Posts Tagged ‘Socket’
Sunday, May 20th, 2012 
My home run machine MySQL server was suddenly down as I tried to check my blog and other sites today, the error I saw while trying to open, this blog as well as other hosted sites using the MySQL was:
Error establishing a database connection
The topology, where this error occured is simple, I have two hosts:
1. Apache version 2.0.64 compiled support externally PHP scripts interpretation via libphp – the host runs on (FreeBSD)
2. A Debian GNU / Linux squeeze running MySQL server version 5.1.61
The Apache host is assigned a local IP address 192.168.0.1 and the SQL server is running on a host with IP 192.168.0.2
To diagnose the error I've logged in to 192.168.0.2 and weirdly the mysql-server was appearing to run just fine:
debian:~# ps ax |grep -i mysql
31781 pts/0 S 0:00 /bin/sh /usr/bin/mysqld_safe
31940 pts/0 Sl 12:08 /usr/sbin/mysqld –basedir=/usr –datadir=/var/lib/mysql –user=mysql –pid-file=/var/run/mysqld/mysqld.pid –socket=/var/run/mysqld/mysqld.sock –port=3306
31941 pts/0 S 0:00 logger -t mysqld -p daemon.error
32292 pts/0 S+ 0:00 grep -i mysql
Moreover I could connect to the localhost SQL server with mysql -u root -p and it seemed to run fine. The error Error establishing a database connection meant that either something is messed up with the database or 192.168.0.2 Mysql port 3306 is not properly accessible.
My first guess was something is wrong due to some firewall rules, so I tried to connect from 192.168.0.1 to 192.168.0.2 with telnet:
freebsd# telnet 192.168.0.2 3306
Trying 192.168.0.2…
Connected to jericho.
Escape character is '^]'.
Host 'webserver' is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts'
Connection closed by foreign host.
Right after the telnet was initiated as I show in the above output the connection was immediately closed with the error:
Host 'webserver' is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts'Connection closed by foreign host.
In the error 'webserver' is my Apache machine set hostname. The error clearly states the problems with the 'webserver' apache host unable to connect to the SQL database are due to 'many connection errors' and a fix i suggested with mysqladmin flush-hosts
To temporary solve the error and restore my normal connectivity between the Apache and the SQL servers I logged I had to issue on the SQL host:
mysqladmin -u root -p flush-hostsEnter password:
Thogh this temporar fix restored accessibility to the databases and hence the websites errors were resolved, this doesn't guarantee that in the future I wouldn't end up in the same situation and therefore I looked for a permanent fix to the issues once and for all.
The permanent fix consists in changing the default value set for max_connect_error in /etc/mysql/my.cnf, which by default is not too high. Therefore to raise up the variable value, added in my.cnf in conf section [mysqld]:
debian:~# vim /etc/mysql/my.cnf
...
max_connect_errors=4294967295
and afterwards restarted MYSQL:
debian:~# /etc/init.d/mysql restart
Stopping MySQL database server: mysqld.
Starting MySQL database server: mysqld.
Checking for corrupt, not cleanly closed and upgrade needing tables..
To make sure the assigned max_connect_errors=4294967295 is never reached due to Apache to SQL connection errors, I've also added as a cronjob.
debian:~# crontab -u root -e
00 03 * * * mysqladmin flush-hosts
In the cron I have omitted the mysqladmin -u root -p (user/pass) input options because for convenience I have already stored the mysql root password in /root/.my.cnf
Here is how /root/.my.cnf looks like:
debian:~# cat /root/.my.cnf
[client]
user=root
password=a_secret_sql_password
Now hopefully, this would permanently solve SQL's 'failure to accept connections' due to too many connection errors for future.
Tags: apache version, Auto, basedir, bin, cnf, connection, connectionThe, daemon, database connection, debian gnu, default, Draft, due, error error, firewall rules, fix, freebsd, GNU, guess, host, host name, hostname, lib, Linux, local ip address, localhost, machine, mysql server, mysqladmin, mysqld, mysqlMoreover, nbsp, occured, password, port 3306, root, root password, running, server version, sl 12, Socket, something, SQL, sql server, squeeze, support, topology, value, webserver
Posted in MySQL, System Administration, Web and CMS | No Comments »
Saturday, May 12th, 2012 After migrating databases data from FreeBSD MySQL 5.0.83 server to a Debian Squeeze Linux MySQL version 5.1.61, below is a mysql –version issued on both the FreeBSD and the Debian servers
freebsd# mysql --version
mysql Ver 14.12 Distrib 5.0.83, for portbld-freebsd7.2 (i386) using 5.2
debian:~# mysql --version
mysql Ver 14.14 Distrib 5.1.61, for debian-linux-gnu (i486) using readline 6.1
The data SQL dump from the FreeBSD server was dumped with following command arguments:
freebsd# mysqldump --opt --allow-keywords --add-drop-table --all-databases -u root -p > complete_db_dump.sql
Then I used sftp to transfer complete_db_dump.sql dump to the a brand new installed latest Debian Squeeze 6.0.2. The Debian server was installed using a "clean Debian install" without graphical environment with CD downloaded from debian.org's site.
