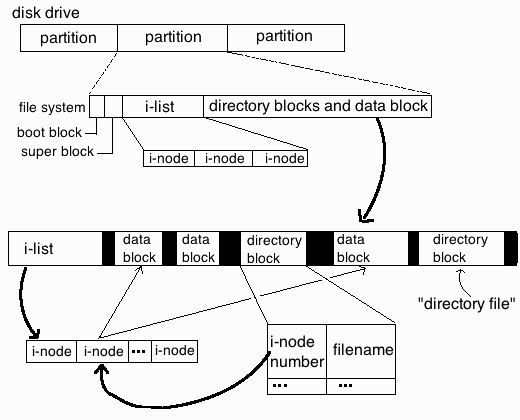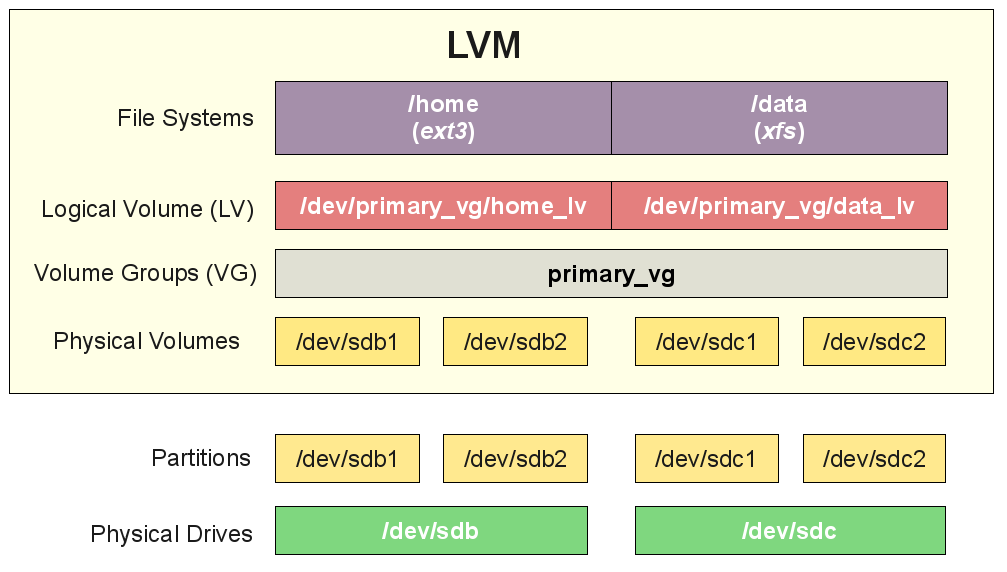
Lets say you have to resize a partition that is wrongly made by some kind of automation like ansible or puppet,
because the Linux RHEL family OS template was prepared with a /home (or other partition with some very small size) on VMware Vsphere Hypervisor hosting the Guest linux VM and the partition got quickly out of space.
To resolve the following question comes for the sysadmin
I. How to extend the LVM parititon that run out of space (without rebooting the VM Guest Linux Host)
II. how to add new disk partition space to the vSphere hypervisor OS.
In below article i'll shortly describe that trivials steps to take to achieve that. Article won't show anything new original but I wrote it,
because I want it to have it logged for myself in case I need to LVM extend the space of my own Virtual machines and
cause hopefully that might be of help to someone else from the Linux community that has to complete the same task.
I . Extending a LVM parititon that run out of space on a Linux Guest VM
1. Check the current parititon size that you want to extend
[root@linux-hostname home]# df -h /home/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg00-home
4.7G 4.5G 0 100% /home
2. Check the Virtualization platform
[root@vm-hostname ~]# lshw |head -3
linux-hostname
description: Computer
product: VMware Virtual Platform
3. Check the Operating System Linux OS type and version
In this specific case this is a bit old Redhat -like CentOS 6.9 Linux
[root@vmware-host ~]# cat /etc/*release*
CentOS release 6.9 (Final)
CentOS release 6.9 (Final)
CentOS release 6.9 (Final)
