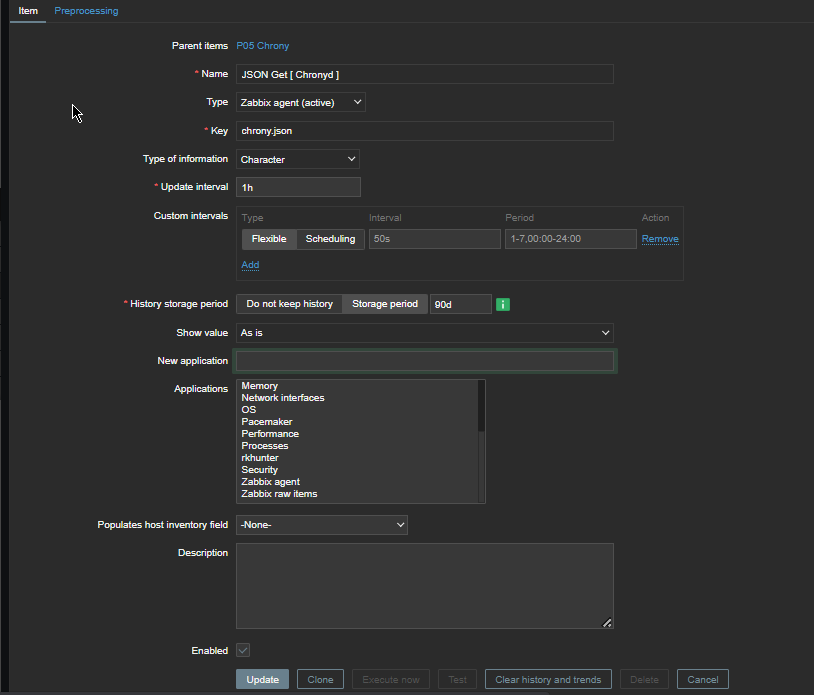
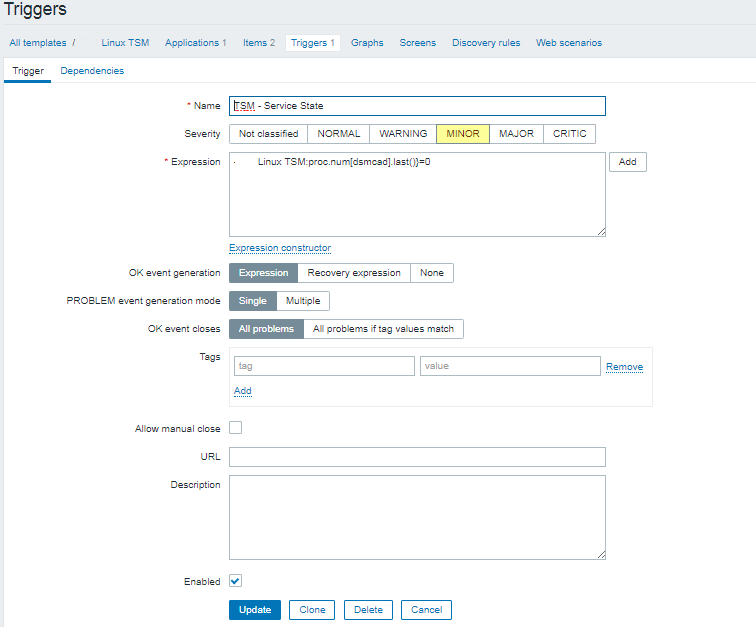
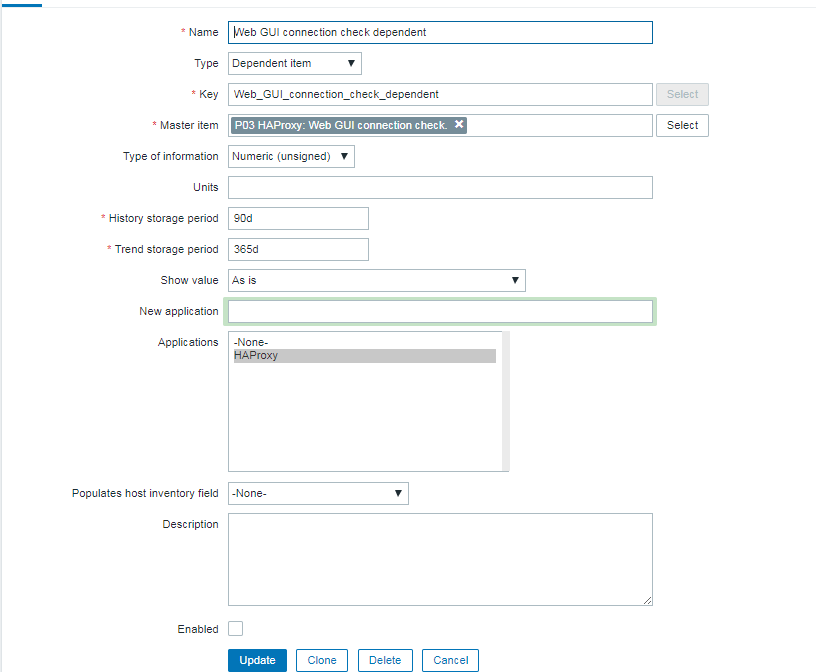
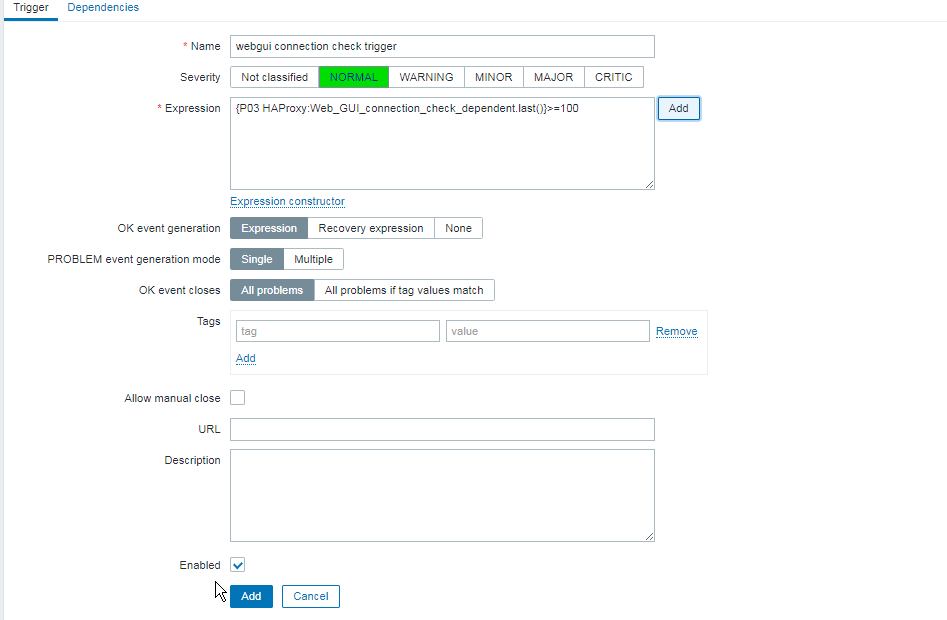
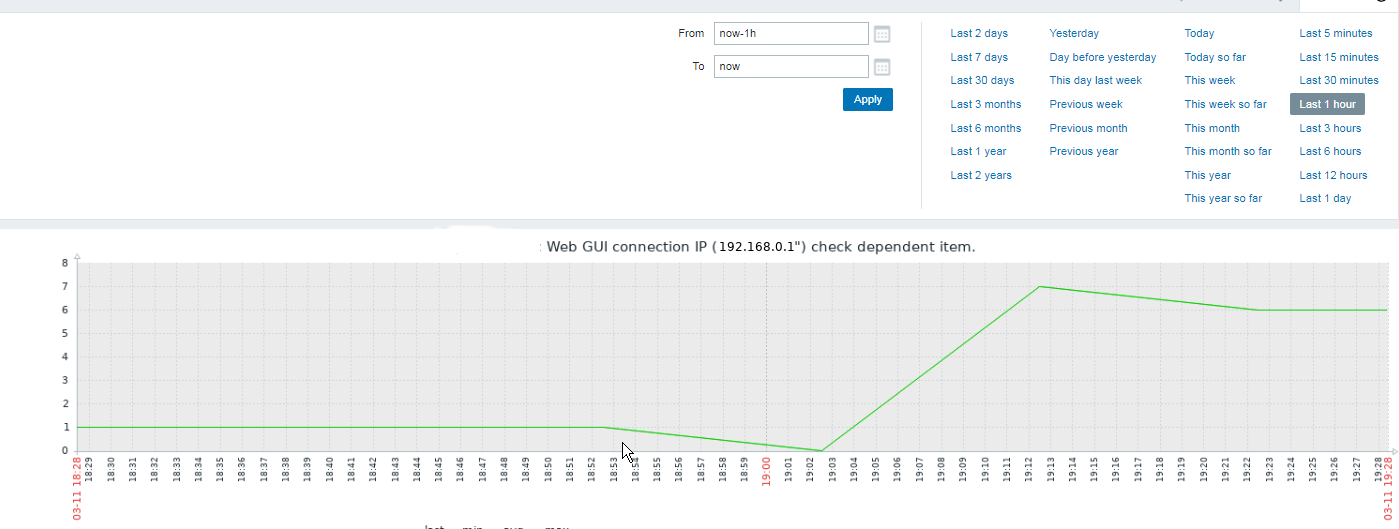
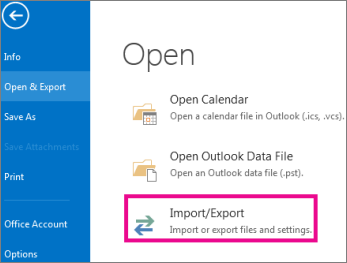
The inhabitants of Thracia are of a great and royal origin and due to recent historical studies, Thracians have been one of the most developed nations for its time they're developments and achievements especially in crafts such as vessel creation even up to day are perhaps the most unique.