On the Debian machine I imported the dump with command:
debian:~# mysq -u root -p < complete_db_dump.sql
Right After the dump was imported I re-started SQL server which was previously installed with:
debian:~# apt-get install mysql-server
The error I got after restarting the mysql server:
debian:~# #/etc/init.d/mysql restart
was:
ERROR 1577 (HY000) at line 1: Cannot proceed because system tables used by Event Scheduler were found damaged at server start
ERROR 1547 (HY000) at line 1: Column count of mysql.proc is wrong. Expected 20, found 16. The table is probably corrupted
This error cost me a lot of nerves and searching in google to solve. It took me like half an hour of serious googling ,until I finally found the FIX!!!:
debian:~# mysql_upgrade -u root -h localhost -p --verbose --force
Enter password:
Looking for 'mysql' as: mysql
Looking for 'mysqlcheck' as: mysqlcheck
Running 'mysqlcheck' with connection arguments: '--port=3306' '--socket=/var/run/mysqld/mysqld.sock' '--host=localhost'
Running 'mysqlcheck' with connection arguments: '--port=3306' '--socket=/var/run/mysqld/mysqld.sock' '--host=localhost'
bible.holy_bible OK
bible.holybible OK
bible.quotes_meta OK
Afterwards finally I had to restart the mysql server once again in order to finally get rid of the shitty:
ERROR 1547 (HY000) at line 1: Column count of mysql.proc is wrong. Expected 20, found 16. The table is probably corrupted error!
debian:~# /etc/init.d/mysql restart
Stopping MySQL database server: mysqld.
Starting MySQL database server: mysqld.
Checking for corrupt, not cleanly closed and upgrade needing tables..
This solved the insane Column count of mysql.proc is wrong. Expected 20, found 16 once and for all!
Before I came with this fix I tried all kind of forum suggested fixes like:
debian:~# mysql_upgrade -u root -p
Looking for 'mysql' as: mysql
Looking for 'mysqlcheck' as: mysqlcheck
This installation of MySQL is already upgraded to 5.1.61, use --force if you still need to run mysql_upgrade
debian:~# mysql_upgrade -p
Looking for 'mysql' as: mysql
Looking for 'mysqlcheck' as: mysqlcheck
This installation of MySQL is already upgraded to 5.1.61, use --force if you still need to run mysql_upgrade
And few more, none of them worked the only one that worked was:
debian:~# #mysql_upgrade -u root -h localhost -p --verbose --force
I have to say big thanks to Mats Lindth wonderful blog post which provided me with the solution.
It seems, since Oracle bought the Community edition of MySQL thinks with this database server are getting more and more messy and backwards incompatible day by day.
Lately, I'm experiencing too much hassles with MySQL version incompitabilities. Maybe I should think for migrating permanently to Postgre …
By the way the ERROR 1547 (HY000) at line 1: Column count of mysql.proc is wrong. is most probably caused of some kind of password hashing incompitability between the password hashing between the BSD and Debian SQL versions, as mysql -u root -p < dump.sql, does override default stored user passwords in the mysql database tables… Such password, hashing issues were common in prior MySQL 4 to MySQL 5 migrations I've done, however since MySQL 5+ is already storing its password strings encrypted with md5 encryption I wonder why on earth this mess happens ….
Tags: Auto, COLUMN, column count, command arguments, connection, cost, count, debian linux, debian server, Draft, event, event scheduler, fix, freebsd server, google, googling, graphical environment, half an hour, host, host localhost, init, installation, line 1, linux gnu, localhost, machine, mysq, mysql server, mysqlcheck, mysqld, nerves, password, port 3306, quot, root, server start, sftp, Socket, SQL, squeeze, system tables, TABLE, verbose
Posted in Everyday Life, MySQL, System Administration, Web and CMS | 2 Comments »
Sunday, July 29th, 2012 A friend of mine (Dido) who is learning C programming, has written a tiny chat server / client (peer to peer) program in C. His program is a very good learning curve for anyone desiring to learn basic C socket programming.
