf-8 $i;
done
As you see in above line of code, there are two occurances of move command as one is backupping all .html files and second mv overwrites with files with converted encoding. For any other files different from .html, just change in cmd find . -iname '*.html' to whatever file extension.
Tags: CentOS, character sets, convertion, converts, exec, file extensions, inconvenience, linux hosts, man page, page 3a, repositories, rhel, tiny article, unicode utf 8
Posted in Everyday Life, Linux, System Administration, Web and CMS | 3 Comments »
Tuesday, November 13th, 2012 
On Linux, there are plenty of ways nowadays to convert Microsoft Word or OpenOffice .DOC documents to Adobe's PDF (Postscript). However most of the ways require a graphical environment. As I'm interested in how convertion is done mainly from console to suit shell scripts and php which has to routinely convert a bunch of .DOC files to .PDF. I've checked today how PDF to DOC is possible on Debian, Ubuntu, Arch Linux and FreeBSD..
There are few tools one can use from console, that doesn't requiere you to have running Xorg on the convertion host. The quality of the produced converted document, may vary and with some Microsoft Office doc files, there might be some garbage. But generally for simplistic and well written "macros" free documents the quality of PDF is satisfactory with few of the tools.
Here I will list the few tools, one can use for convertion:
- abiword – you probably know abiword GUI program which is a good substitute for people who doesn't want the huge openoffice on the host. interestingly abiword supports converts with no need for GUI
- wvPDF (you have to have install wv package and usually this converter works well only with very old .DOC (MS Office 97) – I was not impressed with those convert results
- oowriter / swriter (whether LibreOffice installed) or writer (on LibreOffice), on some Ubuntus and derivatives the equivalent cmd is lowriter
- unoconv – this tool produces really good DOC to PDF converts, it is a python script using openoffice / libreoffice as backend convertion engine so produced PDFs will be identical like the ones produced with oowriter, the pros of the tool is its syntax is very user friendly and along with PDF to DOC it supports easy syntax converting to bunch of other file formats. Actually unoconv supports same convertions which supported by OpenOffice.org, the advantage is however you can use it within console and even schedule convertion to be processed by a remote host.
1. Convertion of DOC to PDF with abiword
abiword --to=pdf doc_file_to_convert.doc
2. Convert DOC to PDF with wvPDF
apt-get install --yes wv texlive-base texlive-latex-base ghostscript
wvPDF doc-file-to-convert-to-pdf.doc converted-to-pdf.pdf
wvPDF doc-file-to-convert-to-pdf.doc convert-to-pdf.pdf
Current directory: /home/hipo/Desktop
"doc-file-to-convert-to-pdf.eps" exists - skipping...
Some problem running latex.
Check for Errors in steinway.log
Continuing...
The produced .pdf was not useful most of the text inside was completely missing as well as some weird probably PostScript convertion characters were in the .PDF. Seeing its output I would as of time of writing wvPDF Debian's verion 1.2.4 is crap.
3. Convert DOC to PDF with oowriter / swriter / lowrite
a) convert with oowriter and swriter
I saw posts online claiming DOC to PDF convertion is possible directly with oowriter or swriters with commands:
oowriter -convert-to pdf:writer_pdf_Export input-doc-file-to-convert.doc
or
swriter -convert-to pdf:writer_pdf_Export steinway.doc - as named on some Linux-es
As long as I tested it on my Debian Squeeze, neither of the two works
.I saw some suggestions that PDF can be generated by installing and using cups-pdf debian package:
apt-get install cups-pdf
oowriter -pt pdf your_word_file.doc
b) convert DOC to PDF with lowriter I've seen in Ubuntu documentation and in Ubuntu forums, users saying they had some good results using lowriter, which is a sort of front-end program to ImageMagick's convert. I never tested that but I doubt of any satisfactory results, as I tried converting to PDF earlier using convert and often converts failed. Anyways you try it with:
lowriter --convert-to pdf *.doc
4. Converting PDF to DOC with unoconv
As of time of writing it seems unoconv is best Linux console tool for converting .doc to .pdf
It produces good readable text, as well as pictures and elements looks exactly as in OpenOffice.
