Posts Tagged ‘HTTP’
Monday, July 9th, 2012 
2 of the wordpress installations, I take care for had been reported an annoying bug today by some colleagues.
The bug consisted in double trailing slash at the end of the domain url e.g.;
http://our-company-domainname.com//
As a result in the urls everywhere there was the double trailing slash appearing i.e.::
http://our-company-domainname.com//countact-us/
http://our-company-domainname.com//languages/
etc.
The bug was reported to happen in the multiolingual version of the wordpress based sites, as the Qtranslate plugin is used on this installations to achieve multiple languages it seemed at first logical that the double slash domain and url wordpress issues are caused for some reason by qTranslate.
Therefore, I initially looked for the cause of the problem, within the wordpress admin settings for qTranslate plugin. After not finding any clue pointing the bug to be related to qTranslate, I've then checked the settings for each individual wordpress Page and Post (There in posts usually one can manually set the exact url pointing to each post and page).
The double slash appeared also in each Post and Page and it wasn't possible to edit the complete URL address to remove the double trailin slashes. My next assumption was the cause for the double slash appearing on each site link is because of something wrong with the sites .htaccess, therefore I checked in the wp main sites directory .htaccess
Strangely .htacces seemed OKAY and there was any rule that somehow might lead to double slashes in URL. WP-sites .htaccess looked like so:
server:/home/wp-site1/www# cat .htaccess
RewriteEngine On
RewriteBase /
# Rewrite rules for new content and scripts folder
RewriteRule ^jscripts/(.*)$ wp-includes/js/$1
RewriteRule ^gallery/(.*)$ wp-content/uploads/$1
RewriteRule ^modules/(.*)$ wp-content/plugins/$1
RewriteRule ^gui/(.*)/(.*)$ wp-content/themes/$1/$2 [L]
# Disable direct acceees to wp files if referer is not valid
#RewriteCond %{THE_REQUEST} .wp-*
#RewriteCond %{REQUEST_URI} .wp-*
#RewriteCond %{REQUEST_URI} !.*media-upload.php.*
#RewriteCond %{HTTP_REFERER} !.*cadia.*
#RewriteRule . /error404 [L]
# Standard WordPress rewrite
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule . /index.php [L]
Onwards, I thought a possible way to fix bug by adding mod_rewrite rules in .htaccess which would do a redirect all requests to http://www.our-company-domainname.com//contact-us/ to http://www.our-company-domainname.com//contact-us/ etc. like so:
RewriteRule ^/(.*)$ /$1
This for unknown reasons to me didn't worked either, finally thanks God I remembered to check the variables in wp-config.php (some month ago or so I added there some variables in order to improve the wordpress websites opening times).
I've figured out I did a mistake in one of the variables by adding an ending slash to the URL. The variable added was:
define('WP_HOME','http://our-company-domainname.com/');
whether instead it should be without the ending trailing slash like so:
define('WP_HOME','http://our-company-domainname.com');
By removing the ending trailing slash:
define('WP_HOME','http://our-company-domainname.com/');
to:
define('WP_HOME','http://our-company-domainname.com');
fixed the issue.
Cheers 😉
Tags: annoying bug, assumption, Auto, care, cause, clue, colleagues, content themes, Draft, exact url, FILENAME, folderRewriteRule, GUI, HTTP, index, languages, mod, nbsp, Onwards, page, php, plugin, reason, referer, rewrite, RewriteCond, RewriteEngine, RewriteRule, scripts, slashes, something, standard, Strangely, url address, URLs, Wordpress, wp, WP-sites, www cat
Posted in System Administration, Wordpress | No Comments »
Friday, April 27th, 2012 The last days, I'm starting to think the GUI use is making me brainless so I'm getting back to my old habits of using console.
I still remember with a grain of nostalgy how much more efficient I used to be when the way to interact with my computer was primary in text mode console.
Actually, I'm starting to get this idea the more new a software is the more inefficient it makes your use of computer, not to mention the hardware resources required by newer software is constantly increasing.