cpe:/o:centos:linux:6:GA
4. Find out the type of target filesystem is EXT3, EXT4 or XFS etc.?
[root@vm-hostname ~]# grep home /proc/mounts
/dev/mapper/vg00-home /home ext3 rw,relatime,errors=continue,user_xattr,acl,barrier=1,data=ordered 0 0
Filesystem is handled by LVM thus
5. Check the size of the LVM partition we want to exchange
[root@vm-hostname ~]# lvs |grep home
home vg00 -wi-ao—- 5.00g
6. Check whether free space is available space in the volume group ?
[root@vm-hostname ~]# vgdisplay vg00
— Volume group —
VG Name vg00
System ID
Format lvm2
Metadata Areas 2
Metadata Sequence No 15
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 10
Open LV 10
Max PV 0
Cur PV 2
Act PV 2
VG Size 128.99 GiB
PE Size 4.00 MiB
Total PE 33022
Alloc PE / Size 30976 / 121.00 GiB
Free PE / Size 2046 / 7.99 GiB
VG UUID 1F89PB-nIP2-7Hgu-zEVR-5H0R-7GdB-Lfj7t4
Extend VMWare space configured for additional hard disk on Hypervisor (if necessery)
In order for to extend the LVM of course you need to have a pre-existing additional hard-drive on VM (sdb,sdc etc. attached )
– If you need to extend on Vmware Vsphere Hypervisor:
Extend additional harddrive by entering the new size and Validate.
If you have previously extended the size of the Virtual Disk from VMWare to make the Linux guest vm find out about the change
you have to rerun rescan for the respective device that was grown on the HV.
7. Rescan on Linux VM host for changes in disk size from Hypervisor
Rescan disk for new size :
[root@vm-hostname ~]# echo 1> /sys/block/sdX/device/rescan
(where sdX is the extended additional harddrive)
8. Resize LVM physical volume
[root@vm-hostname ~]# pvresize /dev/sdX
9. Enlarge Logical Volume size
[root@vm-hostname ~]# lvextend -L+5G /dev/mapper/vg00-home
Extending logical volume LogVol00 to 10.77 GiB
Logical volume LogVol00 successfully resized
10. Enlarge LVM hosted filesystem size
Filesystem is ext3 or ext4 :
[root@vm-hostname ~]# resize2fs /dev/mapper/vg00-home
– If the filesystem is not ext3 / ext4 but XFS you have to use xfs_growfs to let the FS know about the change.
Filesystem is XFS :
[root@vm-hostname ~]# xfs_growfs /dev/mapper/vg00-home
11. Check the additional filespace is already active on the Linux Guest VM
[root@vm-hostname ~]# df -h /home/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_cloud-LogVol00
10G 4.2G 4.9G 48% /home
12. Verify the extension of filesystem completed without errors
Check of system log:
[root@vm-hostname ~]# grep -i error /var/log/messages
…
Check if filesystem is writable.
[root@vm-hostname ~]# touch /home/test
[root@vm-hostname ~]# ls -al /home/test
-rw-r—– 1 root root 0 Sep 20 13:39 /home/test
[root@vm-hostname ~]# rm -f /home/test
II. How to add additional sdb drive to a Linux host from vSPhere HV lets say (sdb)
1. On VSphere GUI interface
-> Select New hard drive and click Add
Enter the desired size for the new disk then unpack the disk parameters to choose Thin provision. Validate and Apply the recommendations.