It is still unknown of the exact technology used to create such a elegant and precise vessels. A little is known of the Thracians society as they have reached their bloom in a high speed and the place of the later Roman Empire province Thracia has been in a place where it was destroyed to the ground and robbed at multiple times eradicating unique piece of one of the best created ever forms of art.
Territories of Thrakia has been geographically today located in Southeast Europe, now split among Bulgaria, Greece, and Turkey, which is bounded by the Balkan Mountains to the north, the Aegean Sea to the south, and the Black Sea to the east.
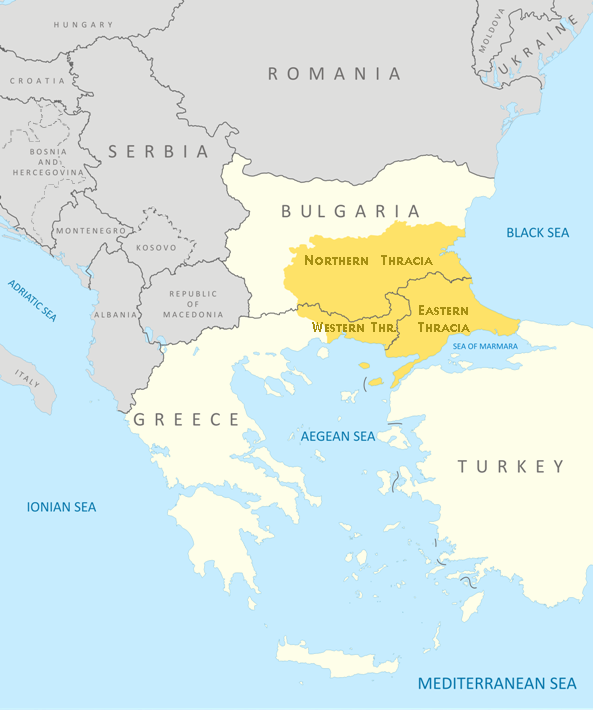
Territy of Thracia shown on a contemporary European (Balkans Maps)

One of the most famous piece of such art is the World Famous Thracian's Treasuary.

The thrakians Empire and civillization has its bloom from 5th – 4th century before Christ era (B.C.).