To install it I run:
# apt-get install --yes unoconv
....
To use it:
$ unoconv -fpdf any-file-to-convert.doc
If you don't get errors or it doesn't crash a .doc file with same name any-file-to-convert.doc is created.
What unoconv, does is precisely the same as if using OpenOffice
GUI's to convert to PDF:
- Open -> Open Office (3.2 in my case)
- Open Document to export
- File->Export as PDF
- Click: Export
- Choose file namefor output PDF
An interesting feature of unoconv is its possibility to run and convert as a port listening server. I never used this but noticed it mentioned in manual EXAMPLE section:
EXAMPLES
You can use unoconv in standalone mode, this means that in absence of an OpenOffice listener, it will starts its own:
unoconv -f pdf some-document.odt
One can use unoconv as a listener (by default localhost:2002) to let other unoconv instances connect to it:
unoconv --listener &
unoconv -f pdf some-document.odt
unoconv -f doc other-document.odt
unoconv -f jpg some-image.png
unoconv -f xsl some-spreadsheet.csv
kill -15 %-
This also works on a remote host:
unoconv --listener --server 1.2.3.4 --port 4567
and then connect another system to convert documents:
unoconv --server 1.2.3.4 --port 4567
unoconv does not recognize wildcards like ' * ' , so in order to convert multiple DOC to PDF files one has to use the usual shell loop:
for i in *.doc; do unoconv -fpdf $i; done
From all my tests, I think unoconv is preferred tool for Linux and BSD users (good time to mention unoconv is available on FreeBSD too. BSD users can install it via port /usr/ports/textproc/unoconv)
Tags: console, Convert, convertion, inside, Linux, using
Posted in Linux and FreeBSD Desktop, Linux Audio & Video, System Administration, Various | No Comments »
Friday, May 18th, 2012 A friend of mine, just mentioned about a program ASCIIPic – capable of converting graphic images in JPEG to plain text ASCII in Microsoft Windows OSes.
Yesterday I blogged about caca-utils (img2txt) – console tool to convert picture graphics to plain text ASCII , so knowing of the Windows freeware ASCIIPic existence catched my attention and I decided to give it a try to get idea what is situation with Images to ASCII text convertion in Windows? 🙂.
1. Generating ASCII from JPEG images with ASCII Pic
As I don't have a Microsoft Windows OS at hand, I downloaded it and run it on my Debian notebook with WINE (Wine Is Not an Emulator) MS-Windows emulator.
For my surprise the program run succesfuly its GUI interface and worked pretty smooth even emulated on Linux.
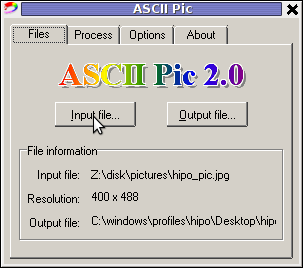
As of time of writting, the latest version of the freeware program available is 2.0. You see in above screenshot the program is pretty intutive to use. You select an Input file, an Output file and you're ready to Process the image to TXT.
One small note to make here is the program couldn't recognize as Input files images in PNG or GIF formats, it seems the only image formats the program recognizes as input are JPEG and BMP.
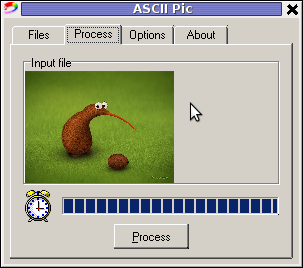
The converted images to ASCII results are quite unsatisfactory, I tried converting few pictures originally in size 1024×768 but the produced ASCII was messy huge (the program didn't automatically set height / width dimensions to 60×80 and therefore, when I revied the produced pictures, they were very ugly and hardly readable. It could be the same image looks better if reviewed in MS-Windows Notepad but I seriously doubt that …
I thought some improvement to the produced ASCII image might be possible from the app options so I played around with the Zoom, Negation, Brightness and Monochrome options, none of them had a drastic change on the output. Using any of the program options didn't make the output TXT "image" to look closer riginal JPEGs..
