If you are student or just a researcher, you already know most of the good books you can find are on books.google.com. Google Books's is nice, but not all browsers support it well. Older mobile phones has big troubles with it, plus it is always nice to have a stored copy of book on your PC for later review or just to refresh your memory on books previously read.
Thus if you get to task to download Books from Google a quick research reveals few programs claiming to support downloading Books from Google in PDF;
1. Google Books Download standalone application for Windows and Mac OS X
Google Books Download is said to support Save of Google books in PDF, JPEG or PNG format.
This program works good whether you need to extract only certain book pages, however with complete books it often hangs. Other problem is it is proprietary software, (freeware), so pages book pages it downloads in PDF had a big red color stamp complaining the program is trial.
There is a cracked version available on Piratebay.se's website. But as Piratebay is filtered from here. To test it I had to google it via piratebay proxy: – with "piratebay google books download".
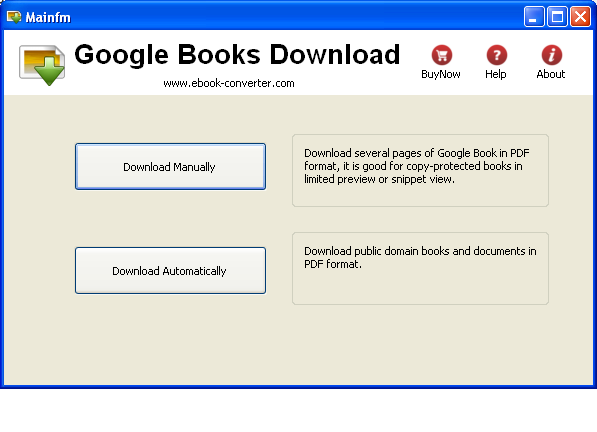
Google Books Download, standalone app from Piratebay is at current version 3.1.308.
As you can see from screenshot Google Book Download has two modes of work, one is;
Download Manually – This is used for manual download a pages from a complete book and converting them to PDF.
Download Automatically – Is purposed to download a complete book from books.google.com and converting it to PDF. Downloading a complete copy of book using this mode is sometimes, hanging, plus it is really, really slow. The reason is each of the pages from the Book is first scanned using OCR (Optical Character Recognition) technology page by page and later after all pages are downloaded in pictures, they're converted to 1 PDF file.
Because Download Automatically loops at certain pages, this makes Google Books Download almost useless for people looking to store a full copy of books on Books.Google.com ….
2. Downloading PDFs from books.google.com with Firefox Greasemonkey and Google Book Downloaderjavascript
a. Install GreaseMonkey Firefox add-on
If you never before heard of Greasemonkey is a Mozilla Firefox Extension that allows users to install scripts that make on-the-fly changes to web page content after or before the page is loaded in the browser (also known as augmented browsing).
b. Install Google book downloader GreaseMonkey javascript
After a FF restart, you're ready to download any book from Books.Google.com.