With this said, I started occasionally browsing again like in the old days by using links text browser.
In the old days I mostly used lynx and its more advanced "brother" text browser links.
The main difference between lynx and links is that lynx does not have any support for the terrible "javascript", whether links supports most of the Javascript ver 2.
Also links and has a midnight commander like pull down menus on the screen top, – handy for people who prefer some more interactivity.
In the past I remember I used also to browse graphically in normal consoles (ttys) with a hacked version of links calledTThere is also a variation of links – xlinks suitable for people who would like to have graphical browser in console (ttys).
I used xlinks quite heavily in the past, when I have slower computer P166Mhz with 64MB of memory 2.5 GB HDD (What a times boy what a times) .
Maybe when I have time I will install it on my PC and start using it again like in the old days to boost my computer use efficiency…
I remember the only major xlinks downside was it doesn't included support for Adobe flash (though this is due to the bad non-free software nature of Adobe lack of proper support for free software and not a failure of xlinks developers. Anyways for me this wasn't a big trouble since, ex Macromedia (Adobe) Flash support is not something essential for most of my work…
links2 is actually the naming of links version 2. elinks emerged later (if I remember correctly, as fork project of links).
elinks difference with links constitutes in this it supports tabbed browsing as well as colors (links browser displays results monochrome).
Having a tabbed browsing support in tty console is a great thing…
I personally belive text browsing if properly used can in many ways outbeat, graphic browsing in terms of performance and time spend to obtain data. I'm convinced text browsing is superior for two reasons:
1. with text there is way less elements to obstruct your attention.
– No graphical annoying flash banners, no annoying taking the attention pictures
2. Navigating in web pages using the keyboard is more efficient than mouse
– Using keyboard shorcuts is always quicker than mouse, generally keboard has always been a quicker way to access computer commands.
Another reason to use text browsing is, it is mostly the text part of a page that matters, most of the pages that provide images to better explain a topic are bloated (this is my personal view though, i'm sure designer guys will argue me :D).
Here is a screenshot of a my links text browser in action, I'm sorry the image is a bit unreadable, but after taking a screenshot of the console and resizing it with GIMP this is what I got …
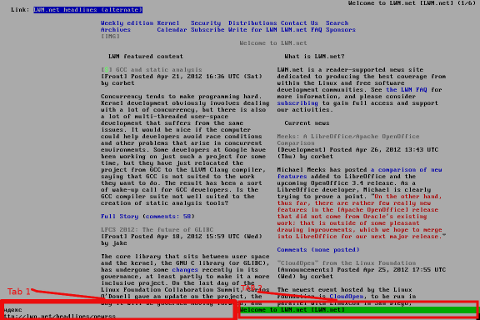
For all those new to Linux who didn't tried text browsing yet and for those interested in computer history, I suggest you install and give a try to following text browsers:
- lynx
(Supports colorful text console text browsing)
- links
- elinks
(Supports colors filled text browsing and tabs)
- w3m
By the way having the 4 text browsers is very useful for debugging purposes for system administrators too, so in any case I think this 4 web browsers are absoutely required software for newly installed GNU / Linux or BSD* based servers.
For Debian and the derivatives Linux distributions, the 4 browsers are available as deb packages, so install them with following apt 1 liner:
debian:~# apt-get –yes install w3m elinks links lynx
….
FreeBSD users can install the browsers using, cmd:
freebsd# cd /usr/ports/www/w3mfreebsd# make install clean
….
freebsd# cd /usr/ports/www/elinksfreebsd# make install clean
….
freebsd# cd /usr/ports/www/linksfreebsd# make install clean
….
freebsd# cd /usr/ports/www/lynxfreebsd# make install clean
….
In links using the tabs functionality appeared, somewhere near the 2001 or 2000 (at least that was the first time I saw links with tabbed browsing enabled). My first time to saw links support opening multiple pages within the same screen under tabs was on Redhat Linux 9
Opening multiple pages in tabs in the text browser is done by pressing the t key and typing in the desired URL to open isnide.
