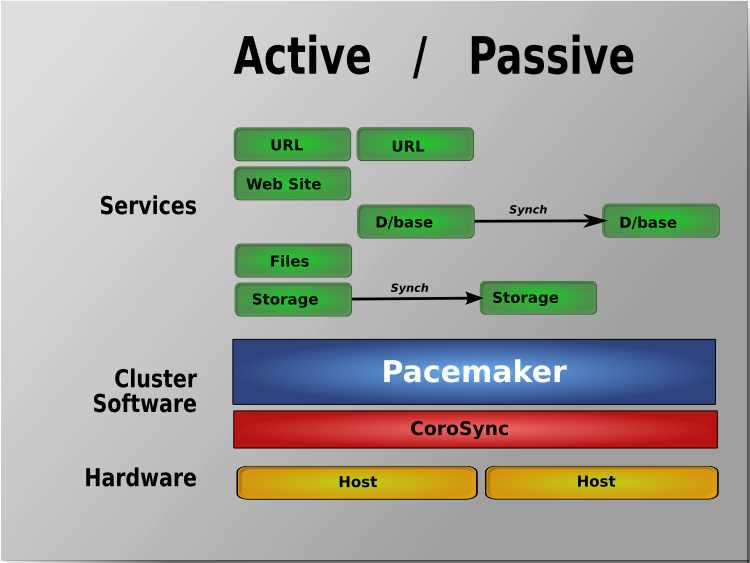
Lets say you have a running PCS Haproxy cluster with 2 nodes and you have already a configuration in haproxy with a running VIP IP and this proxies
are tunneling traffic to a webserver such as Apache or directly to an Application and you end up in the situation where the configured certificates,
are about to expire soon. As you can guess having the cluster online makes replacing the old expiring SSL certificate with a new one relatively easy
task. But still there are a couple of steps to follow which seems easy but systemizing them and typing them down takes some time and effort.
In short you need to check the current certificates installed on the haproxy inside the Haproxy configuration files,
in my case the haproxy cluster was running 2 haproxy configs haproxyprod.cfg and haproxyqa.cfg and the certificates configured are places inside this
configuration.
Hence to do the certificate update, I had to follow few steps:
A. Find the old certificate key or generate a new one that will be used later together with the CSR (Certificate Request File) to generate the new Secure Socket Layer
certificate pair.
B. Either use the old .CSR (this is usually placed inside the old .CRT certificate file) or generate a new one
C. Copy those .CSR file to the Copy / Paste buffer and place it in the Website field on the step to fill in a CSR for the new certificate on the Domain registrer
such as NameCheap / GoDaddy / BlueHost / Entrust etc.
D. Registrar should then be able to generate files like the the new ServerCertificate.crt, Public Key Root Certificate Authority etc.
E. You should copy and store these files in some database for future perhaps inside some database such as .xdb
for example you can se the X – Certificate and Key management xca (google for xca download).
F. Copy this certificate and place it on the top of the old .crt file that is configured on the haproxies for each domain for which you have configured it on node2
G. standby node1 so the cluster sends the haproxy traffic to node2 (where you should already have the new configured certificate)
H. Prepare the .crt file used by haproxy by including the new ServerCertificate.crt content on top of the file on node1 as well
I. unstandby node1
J. Check in browser by accessing the URL the certificate is the new one based on the new expiry date that should be extended in future
K. Check the status of haproxy
L. If necessery check /var/log/haproxy.log on both clusters to check all works as expected
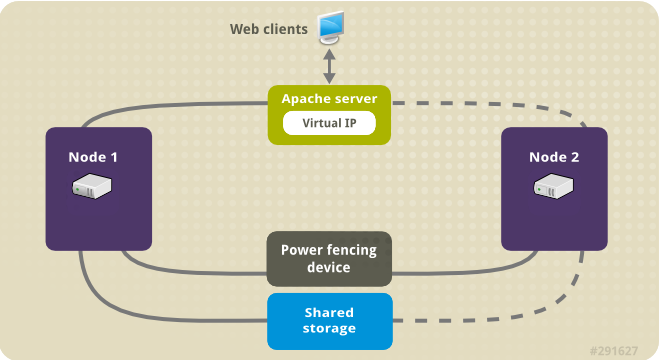
Below are the overall commands to use to complete below jobs
Old extracted keys and crt files are located under /home/username/new-certs
1. Check certificate expiry start / end dates
[root@haproxy-serv01 certs]# openssl s_client -connect 10.40.18.88:443 2>/dev/null| openssl x509 -noout -enddate
notAfter=Aug 12 12:00:00 2022 GMT
2. Find Certificate location taken from /etc/haproxy/haproxyprod.cfg / /etc/haproxy/haproxyqa.cfg
# from Prod .cfg
bind 10.40.18.88:443 ssl crt /etc/haproxy/certs/www.your-domain.com.crt ca-file /etc/haproxy/certs/ccnr-ca-prod.crt
# from QA .cfg
bind 10.50.18.87:443 ssl crt /etc/haproxy/certs/test.your-domain.com.crt ca-file /etc/haproxy/certs
3. Check CRT cert expiry
# for haproxy-serv02 qa :443 listeners[root@haproxy-serv01 certs]# openssl s_client -connect 10.50.18.87:443 2>/dev/null| openssl x509 -noout -enddate
notAfter=Dec 9 13:24:00 2029 GMT
