I've earlier blogged on how to install and play old arcade games with xmame compiled from source on the now old Debian 7 Linux under the article Install xmame from source on Debian Linux 7.0 (Wheezy) to play for better MAME (Arcade Games Emulation)
as well article on using the newer version of MAME emulator instead of xmame under the article Playing Arcade old school games on Debian Linux as well as how to make the MAME emulator work with a joystick see my previous How to configure Joystick ( Gamepad ) on Debian, Ubuntu, Mint GNU / Linux easily.
Since I have preinstalled my notebook with fresh Debian 10 Buster, for a long time I did not have the time as well as desire to play my favourite games of the youth to name a few this is Xain'd Sleena / Cadillacs and Dinosaurs (1993) / the Punisher (1993) / Captain Commando (1991) / Super Mario / Contra / Final Fight etc. and rest of the the SEGA Mega Drive / GameBoy / Nintendo / Terminator game (fake clone of nintendo) and other killing Arcade Classics of the late 90s and early year 2000, which we played on a public houses on a game cabinets with a joysticks.
Hence I tried to reproduce some of my articles just as of 2021 to see whether still we can get a nice playable MAME emulator on Linux with a Graphical GUI for Mate or GNOME. And it seems using a straight mame out of Debian standard repositories did not work with some of the more sophisticated ROM .zip files from the nices such as Punisher or XSLEENA.zip, this is how this article got born in an attempt to give a way for such old school game freaks as me to be able to play there favorite games of the youth.
Below is the few steps adapted mostly from above articles with some head banging and loosing multiple hours wondering until I finally got a working XMAME ROM emulator with the simple but working GXMAME graphical frontend for M.A.M.E..
To compile xmame with joystick support be it analog or whatever joystick you have to use a Makefile like below
https://www.pc-freak.net/files/xmame-0.103-Makefile-for-joystick
Copy it on your PC and remove it to Makefile in the xmame-0.103 source dir:
# cd /usr/local/src/xmame-0.103
I have to install all the necessery package dependencies development header files, some of which are mentioned in the beginning of post articles and some of which I had to install manually, such as the preset Debian meta-package build-essentials Things to install on newly installed GNU / Linux (My favourite must have Linux text and GUI programs missing in fresh Linux installs), just to mention a few I remember had to install based on some compilation errors:
# apt-get install build-essential
# apt-get install –yes zlib1g-dev
# apt-get install –yes libexpat1-dev
# apt-get install –yes libghc-x11-dev
# apt-get install –yes x11proto-video-dev
# apt-get install –yes libxv-dev
# apt-get install libxext6
# apt-get install libxext6-dev
# apt-get install libxext-dev
# apt-get install libjpeg62-turbo-dev
# apt-get install libxinerama-dev
# apt-get install libgtk-3-dev
# apt-get install syslog-ng-dev
# apt-get install libgtk2.0-dev
If I'm missing some package necessery here you will have to find it yourself based on the *.h file produced as error during compile you should look it up with a cmd like:
# apt-file search glib2.h
And install it further.
You will need to edit Makefile or take and straight use or if necessery adapt an already prepared Makefile for my purpose:
# wget https://www.pc-freak.net/files/xmame-0.103-Makefile-for-joystick;
# mv https://www.pc-freak.net/files/xmame-0.103-Makefile-for-joystick Makefile
# make && make install
Some .zip roms does not properly work with the newer mame you need to instead use xmame ..
Below is the version I use on Debian 10 as of May 2021 year.
hipo@jeremiah:/usr/local/src$ xmame –version
GLINFO: loaded OpenGL library libGL.so!