For more than 2 tabs, again t has to be pressed and same procedure goes on and on.
It was pretty hard for me to figure out how I can do a text browsing with tabs, though I found a way to open new tabs it took me some 10 minutes in pondering how to switch between the new opened links browser tabs.
Hence, I thought it would be helpful to mention here how tabs can be switched in links text browser. Actually it turned it is pretty easy to Switch tabs tabs back and foward.
1 tab to move backwards is done with < (key), wheter switching one tab forward is done with the > key.
On UK and US qwerty keyboards alignment the movement a tab backward and forward is done with holding shift and pressing < onwards holding both keys simultaneously and analogously with pressing shift + >
Tags: Auto, big trouble, calledTThere, computer use, doesn, downside, Draft, elinks, flash support, freebsd servers, gb hdd, graphical browser, hardware resources, hdd, HTTP, interactivity, Javascript, Lack, last days, Lynx, Midnight, midnight commander, nature, nbsp, nostalgy, old habits, pull, pull down menus, quot, screen, screenshot, slower computer, software, software nature, support, Supports, text browser, text browsers, text mode, time, variation, xlinks
Posted in FreeBSD, Linux, System Administration, Web and CMS | 5 Comments »
Friday, March 30th, 2012 While browsing I stumbled upon a nice blog article
Dumping HTTP headers
The arcitle, points at few ways to DUMP the HTTP headers obtained from user browser.
As I'm not proficient with Ruby, Java and AOL Server what catched my attention is a tiny php for loop, which loops through all the HTTP_* browser set variables and prints them out. Here is the PHP script code:
<?php<br />
foreach($_SERVER as $h=>$v)<br />
if(ereg('HTTP_(.+)',$h,$hp))<br />
echo "<li>$h = $v</li>\n";<br />
header('Content-type: text/html');<br />
?>
The script is pretty easy to use, just place it in a directory on a WebServer capable of executing php and save it under a name like:
show_HTTP_headers.php
If you don't want to bother copy pasting above code, you can also download the dump_HTTP_headers.php script here , rename the dump_HTTP_headers.php.txt to dump_HTTP_headers.php and you're ready to go.
Follow to the respective url to exec the script. I've installed the script on my webserver, so if you are curious of the output the script will be returning check your own browser HTTP set values by clicking here.
PHP will produce output like the one in the screenshot you see below, the shot is taken from my Opera browser:
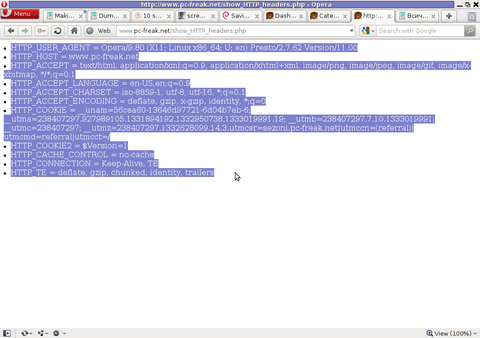
Another sample of the text output the script produce whilst invoked in my Epiphany GNOME browser is:
HTTP_HOST = www.pc-freak.net
HTTP_USER_AGENT = Mozilla/5.0 (X11; U; Linux x86_64; en-us) AppleWebKit/531.2+ (KHTML, like Gecko) Version/5.0 Safari/531.2+ Debian/squeeze (2.30.6-1) Epiphany/2.30.6
HTTP_ACCEPT = application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
HTTP_ACCEPT_ENCODING = gzip
HTTP_ACCEPT_LANGUAGE = en-us, en;q=0.90
HTTP_COOKIE = __qca=P0-2141911651-1294433424320;
__utma_a2a=8614995036.1305562814.1274005888.1319809825.1320152237.2021;wooMeta=MzMxJjMyOCY1NTcmODU1MDMmMTMwODQyNDA1MDUyNCYxMzI4MjcwNjk0ODc0JiYxMDAmJjImJiYm; 3ec0a0ded7adebfeauth=22770a75911b9fb92360ec8b9cf586c9;
__unam=56cea60-12ed86f16c4-3ee02a99-3019;
__utma=238407297.1677217909.1260789806.1333014220.1333023753.1606;
__utmb=238407297.1.10.1333023754; __utmc=238407297;
__utmz=238407297.1332444980.1586.413.utmcsr=www.pc-freak.net|utmccn=(referral)|utmcmd=referral|utmcct=/blog/
You see the script returns, plenty of useful information for debugging purposes:
HTTP_HOST – Virtual Host Webserver name
HTTP_USER_AGENT – The browser exact type useragent returnedHTTP_ACCEPT – the type of MIME applications accepted by the WebServerHTTP_ACCEPT_LANGUAGE – The language types the browser has support for
HTTP_ACCEPT_ENCODING – This PHP variable is usually set to gzip or deflate by the browser if the browser has support for webserver returned content gzipping.