[root@haproxy-serv01 certs]# openssl x509 -enddate -noout -in /etc/haproxy/certs/www.your-domain.com.crt
notAfter=Aug 12 12:00:00 2022 GMT
[root@haproxy-serv01 certs]# openssl x509 -noout -dates -in /etc/haproxy/certs/www.your-domain.com.crt
notBefore=May 13 00:00:00 2020 GMT
notAfter=Aug 12 12:00:00 2022 GMT
[root@haproxy-serv01 certs]# openssl x509 -noout -dates -in /etc/haproxy/certs/other-domain.your-domain.com.crt
notBefore=Dec 6 13:52:00 2019 GMT
notAfter=Dec 9 13:52:00 2022 GMT
4. Check public website cert expiry in a Chrome / Firefox or Opera browser
In a Chrome browser go to updated URLs:
https://www.your-domain/login
https://test.your-domain/login
https://other-domain.your-domain/login
and check the certs
5. Login to one of haproxy nodes haproxy-serv02 or haproxy-serv01
Check what crm_mon (the cluster resource manager) reports of the consistancy of cluster and the belonging members
you should get some output similar to below:
[root@haproxy-serv01 certs]# crm_mon
Stack: corosync
Current DC: haproxy-serv01 (version 1.1.23-1.el7_9.1-9acf116022) – partition with quorum
Last updated: Fri Jul 15 16:39:17 2022
Last change: Thu Jul 14 17:36:17 2022 by root via cibadmin on haproxy-serv012 nodes configured
6 resource instances configuredOnline: [ haproxy-serv01 haproxy-serv02 ]
Active resources:
ccnrprodlbvip (ocf::heartbeat:IPaddr2): Started haproxy-serv01
ccnrqalbvip (ocf::heartbeat:IPaddr2): Started haproxy-serv01
Clone Set: haproxyqa-clone [haproxyqa]
Started: [ haproxy-serv01 haproxy-serv02 ]
Clone Set: haproxyprod-clone [haproxyprod]
Started: [ haproxy-serv01 haproxy-serv02 ]
6. Create backup of existing certificates before proceeding to regenerate expiring
On both haproxy-serv01 / haproxy-serv02 run:
# cp -vrpf /etc/haproxy/certs/ /home/username/etc-haproxy-certs_bak_$(date +%d_%y_%m)/
7. Find the .key file etract it from latest version of file CCNR-Certificates-DB.xdb
Extract passes from XCA cert manager (if you're already using XCA if not take the certificate from keypass or wherever you have stored it.
+ For XCA cert manager ccnrlb pass
Find the location of the certificate inside the .xdb place etc.
+++++ www.your-domain.com.key file +++++
—–BEGIN PUBLIC KEY—–
…
—–END PUBLIC KEY—–
# Extracted from old file /etc/haproxy/certs/www.your-domain.com.crt
—–BEGIN RSA PRIVATE KEY—–
…
—–END RSA PRIVATE KEY—–
+++++
8. Renew Generate CSR out of RSA PRIV KEY and .CRT
[root@haproxy-serv01 certs]# openssl x509 -noout -fingerprint -sha256 -inform pem -in www.your-domain.com.crt
SHA256 Fingerprint=24:F2:04:F0:3D:00:17:84:BE:EC:BB:54:85:52:B7:AC:63:FD:E4:1E:17:6B:43:DF:19:EA:F4:99:L3:18:A6:CD# for haproxy-serv01 prod :443 listeners
[root@haproxy-serv02 certs]# openssl x509 -x509toreq -in www.your-domain.com.crt -out www.your-domain.com.csr -signkey www.your-domain.com.key
9. Move (Standby) traffic from haproxy-serv01 to ccnrl0b2 to test cert works fine
[root@haproxy-serv01 certs]# pcs cluster standby haproxy-serv01
10. Proceed the same steps on haproxy-serv01 and if ok unstandby
[root@haproxy-serv01 certs]# pcs cluster unstandby haproxy-serv01
11. Check all is fine with openssl client with new certificate
Check Root-Chain certificates:
# openssl verify -verbose -x509_strict -CAfile /etc/haproxy/certs/ccnr-ca-prod.crt -CApath /etc/haproxy/certs/other-domain.your-domain.com.crt{.pem?)