Saint Petka of Epivates region Thrakia was of a Bulgarian origin and lived much later in Xth – XI-th century A.D in Thracia. It is known she was of Bulgarian origin (her mother and father was of Bulgarian origin.) of the first generations who has received in 9-th century Baptism, in the times of the Baptism of Bulgaria conducted by the Apostle equal Saint King Boris I the Baptizer of Bulgaria in year 864 AD. Thracians as an ancient and a blessed nation in craftship and arts was among the nations who received baptism on a good 'soil', as the seed of beauty and goodness has already been in their civillization.
The short Living of Saint Petka of Bulgaria (of Epivates)
Out of this Christian atmosphere has rised Saint Petka also known as (Parashkeva). Saint Petka name means literally translated Friday and due to being born in Thracia on today territory of Balkans she is been venerated highly not only in Bulgaria but across all Orthodox Christians nations on the Balkans – Bulgarians, Romanians, Serbs, Greeks, Macedonians. Due to that Saint Petka is also famous as "Saint Petka of The Bulkans".
Saint Petka could be therefore heard to be called often Petka of Serbs (of Belgrade), Saint Petka of Moldova (of Iași), Mother Paraskeva / Parashkeva, Parascheva the New, Parascheva the Young, Ancient Greek: Ὁσία Παρασκευὴ ἡ Ἐπιβατινή, Greek: Οσία Παρασκευή η Επιβατινή ή Νέα, Romanian: Cuvioasa Parascheva, Bulgarian / Serbian : Света Петка / Sveta Petka or Петка Параскева / Petka Paraskeva, Paraskeva Pyatnitsa, Parascheva of Tirnovo).
The first information about her living is found in a local educated person (writter) which as of the time were too little and writter in Greek in short. It did not follow the Church cannons and due to that by an order of Patriarch of Constantinople Nikolas IV Musalon of Constantinople deacon Vaslik has described in a more well systemized way her living, the Greek original unfortunately is now lost. At the time of writting her biography, she has been mostly popular in the realms of Byzantine Empire Thracia.
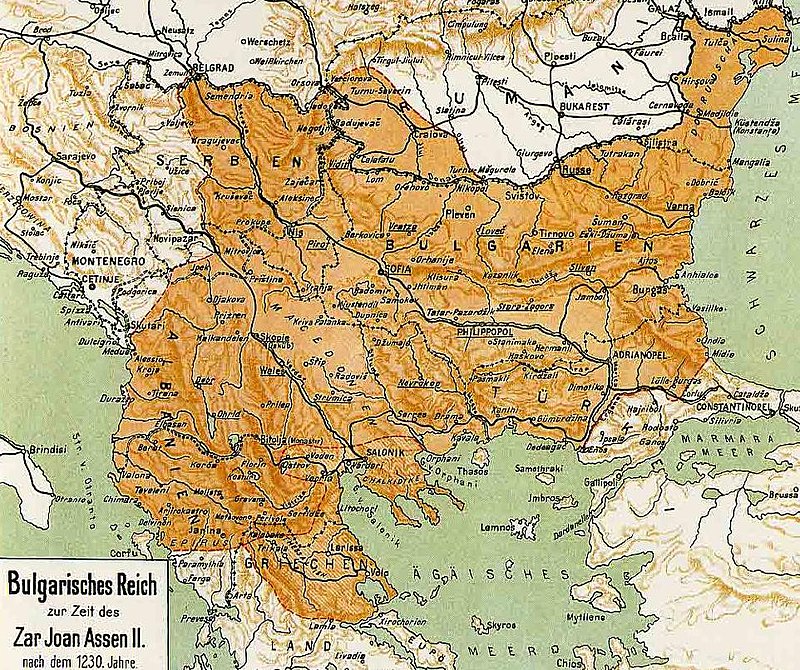
The Bulgarian Empire during the reign of Ivan Asen II. Atlas of Dimitar Rizov year 1917
Since the time of King Ivan Asen II a new biogprahy of saint has been written in Bulgarian which included narration of the transfer of her holy relics to Medieval Capital of Bulgaria Tarnovo. However peak and the key towards the immerse veneration to St. Petka that is evident to this very date has played the biography written by last Bulgarian Patriarch also a saint – st. Euthymius of Tarnovo. in year 1385 AD short before the fall under Turkish Slavery of Bulgaria in y. 1393.