If HTTP_ACCEPT_ENCODING is there, then this means remote webserver is configured to return its HTML and static files in gzipped form.
HTTP_COOKIE – Information about browser cookies, this info can be used for XSS attacks etc. 🙂
HTTP_COOKIE also contains the referrar which in the above case is:
__utmz=238407297.1332444980.1586.413.utmcsr=www.pc-freak.net|utmccn=(referral)
The Cookie information HTTP var also contains information of the exact link referrar:
|utmcmd=referral|utmcct=/blog/
For the sake of comparison show_HTTP_headers.php script output from elinks text browser is like so:
* HTTP_HOST = www.pc-freak.net
* HTTP_USER_AGENT = Links (2.3pre1; Linux 2.6.32-5-amd64 x86_64; 143x42)
* HTTP_ACCEPT = */*
* HTTP_ACCEPT_ENCODING = gzip,deflate * HTTP_ACCEPT_CHARSET = us-ascii, ISO-8859-1, ISO-8859-2, ISO-8859-3, ISO-8859-4, ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8, ISO-8859-9, ISO-8859-10, ISO-8859-13, ISO-8859-14, ISO-8859-15, ISO-8859-16, windows-1250, windows-1251, windows-1252, windows-1256,
windows-1257, cp437, cp737, cp850, cp852, cp866, x-cp866-u, x-mac, x-mac-ce, x-kam-cs, koi8-r, koi8-u, koi8-ru, TCVN-5712, VISCII,utf-8 * HTTP_ACCEPT_LANGUAGE = en,*;q=0.1
* HTTP_CONNECTION = keep-alive
One good reason, why it is good to give this script a run is cause it can help you reveal problems with HTTP headers impoperly set cookies, language encoding problems, security holes etc. Also the script is a good example, for starters in learning PHP programming.
Tags: AOL, arcitle, article, attention, Auto, blog, browser, code, code lt, content type, copy, debugging, download, Draft, dump, Dumping, ENCODING, ereg, freak, gecko, Gnome, gzip, host, host www, HTTP, image png, information, Java, khtml, linux x86, loop, nbsp, opera browser, php, php script, php txt, place, prints, quot, ruby, Safari, screenshot, script, script code, server, set variables, shot, show, squeeze, support, text, Tiny, type, unam, User, utmb, utmcsr, xml
Posted in Programming, System Administration | No Comments »
Monday, March 19th, 2012 
One of the company Debian Lenny 5.0 Webservers, where I'm working as sys admin sometimes stops to properly server HTTP requests.
Whenever this oddity happens, the Apache server seems to be running okay but it is not failing to return requested content
I can see the webserver listens on port 80 and establishing connections to remote hosts – the apache processes show normally as I can see in netstat …:
apache:~# netstat -enp 80
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 xxx.xxx.xxx.xx:80 46.253.9.36:5665 SYN_RECV 0 0 -
tcp 0 0 xxx.xxx.xxx.xx:80 78.157.26.24:5933 SYN_RECV 0 0 -
...