The program is writen in a way so it can be easily modified to work over UDP protocol with code:
struct sockaddr_in a;
a_sin_family=AF_INET;
a_sin_socktype=SOCK_DGRAM;
Here are links to the code of the Chat server/client progs:
Tiny C Chat Server Client source code
Tiny C Chat Client source code
To Use the client/server compile on the server host tiny-chat-serer-client.c with:
$ cc -o tiny-chat-server tiny-chat-server.c
Then on the client host compile the client;
$ cc -o tiny-chat-client tiny-chat-client.c
On the server host tiny-chat-server should be ran with port as argument, e.g. ;
$ ./tiny-chat-server 8888
To chat with the person running tiny-chat-server the compiled server should be invoked with:
$ ./tiny-chat-client 123.123.123.123 8888
123.123.123.123 is the IP address of the host, where tiny-chat-server is executed.
The chat/server C programs are actually a primitive very raw version of talk.
The programs are in a very basic stage, there are no condition checks for incorrectly passed arguments and with wrongly passed arguments it segfaults. Still for C beginners its useful …
Tags: Auto, c programming, c programs, c socket programming, chat client, chat server, checks, client, client host, client server, client source code, codeTo, cThen, curve, dido, Draft, family, ip address, learning c, learning curve, mine, minimalistic, peer to peer program, person, port, program, programming, Protocol, raw version, server c, server client, server host, sockaddr, Socket, socktype, stage, struct, struct sockaddr, Tiny, tiny c, UDP, version, way, writen
Posted in Programming | No Comments »
Monday, April 2nd, 2007 I need harmony. I’m overwhelmed with work and thoughts about existence, you know it’s a terrible thing to think about the human existence all the time. The time passes slowly. Today I went throught a lot of stress. It seems that I did a mistake when modifying the server firewall in Friday when we moved pozvanete and connections about the aids were not possible thanksfully Vladi said it will be fixed. Bobb reported that efficiencylaboratory system does not send emails when I take a look I saw the qmail queue was broken ( something I see for a first time ). qmail-qstat reported empty queue while qmail-qread reported empty. I found this about fixing messed queues http://pyropus.ca/software/queue-repair/. After running it over the queue and restarting the mail server few times it seemed to work at the end. I experience terrible problem when trying to run jailkit on one Debian Sarge machine, I’m trying to figure out what is the reason few days ago with no luck a terrible thing even stracing the jk_socket does not provide with anything that could lead to a solution when I’m logging into the machine with the jailed user the auth.log indicates that login is successful and sftp-server is spawned while the sftp client closes the connection. I’ll be looking at this later again I really ran out of ideas aboud a possible solution.I’m very tired I need rest. Too often I despair sometimes I want to cry, there is so much unrightfulness in the world. On Saturday night me and Nomen decided to do a pretty Ñ€eckless thing we catched the train for Botevo and spend the night in a forest around a fire. This time we was equiped at least we had a torch. We baked bread and potatoes on the fire and made a sort of sandwiches with a salt and cucumbers. At least this time we went to the other forest and there were trees all around so it wasn’t necessary to search for them in the darkness. All the forecast said it would rain. But Praise the Lord it didn’t. (We even prayed a little to God not to rain cause we had not the proper equipment ). Thanksfully again God heard our prayers. The only bad side of our great adventure was that after 1:00 o’clock in the morning the temperature started falling and it was extremely cold. I was able to sleep just for 40 minutes or so. In the morning after 6:00 the birds started to awaken and sing, so beautiful voices all around, even flickers :]. In went to the Botevo’s railway station and in 8:40 take the train back to Dobrich. I went home and took a shower then went to bed. I was woken by a telephone call and it was the missionary which call me two days ago wanted to see me and speak about the faith, he call me to remind me of our meeting ( from the way he speaks I undestood he is a Mormon ). So I decided to rewrite the Orthodox