/etc/haproxy/certs/other-domain.your-domain.com.crt: OK
# openssl verify -verbose -x509_strict -CAfile /etc/haproxy/certs/thawte-ca.crt -CApath /etc/haproxy/certs/www.your-domain.com.crt
/etc/haproxy/certs/www.your-domain.com.crt: OK
################# For other-domain.your-domain.com.crt ##############
Do the same
12. Check cert expiry on /etc/haproxy/certs/other-domain.your-domain.com.crt
# for haproxy-serv02 qa :15443 listeners
[root@haproxy-serv01 certs]# openssl s_client -connect 10.40.18.88:15443 2>/dev/null| openssl x509 -noout -enddate
notAfter=Dec 9 13:52:00 2022 GMT
[root@haproxy-serv01 certs]# openssl x509 -enddate -noout -in /etc/haproxy/certs/other-domain.your-domain.com.crt
notAfter=Dec 9 13:52:00 2022 GMT
Check also for
+++++ other-domain.your-domain.com..key file +++++
—–BEGIN PUBLIC KEY—–
…
—–END PUBLIC KEY—–
# Extracted from /etc/haproxy/certs/other-domain.your-domain.com.crt
—–BEGIN RSA PRIVATE KEY—–
…
—–END RSA PRIVATE KEY—–
+++++
13. Standby haproxy-serv01 node 1
[root@haproxy-serv01 certs]# pcs cluster standby haproxy-serv01
14. Renew Generate CSR out of RSA PRIV KEY and .CRT for second domain other-domain.your-domain.com
# for haproxy-serv01 prod :443 renew listeners
[root@haproxy-serv02 certs]# openssl x509 -x509toreq -in other-domain.your-domain.com.crt -out domain-certificate.com.csr -signkey domain-certificate.com.key
And repeat the same steps e.g. fill the CSR inside the domain registrer and get the certificate and move to the proxy, check the fingerprint if necessery
[root@haproxy-serv01 certs]# openssl x509 -noout -fingerprint -sha256 -inform pem -in other-domain.your-domain.com.crt
SHA256 Fingerprint=60:B5:F0:14:38:F0:1C:51:7D:FD:4D:C1:72:EA:ED:E7:74:CA:53:A9:00:C6:F1:EB:B9:5A:A6:86:73:0A:32:8D
15. Check private key's SHA256 checksum
# openssl pkey -in terminals-priv.KEY -pubout -outform pem | sha256sum
# openssl x509 -in other-domain.your-domain.com.crt -pubkey -noout -outform pem | sha256sum
# openssl pkey -in www.your-domain.com.crt-priv-KEY -pubout -outform pem | sha256sum
# openssl x509 -in www.your-domain.com.crt -pubkey -noout -outform pem | sha256sum
16. Check haproxy config is okay before reload cert
# haproxy -c -V -f /etc/haproxy/haproxyprod.cfg
Configuration file is valid
# haproxy -c -V -f /etc/haproxy/haproxyqa.cfg
Configuration file is valid
Good so next we can the output of status of certificate
17.Check old certificates are reachable via VIP IP address
Considering that the cluster VIP Address is lets say 10.40.18.88 and running one of the both nodes cluster to check it do something like:
# curl -vvI https://10.40.18.88:443|grep -Ei 'start date|expire date'
…
As output you should get the old certificate
18. Reload Haproxies for Prod and QA on node1 and node2
You can reload the haproxy clusters processes gracefully something similar to kill -HUP but without loosing most of the current established connections with below cmds:
Login on node1 (haproxy-serv01) do:
# /usr/sbin/haproxy -f /etc/haproxy/haproxyprod.cfg -D -p /var/run/haproxyprod.pid -sf $(cat /var/run/haproxyprod.pid)
# /usr/sbin/haproxy -f /etc/haproxy/haproxyqa.cfg -D -p /var/run/haproxyqa.pid -sf $(cat /var/run/haproxyqa.pid)
repeat the same commands on haproxy-serv02 host
19.Check new certificates online and the the haproxy logs
# curl -vvI https://10.50.18.88:443|grep -Ei 'start date|expire date'
…
* start date: Jul 15 08:19:46 2022 GMT
* expire date: Jul 15 08:19:46 2025 GMT
…
You should get the new certificates Issueing start date and expiry date.
On both nodes (if necessery) do:
# tail -f /var/log/haproxy.log
…