ASCII Pic official website contains a number of other tiny tools, like WinKill and RemoteShut, however most of the tools are already too obslete and useless just like ASCII Pic
If I have to compare ASCIIPic produced ASCII Images to libcaca's Linux img2txt, asciipic's ASCII images are a piece of crap.
2. jp2a command line tool image to ASCII generator
As of time of writting a good alternative program I found for Windows is jp2a
jp2a is a free GPL-ed software available for all major operating system architectures Linux, BSD, Mac OS X, Windows.
jp2a is a command line tool and lacks any GUI interface but if compared to ASCII Pic the output ASCII image is awesome.
jp2a Windows binary can be downloaded from here , also I've made a mirror of windows jp2a bin in case if it disappears here
3. ASCII Generator 2 (asc2gen) – Windows GUI Images to ASCII generator
ASC 2 Gen is actually the best I can find program to convert images to ascii in Win as of time of writting.
Just like img2txt it generates pretty decent looking text images.
ASC2Gen failed to run emulated on my Linux host with wine version 1.0.1, hence to test it I used a a Windows host via teamviewer.
Below are few screenshots illustrating most of the options ASCII2GEN provides:
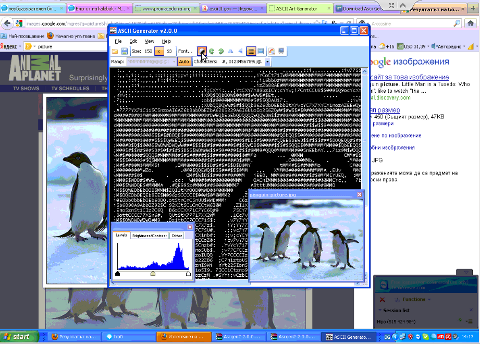
asc2gen penguins in inverted color set (black color text background)
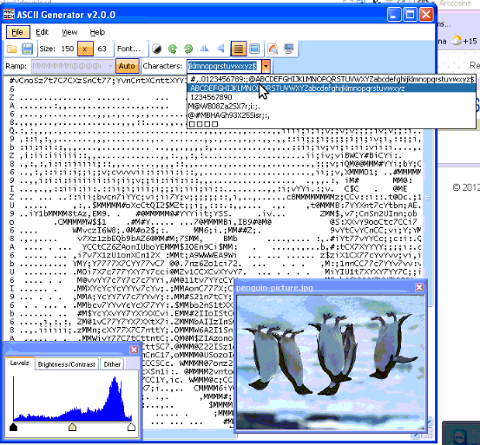
ASC2GEN flipped backhed generated image to ASCII
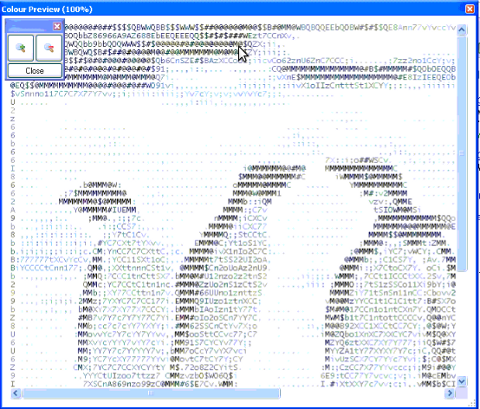
Picture to ASCII text converted with ASCII colors
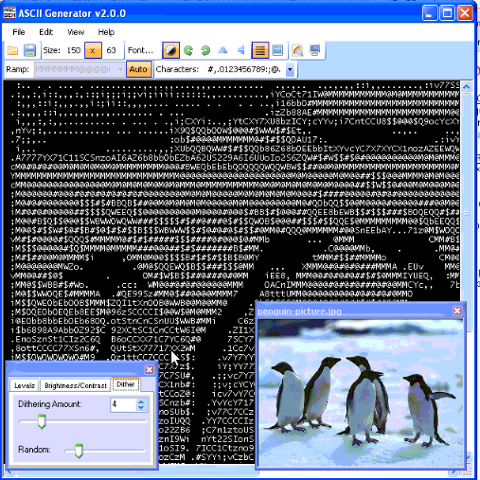
ascii2gen dithering level option shot
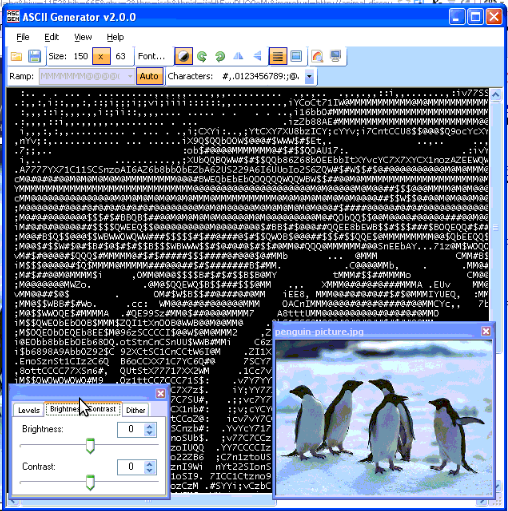
asc2gen contrast / brigthness atune shot
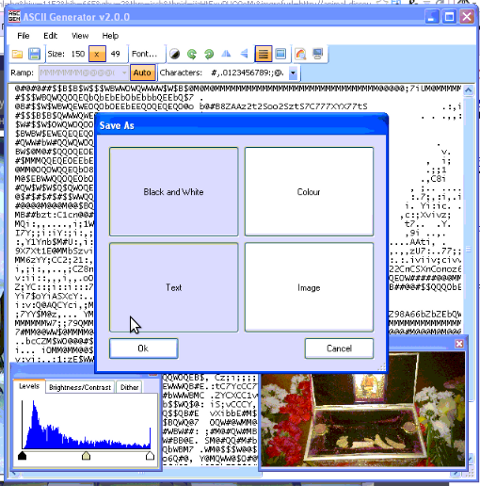
asc2gen save as options shot
Something else nice is it supports a lot of image file formats as input including (BMP and GIF) images.