Also the apache forked child processes show normally in process list:
apache:~# ps axuwwf|grep -i apache
root 46748 0.0 0.0 112300 872 pts/1 S+ 18:07 0:00 \_ grep -i apache
root 42530 0.0 0.1 217392 6636 ? Ss Mar14 0:39 /usr/sbin/apache2 -k start
www-data 42535 0.0 0.0 147876 1488 ? S Mar14 0:01 \_ /usr/sbin/apache2 -k start
root 28747 0.0 0.1 218180 4792 ? Sl Mar14 0:00 \_ /usr/sbin/apache2 -k start
www-data 31787 0.0 0.1 219156 5832 ? S Mar14 0:00 | \_ /usr/sbin/apache2 -k start
In spite of that, in any client browser to any of the Apache (Virtual hosts) websites, there is no HTML content returned…
This weird problem continues until the Apache webserver is retarted.
Once webserver is restarted everything is back to normal.
I use Apache Check Apache shell script set on few remote hosts to regularly check with nmap if port 80 (www) of my server is open and responding, anyways this script just checks if the open and reachable and thus using it was unable to detect Apache wasn't able to return back HTML content.
To work around the malfunctions I wrote tiny script – retart_apache_if_empty_content_is_returned.sh
The scripts idea is very simple;
A request is made a remote defined host with lynx text browser, then the output of lines is counted, if the output returned by lynx -dump http://someurl.com is less than the number returned whether normally invoked, then the script triggers an apache init script restart.
I've set the script to periodically run in a cron job, every 5 minutes each hour.
# check if apache returns empty content with lynx and if yes restart and log it
*/5 * * * * /usr/sbin/restart_apache_if_empty_content.sh >/dev/null 2>&1
This is not perfect as sometimes still, there will be few minutes downtime, but at least the downside will not be few hours until I am informed ssh to the server and restart Apache manually …
A quick way to download and set from cron execution my script every 5 minutes use:
apache:~# cd /usr/sbin
apache:/usr/sbin# wget -q https://www.pc-freak.net/bscscr/restart_apache_if_empty_content.sh
apache:/usr/sbin# chmod +x restart_apache_if_empty_content.sh
apache:/usr/sbin# crontab -l > /tmp/file; echo '*/5 * * * *' /usr/sbin/restart_apache_if_empty_content.sh 2>&1 >/dev/null
Tags: address state, apache processes, apache server, apache webserver, apache2, apacheroot, Auto, checks, child processes, client, client browser, content, cron, Draft, enp, everything, grep, HTML, HTTP, internet connections, lenny, Lynx, nmap, oddity, program, proto, Restart, restart apache, root, script, scripts, Shell, shell script, show, spite, ss, SYN, User, Virtual, virtual hosts, webservers, weird problem
Posted in System Administration, Web and CMS | 7 Comments »
Monday, March 12th, 2012 
One of the WordPress websites hosted on our dedicated server produces all the time a wp-cron.php 404 error messages like:
xxx.xxx.xxx.xxx - - [15/Apr/2010:06:32:12 -0600] "POST /wp-cron.php?doing_wp_cron HTTP/1.0
I did not know until recently, whatwp-cron.php does, so I checked in google and red a bit. Many of the places, I've red are aa bit unclear and doesn't give good exlanation on what exactly wp-cron.php does. I wrote this post in hope it will shed some more light on wp-config.php and how this major 404 issue is solved..
So
what is wp-cron.php doing?
- wp-cron.php is acting like a cron scheduler for WordPress.
- wp-cron.php is a wp file that controls routine actions for particular WordPress install.
- Updates the data in SQL database on every, request, every day or every hour etc. – (depending on how it's set up.).
- wp-cron.php executes automatically by default after EVERY PAGE LOAD!
- Checks all pending comments for spam with Akismet (if akismet or anti-spam plugin alike is installed)
- Sends all scheduled emails (e.g. sent a commentor email when someone comments on his comment functionality, sent newsletter subscribed persons emails etc.)