Saint Patriarch Eutymious was the last person who in 1393 has actively parcipated in the protection of the fortified Tarnovo and see with his eyes the fall down of the city (by treachery).
When asked by the terrified people 'To whom do you leave us holy father, when the Turkish were taking him away?' He replied heart tearingly 'To the Holy Trinity The Father, The Son and The Holy Trinity our God I leave you and to the most Blessed Mother of God Theotokos now and For Eternity !!!'

Saint Patriarch Eutymius (Evtimij) blessing the people in Medieval Bulgarian city Tarnovo for a last time before the Turkish took him away for imprisonment
Picture source Pravoslavieto.com
St Euthymius of Tarnovo work is one of the most unique bibliographies and a precious piece of medieval literature it is innovative for its time and spectacular, emotion rich creation, who become famous far before the borders of Bulgaria in the whole Slavonic world of that time, especially in todays territory of ex soviet countries Romania, Moldova, Ukraine and even far Russia.

Saint Patriarch Eutymious of Bulgaria
Picture source Pravoslavieto.com
The veneration of Saint Petka of Bulgaria as a protector of family and a warm prayerer for all those who venerate her in this country has slowly spread in the coming centuries by pupils of St. Euthymius of Tarnovo who according to some historians whose works came to us in the form of the a bit more standardized Church Slavonic used in the Eastern Orthodox Churches as a fruit of the works of St. Euthymus.
The Living of Saint Petka Parashkeva

Saint Petka Parashkeva Picture source Pravoslavieto.com
Tropion 4-th voice
Desertous and silent living you loved after Christ your groom, diligently you ran to and his good yoke you took in your younghood,
with the Sign of the Cross against the thought enemies you have manly armed, with fasting feats and prayer and with tear drops the coals of passions extinguished oh highly famed Paraskevo. And now in the Heavenly halls with the wise virgins you stay in front of Christ, pray for us who venerate your holy remembrance.
Kontakion, voice 6
Let us piusly sung our reverend mother Saint Petka, because by living the corruptable in live, received the imperishable in eternity, becoming holy intercessor for all in trouble and exhausting from the evils of life. For the reason she received from God imperishable fame, glory and grace to be a wonder worker.

NB ! St. Petka of Epivates has not to be confused with Saint Petka (from Inokia who lived in 303 AD venerated on 28 of October) or St Petka the Roman (feast day 26 July).
St. Petka's has been born in city of Epivates in Byzantium (today city called Selim Pasha nearby Odrin's Aegian City) in 10-th Century from a famous and respectful family, her father Nikita has been very rich landowner.
She lived in the second part of X-th century. According to hear living by Patriarch Eutymious, her smaller brother Eutymious who become a monk has been a Metropolitan of Maditos for 40 years and in year (989 – 996) died aged 81 and is shortly after canonized as saint, his younger sister St. Paraskeva passed away after him in the new 11-th century and is aged at least 85 in the time of passing in the city of Kallikrateia.
The living continues that near the age of 10 year old she heard in a Christian temple a voice by Jesus Christ himself in resemblance to Saint Apostle Paul and said the Evangelical New Testamental words:
"Whoever wants to walk after me, let him deny himself, to take his cross and follow me !".
The unexpected vision convinced the young Paraskeva to immediately exchange her new clothes to a beggers to leave all her belongings to the poor and live a silent living similarto begger for a time in work and prayer, though she did not leave her parents home. On a few occasions all she had worked for has been distributed to the poor.

Greek typical depiction of Saint Petka of Epivates
When her parents died, her brother as already a monk and Bishop. St. Petka leave her house and travelled to Constanople and received a nun tonsure and as a nun she lived for 5 years near the deserted Church of the "Protection of the Virgin Mary" in the capital suburb of Heraklia. She travelled to the Holy lands visiting Jerusalem and Church of Holy Sepulchre.
Following the example of the blessed famed Saint Mary of Egypt, she lived in Jordan's desert many years till eldership.