I've also made a mirror of asc2gen v. 2.0.0 here
While researching online, I found plenty of other Image to ASCII geneartors, however as I didn't tested them I can't say if they are better ones.
Anyways I will be happy to hear if anyone knows other good ASCII generator alternative progs for Winblows?
Tags: ascii art, ascii image, ascii text, Auto, convertion, Draft, drastic change, emulator, existence, file, freeware, freeware program, GIF, gif formats, graphic images, gui interface, host, Image, image formats, images, img, input files, jpeg images, Microsoft, microsoft windows 2000, microsoft windows os, ms windows notepad, negation, Output, Pic, PicAs, picture, png, process, program options, quot, screenshot, shot, shotasc, text, text ascii, time, tool, width dimensions, wine, wine wine
Posted in Entertainment, Everyday Life, Various, Windows | 4 Comments »
Tuesday, May 8th, 2012 I'm starting to learn some video editing, as I need it sometimes for building client websites.
As a Linux user I needed to have some kind of software for amateur video editing.
For Microsoft Windows OS, there are tons of video editor programs both free and proprietary (paid).
Windows users can for instance use the free software program VirtualDub (licensed under GPL license) to easily cut movie scenes from a video.
Unfortunately VirtualDub didn't have a Linux or BSD version so in my case I had to look for another soft.
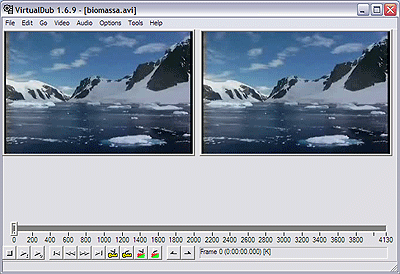
I consulted a friend of mine who recommended a video editor program called LiVES.
If you haven't done any video editing previously on Linux (like my case was), you will certainly be happy to try LiVES

LiVES can extract only sound from videos, cut selected parts (frames) from videos and do plenty of other nice stuff. It is just great piece of software for anyone, who needs to do simply (newbie) video editting.