- Post online scheduled articles for a day and time of particular day
Suppose you're writting a new post and you want to take advantage of WordPress functionality to schedule a post to appear Online at specific time:
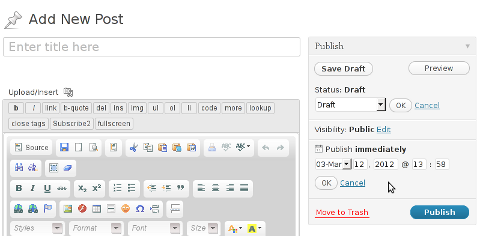
The Publish Immediately, field execution is being issued on the scheduled time thanks to the wp-cron.php periodic invocation.
Another example for wp-cron.php operation is in handling flushing of WP old HTML Caches generated by some wordpress caching plugin like W3 Total Cache
wp-cron.php takes care for dozens of other stuff silently in the background. That's why many wordpress plugins are depending heavily on wp-cron.php proper periodic execution. Therefore if something is wrong with wp-config.php, this makes wordpress based blog or website partially working or not working at all.
Our company wp-cron.php errors case
In our case the:
212.235.185.131 – – [15/Apr/2010:06:32:12 -0600] "POST /wp-cron.php?doing_wp_cron HTTP/1.0" 404
is occuring in Apache access.log (after each unique vistor request to wordpress!.), this is cause wp-cron.php is invoked on each new site visitor site request.
This puts a "vain load" on the Apache Server, attempting constatly to invoke the script … always returning not found 404 err.
As a consequence, the WP website experiences "weird" problems all the time. An illustration of a problem caused by the impoper wp-cron.php execution is when we are adding new plugins to WP.
Lets say a new wordpress extension is download, installed and enabled in order to add new useful functioanlity to the site.
Most of the time this new plugin would be malfunctioning if for example it is prepared to add some kind of new html form or change something on some or all the wordpress HTML generated pages.
This troubles are result of wp-config.php's inability to update settings in wp SQL database, after each new user request to our site.
So the newly added plugin website functionality is not showing up at all, until WP cache directory is manually deleted with rm -rf /var/www/blog/wp-content/cache/…
I don't know how thi whole wp-config.php mess occured, however my guess is whoever installed this wordpress has messed something in the install procedure.
Anyways, as I researched thoroughfully, I red many people complaining of having experienced same wp-config.php 404 errs. As I red, most of the people troubles were caused by their shared hosting prohibiting the wp-cron.php execution.
It appears many shared hostings providers choose, to disable the wordpress default wp-cron.php execution. The reason is probably the script puts heavy load on shared hosting servers and makes troubles with server overloads.
Anyhow, since our company server is adedicated server I can tell for sure in our case wordpress had no restrictions for how and when wp-cron.php is invoked.
I've seen also some posts online claiming, the wp-cron.php issues are caused of improper localhost records in /etc/hosts, after a thorough examination I did not found any hosts problems:
hipo@debian:~$ grep -i 127.0.0.1 /etc/hosts
127.0.0.1 localhost.localdomain localhost
You see from below paste, our server, /etc/hosts has perfectly correct 127.0.0.1 records.
Changing default way wp-cron.php is executed
As I've learned it is generally a good idea for WordPress based websites which contain tens of thousands of visitors, to alter the default way wp-cron.php is handled. Doing so will achieve some efficiency and improve server hardware utilization.
Invoking the script, after each visitor request can put a heavy "useless" burden on the server CPU. In most wordpress based websites, the script did not need to make frequent changes in the DB, as new comments in posts did not happen often. In most wordpress installs out there, big changes in the wordpress are not common.
Therefore, a good frequency to exec wp-cron.php, for wordpress blogs getting only a couple of user comments per hour is, half an hour cron routine.
To disable automatic invocation of wp-cron.php, after each visitor request open /var/www/blog/wp-config.php and nearby the line 30 or 40, put:
define('DISABLE_WP_CRON', true);
An important note to make here is that it makes sense the position in wp-config.php, where define('DISABLE_WP_CRON', true); is placed. If for instance you put it at the end of file or near the end of the file, this setting will not take affect.
With that said be sure to put the variable define, somewhere along the file initial defines or it will not work.