Feeling and foreseeing her death, she travelled back through Constantinople to city of Epivates. Settle near the Church "Holy Apostles", where after 2 years of living in deep prayer and fasting labours living in solitary in holiness passed away silently to Christ in heavenly life. Compassionate Christians immediately buried her body of the nun outside of the city walls as a foreigner. A shortly after numerous miracles started happening on her grave.

Saint Petka Parashkeva Bulgarian Icon from Klisura Monastery located nearby Sofia Bulgaria
In 1230 King Ivan Asen II the most powerful South-eastern European ruler demanded from the the Knights of the Crusaders to submit him her holy relics who are found still in Tracian city Kaliakratea ruled at that time by the Holy Latin Empire. King Ivan Asen II together with the patriach Joachim the first receives her holy relics with honor and settles her incorruptabilities into the newly creates Church in honour of herself St. Petka behind Tsarevets Fortress. Saint Petka became from that point considered as a protectress of the city, the throne and the country.
Her holy relics arrived from Kallikrateia in Tarnovo, the Capital of Second Bulgarian Empire in year 1230 AD, she has been thus called Paraskeva of Tarnovo and has been venerated as a protectress of the Tarnovo city the Bulgarian nation and the country. The attitude towards Saint Petka Tarnovska as a protectress of Bulgarian nation and contry is been clearly seen by the mention in the Bulgarian and International acts (documents) and manuscripts of that XII – XII century.

Romanian Monks and Priests venerate the holy relics of Saint Petka of Epivates in Iashi Romania
In subsequent years, St. Petka Paraskevi’s holy relics were transferred to various churches in the region.
In 1393 due to the fall of Bulgarian capital to save them her holy relics were transferred to fortress of Bdin today city of Vidin Bulgaria, but 3 years later 1396 Vidin's fortress also fall under the ungodly yatagan of the muslim enslaver and to protect the relics they were again transferred to Belgrade, specifically the Ružica Church. When Belgrade fell to Ottoman forces in 1521, the relics were transferred to Constantinople. In 1641, the relics were transferred to Trei Ierarhi Monastery, in Iaşi, Moldavia (nowadays, eastern part of Romania). In 1888, they were transferred to the Metropolitan Cathedral of Iaşi.
Since 1888 they are kept in Romanian city of Iaşi and are a target of pilgrims from all around Romania, Bulgaria and other Orthodox Christian countries of the Balkans. For the day her memory is remembered in the Romanian Church usually about 200 000 people mostly from Romania and others travel to Iaşi's Cathedral in the Trei Ierarhi Monastery (Three Hierarchs – saint John Crysostom, St. Basilius the Great and St. Gregory the Great) of the for a blessing and to beg the saint for her families, personal issues, curings especially of eye diseases
A severe drought in 1946-47 affected Moldavia, adding to the misery left by the war. Metropolitan Justinian Marina permitted the first procession featuring the coffin containing the relics of Saint Paraskevi, kept at Iaşi since then. The relics wended their way through the drought-deserted villages of Iaşi, Vaslui, Roman, Bacău, Putna, Neamţ, Baia and Botoşani Counties. The offerings collected on this occasion were distributed, based on Metropolitan Justinian's decisions, to orphans, widows, invalids, school cafeterias, churches under construction, and to monasteries in order to feed the sick, and old or feeble monks.
In the historical document with Venezia as of (year 1347), King Ivan Alexander of Bulgaria swears in the name of most holy considered matters, the document says – quote "in the name of God, The Most Holy Theotokos, The Holy Cross and The Most Holy Paraskeva of Tarnovo".
Since Second Bulgarian Kingdom, St. Petka has been venerated as a main patroness and protector of Bulgarian nation and country, protectress of countries of Moldova, Romania and Bulgarian cities of Veliko Tarnovo, Gabrovo and Troyan.
In Bulgaria it is an old tradition to name our childs in favour of Saint Petka, my grand-grand mother God Forgive us has also been called Parashkeva in favor of Saint Petka.
Holy Mother Petka Paraskeva (Parashkevo) Pray the Lord Jesus Christ to have mercy on All us the sinners !