Creed of Faith and show him and explain them what I believe. When we met they were very kind to me and after some time they supposed to go to their church to explain us about their faith. I went their and they started talking strange things they wanted to pray together ( I rejected ofcourse ). How can we pray a prayer I have no idea about.After a lot of discussion about the Gospel and the truth Church they got angry and chased me out of their sect/”church” ;]They tried to lie they tried to claim they’re orthodox Christians in the first cause I told them I’m orthodox. One of the Moroms tried to convince me he knows more about orthodox Christianity more than me. Other of the two cited me a some Writting in the Book of Jeremiah trying to convince me I have existed before my birth, I told him this is occult (this was my opinion ofcourse God knows best).END—–
Tags: Bobb, bread, ca software, cause, client, connection, cucumbers, despair, efficiencylaboratory, empty queue, existence, fire this time, harmony, human existence, jailkit, login, mail server, possible solution, potatoes, pozvanete, pray, queue, queues, quot, reason, sandwiches, saturday night, server firewall, sftp, sftp client, sftp server, Socket, software queue, something, terrible thing, time, torch, train, work
Posted in Everyday Life | No Comments »
Tuesday, June 28th, 2011 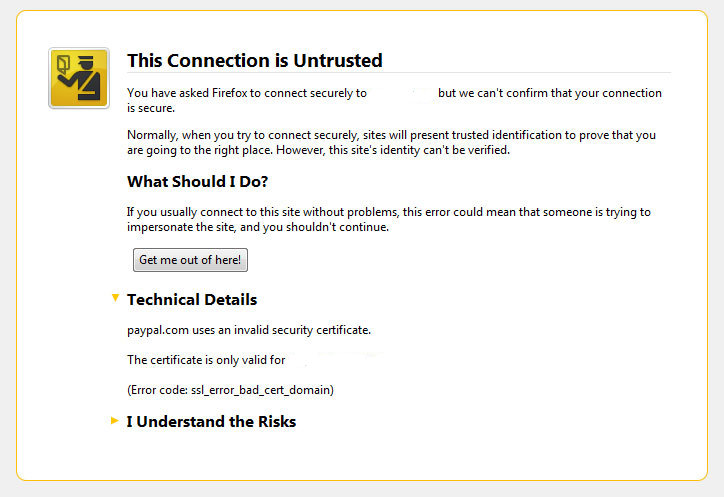
I’ve been issuing new wildcard multiple SSL certificate to renew an expiring ones. After I completed the new certificate setup manually on the server (a CentOS 5.5 Final running SoluSVM Pro – Virtual Private Manager), I launched Firefox to give a try if the certificate is properly configured.
Instead of my expectations that the browser would just accept the certificate without spitting any error messages and all will be fine, insetad I got error with the just installed certificate and thus the browser failed to report the SSL cert is properly authenticated.
The company used to issue the SSL certificate is GlobeSSL – http://globessl.com , it was quite “hassle”, with the tech support as the first certficate generated by globessl was generation based on SSL key file with 4096 key encryption.
As the first issued Authenticated certificate generated by GlobeSSL was not good further on about a week time was necessery to completethe required certificate reissuing ….
It wasn’t just GlobeSSL’s failure, as there were some spam filters on my side that was preventing some of GlobeSSL emails to enter normally, however what was partially their fault as they haven’t made their notification and confirmation emails to pass by a mid-level strong anti-spam filter…
Anyways my overall experience with GlobeSSL certificate reissue and especially their technical support is terrible.
To make a parallel, issuing certificates with GoDaddy is a way more easier and straight forward.
Now let me come back to the main certificate error I got in Firefox …
A bit of further investigation with the cert failure, has led me to the error message which tracked back to the newly installed SSL certificate issues.
In order to find the exact cause of the SSL certificate failure in Firefox I followed to the menus:
Tools -> Page Info -> Security -> View Certificate
Doing so in the General browser tab, there was the following error:
Could not verify this certificate for unknown reasons
The information on Could not verify this certificate for unknown reasons on the internet was very mixed and many people online suggested many possible causes of the issue, so I was about to loose myself.
Everything with the certificate seemed to be configured just fine in lighttpd, all the GlobeSSL issued .cer and .key file as well as the ca bundle were configured to be read used in lighttpd in it’s configuration file:
/etc/lighttpd/lighttpd.conf
Here is a section taken from lighttpd.conf file which did the SSL certificate cert and key file configuration:
$SERVER["socket"] == "0.0.0.0:443" {
ssl.engine = "enable"
ssl.pemfile = "/etc/lighttpd/ssl/wildcard.mydomain.bundle"
}
The file /etc/lighttpd/ssl/wildcard.mydomain.bundle was containing the content of both the .key (generated on my server with openssl) and the .cer file (issued by GlobeSSL) as well as the CA bundle (by GlobeSSL).
Even though all seemed to be configured well the SSL error Could not verify this certificate for unknown reasons was still present in the browser.