Next, with Apache non-root privileged user lets say www-data, httpd, www depending on the Linux distribution or BSD Unix type add a php CLI line to invoke wp-cron.php every half an hour:
linux:~# crontab -u www-data -e
0,30 * * * * cd /var/www/blog; /usr/bin/php /var/www/blog/wp-cron.php 2>&1 >/dev/null
To assure, the php CLI (Command Language Interface) interpreter is capable of properly interpreting the wp-cron.php, check wp-cron.php for syntax errors with cmd:
linux:~# php -l /var/www/blog/wp-cron.php
No syntax errors detected in /var/www/blog/wp-cron.php
That's all, 404 wp-cron.php error messages will not appear anymore in access.log! 🙂
Just for those who can find the root of the /wp-cron.php?doing_wp_cron HTTP/1.0" 404 and fix the issue in some other way (I'll be glad to know how?), there is also another external way to invoke wp-cron.php with a request directly to the webserver with short cron invocation via wget or lynx text browser.
– Here is how to call wp-cron.php every half an hour with lynxPut inside any non-privileged user, something like:
01,30 * * * * /usr/bin/lynx -dump "http://www.your-domain-url.com/wp-cron.php?doing_wp_cron" 2>&1 >/dev/null
– Call wp-cron.php every 30 mins with wget:
01,30 * * * * /usr/bin/wget -q "http://www.your-domain-url.com/wp-cron.php?doing_wp_cron"
Invoke the wp-cron.php less frequently, saves the server from processing the wp-cron.php thousands of useless times.
Altering the way wp-cron.php works should be seen immediately as the reduced server load should drop a bit.
Consider you might need to play with the script exec frequency until you get, best fit cron timing. For my company case there are only up to 3 new article posted a week, hence too high frequence of wp-cron.php invocations is useless.
With blog where new posts occur once a day a script schedule frequency of 6 up to 12 hours should be ok.
Tags: akismet, Auto, caches, checks, commentor, cr, cron, daySuppose, dedicated server, doesn, dozens, Draft, email, error messages, execution, exlanation, file, google, HTML, HTTP, invocation, localhost, nbsp, newsletter, operation, periodic execution, php, plugin, quot, request, scheduler, someone, something, spam, SQL, time, time thanks, Wordpress, wordpress plugins, wp
Posted in System Administration, Web and CMS, Wordpress | 3 Comments »
Thursday, January 31st, 2008 Tell me which ideotic government would create a site based on php and would make the serverunder Windows?
Just Guess ours the Bulgarian ministry of Science and Knowledge has started a new site dedicated to helping graduating school pupils with the Future School-examinationthey have to make.
It’s pretty easy to see that just observe:
jericho% telnet zamaturite.bg 80
Trying 212.122.183.208…
Connected to zamaturite.bg.
Escape character is ‘^]’.
HEAD / HTTP/1.0HTTP/1.1 200 OK
Connection: close
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Date: Wed, 30 Jan 2008 19:10:18 GMT
Content-Type: text/html; charset=UTF-8Server: Apache/2.2.6 (Win32) PHP/5.2.5X-Powered-By: PHP/5.2.5Set-Cookie: PHPSESSID=fn5jtjbet7clrapi0a5e5kgvt7; path=/
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Keep-Alive: timeout=5, max=100
Connection closed by foreign host.
jericho%
Just great our Bulgarian government spend money on buying proprietary software OS to run a Free Software based solution.
This example is pretty examplary of what our country looks like. Sad …
END—–
Tags: Alive, apache 2, bg, bulgarian government, Cache, cache control, charset, content type, Cookie, Date, Expires, Free, free software, future school, government, HEAD, host, HTTP, jtjbet, knowledge, money, php, php 5, proprietary software, school pupils, science, server, Set, software, text, text html, UTF, zamaturite
Posted in Everyday Life, Various | No Comments »
Thursday, June 30th, 2011 
Recently has become publicly known for the serious hole found in all Apache webserver versions 1.3.x and 2.0.x and 2.2.x. The info is to be found inside the security CVE-2011-3192 – https://issues.apache.org/bugzilla/show_bug.cgi?id=51714
Apache remote denial of service is already publicly cirtuculating, since about a week and is probably to be used even more heavily in the 3 months to come. The exploit can be obtained from exploit-db.com a mirror copy of #Apache httpd Remote Denial of Service (memory exhaustion) is for download here
The DoS script is known in the wild under the name killapache.pl
killapache.pl PoC depends on perl ForkManager and thus in order to be properly run on FreeBSD, its necessery to install p5-Parallel-ForkManager bsd port :
freebsd# cd /usr/ports/devel/p5-Parallel-ForkManager
freebsd# make install && make install clean
...