With LiVES even an amateur video editor like me could, immediately learn how to chop a movie scenes …
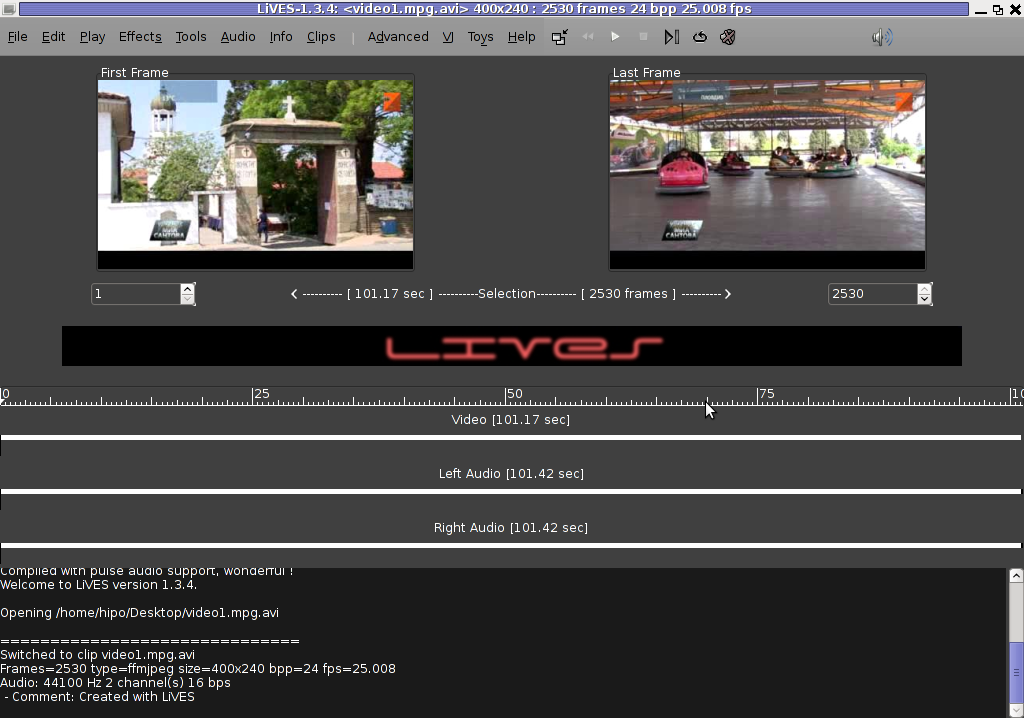
To master the basics and edit one video in FLV format it took me about 1 hour of time, as in the beginning it was confusing to get confortable with the program scenes selector.
One downside of LiVES it failure to open a FLV file I wanted to edit.
In order to be able to edit the flv movie hence I first had to convert the FLV to AVI or MPEG, as this two (video multimedia formats) are supported by LiVES video editor.
After completing my video scenes chopping to the AVI file I had to convert back to FLV.
In order to complete the convertion between FLV to AVI format on my Debian Linux, I used a program called avidemux
Avidemux has a nice GUI interface and also like Lives has support for video editting, though I have never succesfully done any video edits with it.
Avidemux IMHO is user (completely intuitive). To convert the FLV to AVI, all I had to do was simply open the file FLV file, press (CTRL+S) select my FLV video file format and select the output file extension format to be AVI.
Further on, used LiVES to cut my desired parts from my video of choice. Once the cuts were complete I saved the new cutted version of video to AVI.
Then I needed the video again in FLV to upload it in Joomla, so used ffmpeg – command line tool to do the AVI to FLV file converstion, like so:
hipo@noah:~$ /usr/bin/ffmpeg -i my_media_file.avi my_video_file.flv
Hope this article helps someone aiming to do basic video editting on Linux with LiVES and just like needed FLV to AVI and AVI to FLV convertions.
Tags: Auto, avi, avi file, avi format, avidemux, BSD, client, client websites, convertion, debian linux, downside, Draft, editing, editor, failure, file, flv file, format, free software program, gui interface, how to convert flv to avi, IMHO, instance, Linux, linux user, Microsoft, microsoft windows os, multimedia formats, nice stuff, piece, selector, simple, software, support, time, video, video editing, video editor, video editting, video multimedia, video scenes, Videos, windows users
Posted in Entertainment, Everyday Life, Linux and FreeBSD Desktop | No Comments »
Sunday, February 26th, 2012 In my last article, I've explained How to create PNG, JPG, GIF pictures from one single PDF document
Convertion of PDF to images is useful, however as PNG and JPEG graphic formats are raster graphics the image quality gets crappy if the picture is zoomed to lets say 300%.