GLINFO: loaded GLU library libGLU.so!
xmame (x11) version 0.103 (May 13 2021)
To make the joystick work in xmame you will need to have a preset of modules loaded on the Linux for my old Genius joystick this is what works.
hipo@jeremiah:~/Games$ cat /etc/modules
# /etc/modules: kernel modules to load at boot time.
#
# This file contains the names of kernel modules that should be loaded
# at boot time, one per line. Lines beginning with "#" are ignored.
snd-seq
3c59x
snd-emu10k1
snd-pcm-oss
snd-mixer-oss
snd-seq-oss
joydev
ns558
sidewinder
gameport
analog
adi
pcigame
iforce
evdev
usbhid
Fill in your joystick module there and make sure you manually load each one of the modules with modprobe command.
Next calibrate the joystick with some tool like jktest-gtk
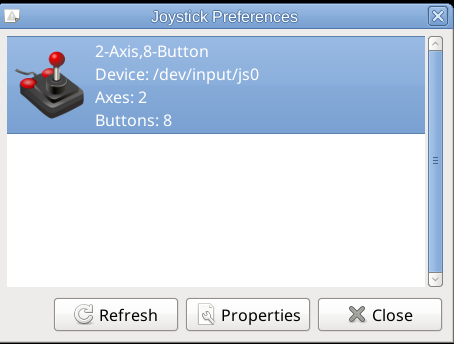
If you need a good frontend for MATE / GNOME for xmame try gxmame. It is a real pain in the ass to configure, note that the only working version of xmame with good configuration as well as gxmame with a game list that is prebuild.
If you need xmame-0.103.tar.bz2 exact xmame version I'm using thethe archive is on:
https://www.pc-freak.net/files/xmame-0.103.tar.bz2
An old bundle of both gxmame and xmamerc configs is here
https://www.pc-freak.net/files/xmame.tar.gz
https://www.pc-freak.net/files/xmame-config-for-joystick-hipo.tar.gz
For example my old working version of xmame ~/.xmame is here https://www.pc-freak.net/files/xmame-config-for-joystick-hipo.tar.gz
Configuration of gxmame (even though it has has a GUI for configuring is below:
https://www.pc-freak.net/files/gxmame.tar.gz
xmamerc sample working file is here
https://www.pc-freak.net/files/xmamerc
My newest current version as of Debian 10 Squeeze of xmame and gxmame is below:
https://www.pc-freak.net/files/gxmame-config-newest_may_2021.tar.gz
https://www.pc-freak.net/files/xmame-config-newest_may_2021.tar.gz
Note that my rom files and stuff is located and configured in neewst configs to be under /home/hipo/Games/roms/ if your location is others grep it in .xmame/* and .gxmame/* files and set the correct PATH locations.
A VERY IMPORTANT NOTE is not to use the stable version of GXMAME even though it worked in 2003 fine as the project is abandoned and unsupported as of 2021 the latest downloadable stable gxmame file on Sourceforge gxmame-0.34b website is not working correctly (even though it compiles fine).
You have to compile and use instead the newer version gxmame-0.35beta1.
If you want to use gxmame with a joystick you need to compile it with the respective option:
root@jeremiah:/usr/local/src/gxmame-0.35beta1# ./configure –enable-joystick
…
gxmame 0.35beta1
Print debugging messages…… : no
Joystick support………….. : yesGXMame will be installed in /usr/local/bin.
Warning: You have an old copy of gxmame at /usr/local/bin/gxmame.
configure complete, now type 'make'
To install compiled binaries do the usual:
# make && make install
gxmame binary should be installed under /usr/local/bin/gxmame once launched you should get the shiny gxmame GUI.
Perhaps there was other stuff I've done in the process I forgot to document here, so if you try to follow my guide and something does not work please tell me what I'm missing and you can't handle it either contact me.
The guide is for Debian Linux but should work on other .Deb based Linux distros such as Ubuntu / Linux Mint etc.
To enjoy my 4GB present of ROM files containing many of best well known M.A.M.E. ARCADE GAMES check archive here. Note that this collection was downloaded on the Internet and I do not hold any responsibility of the archive. If it contains files with any copyright infringment this is to be on your own.