GlobeSSL tech support suggested that I try their Web key matcher interface – https://confirm.globessl.com/key-matcher.html to verify that everything is fine with my certificate and the cert key. Thanks to this interface I figured out all seemed to be fine with the issued certificate itself and something else should be causing the SSL oddities.
I was further referred by GlobeSSL tech support for another web interface to debug errors with newly installed SSL certificates.
These interface is called Verify and Validate Installed SSL Certificate and is found here
Even though this SSL domain installation error report and debug tool did some helpful suggestions, it wasn’t it that helped me solve the issues.
What helped was First the suggestion made by one of the many tech support guy in GlobeSSL who suggested something is wrong with the CA Bundle and on a first place the documentation on SolusVM’s wiki – http://wiki.solusvm.com/index.php/Installing_an_SSL_Certificate .
Cccording to SolusVM’s documentation lighttpd.conf‘s file had to have one extra line pointing to a seperate file containing the issued CA bundle (which is a combined version of the issued SSL authority company SSL key and certificate).
The line I was missing in lighttpd.conf (described in dox), looked like so:
ssl.ca-file = “/usr/local/solusvm/ssl/gd_bundle.crt”
Thus to include the directive I changed my previous lighttpd.conf to look like so:
$SERVER["socket"] == "0.0.0.0:443" {
ssl.engine = "enable"
ssl.pemfile = "/etc/lighttpd/ssl/wildcard.mydomain.bundle"
ssl.ca-file = "/etc/lighttpd/ssl/server.bundle.crt"
}
Where server.bundle.crt contains an exact paste from the certificate (CA Bundle) mailed by GlobeSSL.
There was a couple of other ports on which an SSL was configured so I had to include these configuration directive everywhere in my conf I had anything related to SSL.
Finally to make the new settings take place I did a lighttpd server restart.
[root@centos ssl]# /etc/init.d/lighttpd restart
Stopping lighttpd: [ OK ]
Starting lighttpd: [ OK ]
After lighttpd reinitiated the error was gone! Cheers ! 😉
Tags: anti spam filter, bundle, CentOS, cert, certficate, certificate, certificate error, Certificates, completethe, confirmation, confirmation emails, directive, encryption, Engine, error message, error messages, everything, exact cause, failure, file, Firefox, generation, godaddy, hassle, key file, menus, mid level, necessery, pemfile, place, private manager, Socket, something, spam filters, ssl certificate, support, tech support, time, Virtual
Posted in System Administration, Web and CMS | No Comments »
Monday, May 23rd, 2011 One of the Qmail server installations I’m taking care of’s clamd antivirus process started loading the system heavily.
After a bit of log reading and investigation I’ve found the following error in my /var/log/clamd/current
@400000004dda1e1815cf03f4 ERROR: LOCAL: Socket file /tmp/clamd.socket is in use by another process.
I’ve noticed in my process list that actually I do have two processes clamd :
11608 ? Sl 0:05 /usr/local/sbin/clamd
11632 ? S 0:00 /usr/bin/multilog t /var/log/clamd
16013 ? Sl 0:06 /usr/local/sbin/clamd
It appeared that for some weird reason one of the clamd process was failing to connect constantly to the clam server socket /tmp/clamd.socket and each time it tried to connect and failed to connect to the socket the system gets about 5% of extra load …
Resolving the issues was a piece of cake, all I had to do is stop the clamd server delete the /tmp/clamd.socket and relaunch the clamd server.
Here is exactly the commands I issued:
debian:~# cd /service/
debian:/service# svc -a clamd
debian:/service# svc -h clamd
debian:/service# svc -d clamd
debian:/service# rm -f /tmp/clamd.socket
debian:/service# svc -u clamd
Afterwards the clamd extra load went out and in /var/log/clamd/current I can see clamd loads fine without errors, e.g.:
Listening daemon: PID: 16013
MaxQueue set to: 150
No stats for Database check - forcing reload
Reading databases from /usr/local/share/clamav
Database correctly reloaded (966822 signatures)
SelfCheck: Database status OK.
...
Tags: antivirus, care, cd service, clam, clamddebian, Database, database check, database status, databases, dda, debian cd, ERROR, file tmp, investigation, LOCAL, multilog, PID, piece of cake, Qmail, reading, reason, rm, sbin, SelfCheck, server installations, server socket, share, signatures, Socket, socketdebian, time, tmp, use, var, weird reason
Posted in Linux, System Administration | 1 Comment »