This means convertion to PNG / GIF etc. is not a good practice especially if image quality is targetted.
I myself am not a quality freak but it was interesting to find out if it is possible to convert the PDF pages to SVG (Scalable Vector Graphics) graphics format.
Converting PDF to SVG is very easy as for GNU / Linux there is a command line tool called pdf2svg
pdf2svg's official page is here
The traditional source way compile and install is described on the homepage. For Debian users pdf2svg has already existing a deb package.
To install pdf2svg on Debian use:
debian:~# apt-get install --yes pdf2svg
...
Once installed usage of pdf2svg to convert PDF to multiple SVG files is analogous to imagemagick's convert .
To convert the 44 pages Projects.pdf to multiple SVG pages – (each PDF page to a separate SVG file) issue:
debian:~/project-pdf-to-images$ for i in $(seq 1 44); do \
pdf2svg Projects.pdf Projects-$i.SVG $i; \
done
This little loop tells each page number from the 44 PDF document to be stored in separate SVG vector graphics file:
debian:~/project-pdf-to-images$ ls -1 *.svg|wc -l
44
For BSD users and in particular FreeBSD ones png2svg has a bsd port in:
/usr/ports/graphics/pdf2svg
Installing on BSD is possible directly via the port and convertion of PDF to SVG on FreeBSD, should be working in the same manner. The only requirement is that bash shell is used for the above little bash loop, as by default FreeBSD runs the csh.
On FreeBSD launch /usr/local/bin/bash, before following the Linux instructions if you're not already in bash.
Now the output SVG files are perfect for editting with Inkscape or Scribus and the picture quality is way superior to old rasterized (JPEG, PNG) images
Tags: Auto, bash shell, bsd users, command line tool, Convert, Converting, convertion, crappy, deb, deb package, debian project, debian users, document, documentConvertion, Draft, editting, format, freak, GIF, gnu linux, graphic formats, Graphics, graphics format, graphics graphics, homepage, Image, image quality, ImageMagick, inkscape, issue, JPG, jpg gif, line, Linux, nbsp, number, package, page, pdf document, picture, png, png images, Projects, raster graphics, rasterized, Scalable, scalable vector graphics, Scribus, Shell, svg file, svg files, tool, traditional source, use, vector, way
Posted in Linux, Linux and FreeBSD Desktop, System Administration | No Comments »
Saturday, February 25th, 2012 I've received a PDF file with a plan for development of a bundle of projects, My task was to evaluate this plan and give feeback on the 44 pages PDF document.
Since don't know of program to directly be able edit PDF files on GNU / Linux ?, my initial idea was to open and convert the PDF to ODT / DOC with OpenOffice (Libre Office) and then edit the ODT file.
Unfortunately Open Office oowrite program was unable to open / visualize the PDF file. My assumption is OO failure to open the PDF is because the PDF was generated on Microsoft Windows with Adobe illustrator or smth.
The idea that came to my mind as alternative, way to edit the PDF file was to convert it in pictures edit and then convert the pictures to PDF.
In other words to follow these 3 steps:
1. Convert the PDF document to multiple images
2. Edit each of the images with GIMP or Inkscape
3. Convert back all images to a single PDF file
Some time ago, I've written an article how to create PDF file from many image files in JPEG, PNG or GIF on Linux
. This prior article was exactly describing how to complete Step 3.Therefore all left was to find a way to convert the PDF file to multiple JPEG / PNG / GIF images.
convert command to convert PDF document to multiple pictures which you can take from my earlier article is:
$ convert *.jpg outputpdffile.pdf
Actually in Step 1 I was aiming to do the opposite of what I've previously done.
Hence, in order to convert the singe Project.PDF file to multiple PNG images, I just switched convert IN / OUT arguments order.
hipo@noah:~/project-pdf-to-images$ convert Project.pdf Project.png
...