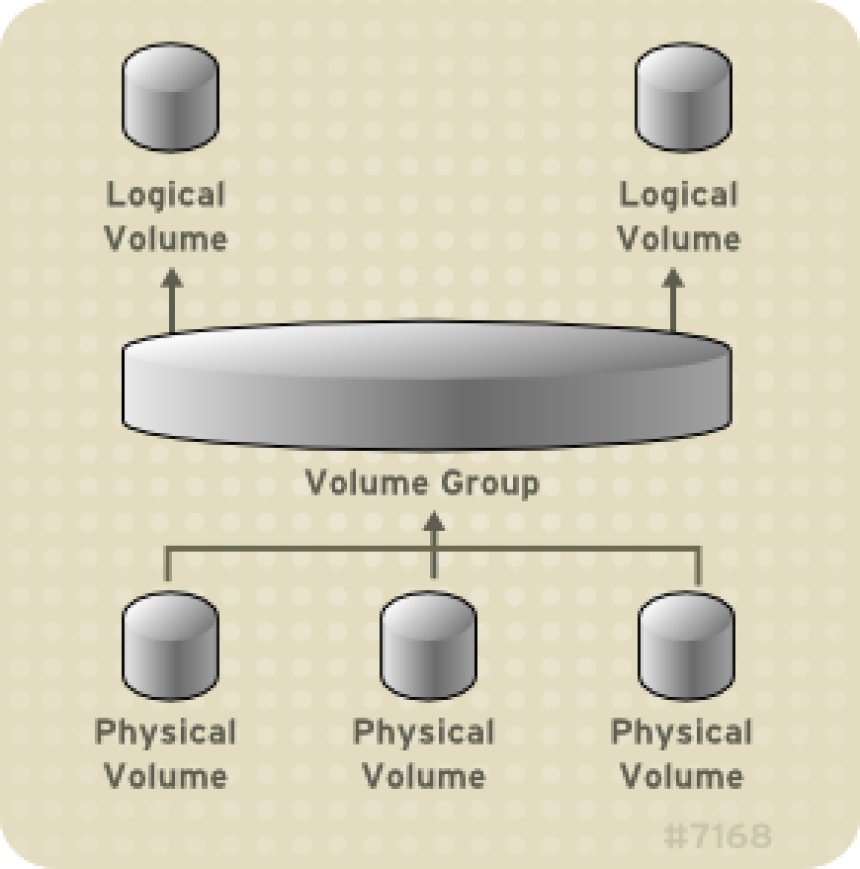
2. On Linux system VM guest host to detect the new added sdb available space
Discover new disk :
[root@vm-hostname ~]# echo "- – -"> /sys/class/scsi_host/host2/scan && echo "- – -"> /sys/class/scsi_host/host1/scan && echo "- – -"> /sys/class/scsi_host/host0/scan
See if discovered disk is found in /var/log/messages :
[…]
Nov 8 17:33:26 bict4004s kernel: scsi 2:0:2:0: Direct-Access VMware Virtual disk 1.0 PQ: 0 ANSI: 2
Nov 8 17:33:26 bict4004s kernel: scsi target2:0:2: Beginning Domain Validation
Nov 8 17:33:26 bict4004s kernel: scsi target2:0:2: Domain Validation skipping write tests
Nov 8 17:33:26 bict4004s kernel: scsi target2:0:2: Ending Domain Validation
Nov 8 17:33:26 bict4004s kernel: scsi target2:0:2: FAST-40 WIDE SCSI 80.0 MB/s ST (25 ns, offset 127)
Nov 8 17:33:26 bict4004s kernel: sd 2:0:2:0: Attached scsi generic sg3 type 0
Nov 8 17:33:26 bict4004s kernel: sd 2:0:2:0: [sdb] 2097152 512-byte logical blocks: (1.07 GB/1.00 GiB)
Nov 8 17:33:26 bict4004s kernel: sd 2:0:2:0: [sdb] Write Protect is off
Nov 8 17:33:26 bict4004s kernel: sd 2:0:2:0: [sdb] Cache data unavailable
Nov 8 17:33:26 bict4004s kernel: sd 2:0:2:0: [sdb] Assuming drive cache: write through
Nov 8 17:33:26 bict4004s kernel: sd 2:0:2:0: [sdb] Attached SCSI disk
[…]
3. Create new LVM Physical Volume
[root@vm-hostname ~]# pvcreate /dev/sdb
4. Enlarge LVM Volume Group to the max available size of /dev/sdb
[root@vm-hostname ~]# vgextend vg00 /dev/sdb
Enlarge LVM Logical Volume
[root@vm-hostname ~]# lvextend -L+10G /dev/mapper/vg00-home
5. Enlarge filesystem to max size of just created LVM
If Filesystem is ext3 or ext4 :
[root@vm-hostname ~]# resize2fs /dev/mapper/vg00-home
Again if we work with XFS additionally do:
[root@vm-hostname ~]# xfs_growfs /dev/mapper/vg00-home
6. Checking filesystem extension completed correct
[root@vm-hostname ~]# df -h /home
…
7. Check filesystem is writtable and no errors produced in logs
Check of system log:
[root@vm-hostname ~]# grep -i error /var/log/messages
…
Check if filesystem is writable.
[root@vm-hostname ~]# touch /home/test
…