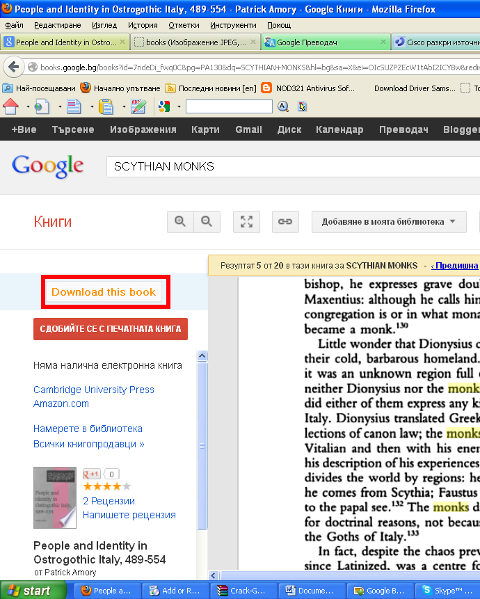
To use it open the book you want to download and on the left upper corner you will see a Download this book button, press it and the book will be scanned in OCR and saved in PNG picture format. Below is a screenshot showing a sample book to download from books.google.com;
After each book page is succesfully download in page on the left pane you get a download status;
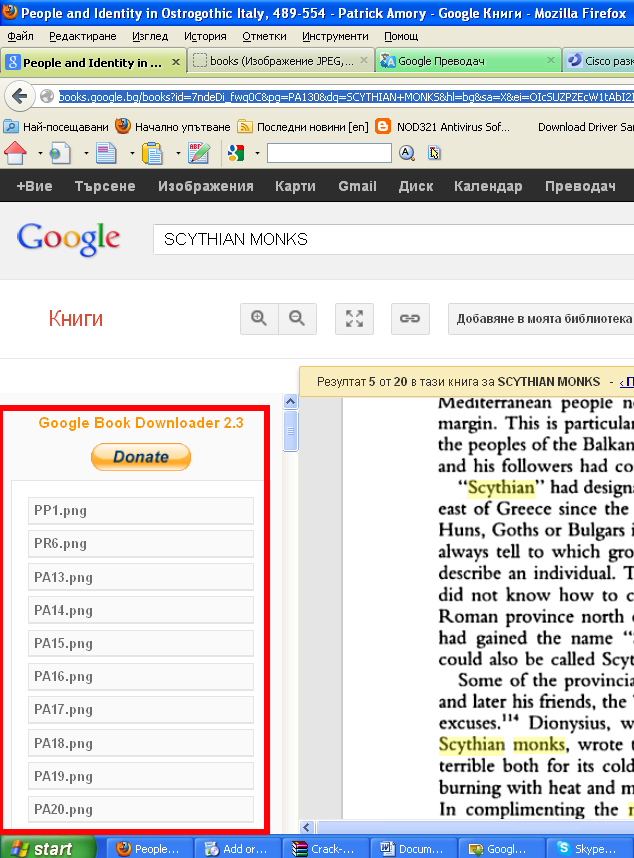
You should keep in mind that the download links of Google Book pages, will have a time expiry, so if you don't hurry up to save the pictures for later use soon links will become inaccessible and showing as broken from Google – I'm not sure how much exactly is google's max expiry time set of links but I guess it should be something 5-10 mins.
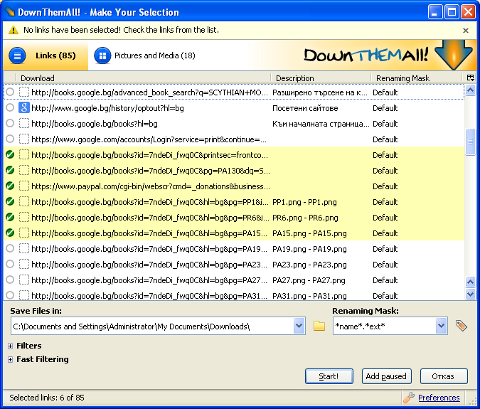
The pages of PDF, gets fetched as pictures one by one so it takes 20 secs or so to get all links to pages. Since Google Books Downloader only provides links to PDF pages it is necessery to either save each of the pictures manually (quite a lot of effort) or Install and use lets say DownThemAll! FF download extension. Using DownThemAll does not completely automates picture downloads, as you need to manually select all pictures for downloading, but at least selecting pages saves some time. To download all book pages with DownThemAll click with right mouse button on the left pane where links to pictures appears and choose download with DownThemAll!. After that tick on all links pointing to books.google.com……. to make them have the green tick as shown in below screenshot;
Once you have all PNGs saved on the PC you need to then convert them to unified PDF file. One way to do this is using ImageMagick's convert command line tool.
To do so install imagemagick for Windows downloading Win binaries from here
There are a bunch of binaries you will need to install named like ImageMagick-*-x86-static.exe
Run cmd.exe, change dir (cd) to folder where the just download book is saved in PNG and issue:
C:Downloads>convert *.png pdf/my-book-from-pictures.pdf



More helpful Articles

Tags: character recognition, complete books, cracked version, current version, good books, google, greasemonkey, mac os x, memory, Mobile phones, modes, os x, png format, proxy, researcher





Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0
Many thanks for your info
View CommentView CommentMozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36
Thanks for sharing your thoughts about character recognition. Regards
View CommentView Comment