I've done the PDF to pictures conversion on my notebook running Debian Squeeze (6.0.2) GNU / Linux.Convertion of the PDF file to 44 images, took 25 seconds on my dual core 1.8 Ghz / 2GB RAM Thinkpad r61.
Afterwards, I've had at hand 44 PNG files generated, e.g.:
hipo@noah:~/project-pdf-to-images$ ls -al Project-*.png |wc -l
44
convert was also smart enough to produce correct file naming. The output file names were:
Project-1.png
Project-2.png
etc.
Nicely each number (-1.png) was corresponding to the respective PDF page. For instance Project-10.png was corresponding to page 10 of the Projects.PDF file
Rather ironically, after convertion of the PDF to pictures, while opening the Project-1.png, I've noticed The GIMP – (The GNU Image Manipulation Program) is capable of directly reading PDF files. GIMP has both the option to open files in layers or separate images 😉
Anyways even if GIMP is used to modify the different PDF pages as layers, once completed GIMP doesn't have the ability to save the file as PDF and therefore once saved the file if merging of layers is done the resulting picture becomes ONE BIG MESS.
Therefore it seems my the 3 steps way e.g.:
1. convertion PDF to pictures
2. picture edit with GIMP or Inkscape
3. convertion of pictures back to PDF
is still the only way to "modify PDF" in Linux or BSDs. I will be glad to hear if someone has come up with a better solution?
Tags: adobe illustrator, alternative, assumption, Auto, bundle, conversion, Convert, convertion, DOC, Draft, dual core, file, GIF, gif images, GIMP, hipo, how to create pdf file, illustrator, image files, initial idea, JPG, jpg gif, Libre, microsoft windows, multiple images, noah, noah project, odt, Open, open office, OpenOffice, page, pdf files, png, png files, png images, RAM, singe, smth, step 1, step 3, time
Posted in FreeBSD, Linux, System Administration | 3 Comments »
Tuesday, September 14th, 2010 I’ve recently received a number of images in JPEG format as a feedback on a project plan that was constructed by a team I’m participating at the university where I study.
Somebody from my project group has scanned or taken snapshots of each of the hard copy paper feedback and has sent it to my mail.
I’ve received 13 images so I had to open them one by one to get each of the Project Plan to read the feedback on the page this was really unhandy, so I decided to give it a try on how to generate a common PDF file from all my picture files.
Thanksfully it happened to be very easy and trivial using the good old Image Magick
In order to complete the task of generating one PDF from a number of pictures all I did was.1. Switch to the directory where I have saved all my jpeg images
debian:~# cd /home/hipo/Desktop/my_images_directory/
2. Use the convert binary part of imagemagick package to generate the actual PDF file from the group of images
debian:~# convert *.jpg outputpdffile.pdf
If the images are numbered and contain many scanned pages of course you can always pass by all the images to the /usr/bin/convert binary, like for instance:
debian:~# convert 1.jpg 2.jpg 3.jpg 4.jpg 5.jpg outputpdffile.pdf
Even though in my case I had to convert to PDF from multiple JPEG (JPG) pictures, convertion with convert is not restricted to convert only from JPEG, but you can also convert to PDF by using other graphical file formats.
For instance to convert multiple PNG pictures to a single PDF file the command will be absolutely the same except you change the file extension of the graphic files e.g.:
debian:~# convert 1.PNG 2.PNG 3.PNG 4.PNG 5.PNG OUTPUT-PDF-FILE.PDF
I was quite happy eventually to know Linux is so flexible and such a trivial things are able to be completed in such an easy way.
Tags: cd home, convertion, copy, course, Create PDF file from (jpg) pictures in Linux, Desktop, feedback, file, file extension, file formats, format, gif images, graphic files, hipo, home, Image, image magick, ImageMagick, images directory, instance, JPEG, jpeg images, jpg gif, Linux, Magick, mail, number, order, OUTPUT-PDF-FILE, outputpdffile, package, page, Paper, picture, png, project, project group, snapshots, somebody, switch, team, Thanksfully, trivial things, unhandy, usr, usr bin, way
Posted in Linux, Linux and FreeBSD Desktop, Various | 5 Comments »
Thursday, December 8th, 2011 
I’m realizing the more I’m converting to a fully functional GUI user, the less I’m doing coding or any interesting stuff…
I remembered of the old glorious times, when I was full time console user and got a memory on a nifty trick I was so used to back in the day.
Back then I was quite often writing shell scripts which were fetching (html) webpages and converting the html content into a plain TEXT (TXT) files
In order to fetch a page back in the days I used lynx – (a very simple UNIX text browser, which by the way lacks support for any CSS or Javascipt) in combination with html2text – (an advanced HTML-to-text converter).
Let’s say I wanted to fetch a my personal home page https://www.pc-freak.net/, I did that via the command:
$ lynx -source https://www.pc-freak.net/ | html2text > pcfreak_page.txt
The content from www.pc-freak.net got spit by lynx as an html source and passed html2pdf wchich saves it in plain text file pcfreak_page.txt
The bit more advanced elinks – (lynx-like alternative character mode WWW browser) provides better support for HTML and even some CSS and Javascript so to properly save the content of many pages in plain html file its better to use it instead of lynx, the way to produce .txt using elinks files is identical, e.g.:
$ elinks -source https://www.pc-freak.net/blog/ | html2text > pcfreak_blog_page.txt
By the way back in the days I was used more to links , than the superior elinks , nowdays I have both of the text browsers installed and testing to fetch an html like in the upper example and pipe to html2text produced garbaged output.
Here is the time to tell its not even necessery to have a text browser installed in order to fetch a webpage and convert it to a plain text TXT!. wget file downloading tools supports source dump as well, for all those who did not (yet) tried it and want to test it:
$ wget -qO- https://www.pc-freak.net | html2text
Anyways of course, some pages convertion of text inside HTML tags would not properly get saved with neither lynx or elinks cause some texts might be embedded in some elinks or lynx unsupported CSS or JavaScript. In those cases the GUI browser is useful. You can use any browser like Firefox, Epiphany or Opera ‘s File -> Save As (Text Files) embedded functionality, below is a screenshot showing an html page which I’m about to save as a plain Text File in Mozilla Firefox:
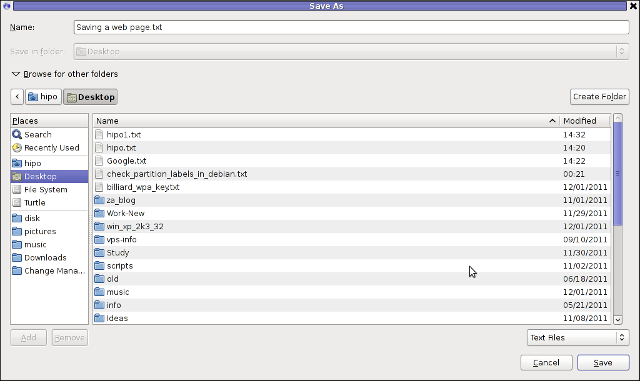
Besides being handy in conjunction with text browsers, html2text is also handy for converting .html pages already existing on the computer’s hard drive to a plain (.TXT) text format.
One might wonder, why would ever one would like to do that?? Well I personally prefer reading plain text documents instead of htmls 😉
Converting an html files already existing on hard drive with html2text is done with cmd:
$ html2text index.html >index.txt
To convert a whole directory full of .html (documentation) or whatever files to plain text .TXT , cd the directory with HTMLs and issue the one liner bash loop command:
$ cd html/
html$ for i in $(echo *.html); do html2text $i > $(echo $i | sed -e 's#.html#.txt#g'); done
Now lay off your back and enjoy reading the dox like in the good old hacker days when .TXT files were fashionable 😉
Tags: advanced html, character mode, command lynx, content, convertion, course, CSS, drive, file, freak, full time, glorious times, gnu linux, html pages, html source, HTML-to-text, html2text, index, interesting stuff, javascipt, Javascript, Lynx, necessery, nifty trick, page, page txt, pcfreak, PDF, personal home page, Shell, shell scripts, spit, support, terminal, text, text browser, text converter, time, trick, TXT, unix text, wget
Posted in Everyday Life, FreeBSD, Linux, Linux and FreeBSD Desktop, Various | 1 Comment »