Here is an example of the exploit running against an Apache webserver host.
freebsd# perl httpd_dos.pl www.targethost.com 50
host seems vuln
ATTACKING www.targethost.com [using 50 forks]
:pPpPpppPpPPppPpppPp
ATTACKING www.targethost.com [using 50 forks]
:pPpPpppPpPPppPpppPp
...
In about 30 seconds to 1 minute time the DoS attack with only 50 simultaneous connections is capable of overloading any vulnerable Apache server.
It causes the webserver to consume all the machine memory and memory swap and consequently makes the server to crash in most cases.
During the Denial of Service attack is in action access the websites hosted on the webserver becomes either hell slow or completely absent.
The DoS attack is quite a shock as it is based on an Apache range problem which started in year 2007.
Today, Debian has issued a new versions of Apache deb package for Debian 5 Lenny and Debian 6, the new packages are said to have fixed the issue.
I assume that Ubuntu and most of the rest Debian distrubtions will have the apache's range header DoS patched versions either today or in the coming few days.
Therefore work around the issue on debian based servers can easily be done with the usual apt-get update && apt-get upgrade
On other Linux systems as well as FreeBSD there are work arounds pointed out, which can be implemented to close temporary the Apache DoS hole.
1. Limiting large number of range requests
The first suggested solution is to limit the lenght of range header requests Apache can serve. To implement this work raround its necessery to put at the end of httpd.conf config:
# Drop the Range header when more than 5 ranges.
# CVE-2011-3192
SetEnvIf Range (?:,.*?){5,5} bad-range=1
RequestHeader unset Range env=bad-range
# We always drop Request-Range; as this is a legacy
# dating back to MSIE3 and Netscape 2 and 3.
RequestHeader unset Request-Range
# optional logging.
CustomLog logs/range-CVE-2011-3192.log common env=bad-range
CustomLog logs/range-CVE-2011-3192.log common env=bad-req-range
2. Reject Range requests for more than 5 ranges in Range: header
Once again to implement this work around paste in Apache config file:
This DoS solution is not recommended (in my view), as it uses mod_rewrite to implement th efix and might be additionally another open window for DoS attack as mod_rewrite is generally CPU consuming.
# Reject request when more than 5 ranges in the Range: header.
# CVE-2011-3192
#
RewriteEngine on
RewriteCond %{HTTP:range} !(bytes=[^,]+(,[^,]+){0,4}$|^$)
# RewriteCond %{HTTP:request-range} !(bytes=[^,]+(?:,[^,]+){0,4}$|^$)
RewriteRule .* - [F]
# We always drop Request-Range; as this is a legacy
# dating back to MSIE3 and Netscape 2 and 3.
RequestHeader unset Request-Range
3. Limit the size of Range request fields to few hundreds
To do so put in httpd.conf:
LimitRequestFieldSize 200
4. Dis-allow completely Range headers: via mod_headers Apache module
In httpd.conf put:
RequestHeader unset Range
RequestHeader unset Request-Range
This work around could create problems on some websites, which are made in a way that the Request-Range is used.
5. Deploy a tiny Apache module to count the number of Range Requests and drop connections in case of high number of Range: requests
This solution in my view is the best one, I've tested it and I can confirm on FreeBSD works like a charm.
To secure FreeBSD host Apache, against the Range Request: DoS using mod_rangecnt, one can literally follow the methodology explained in mod_rangecnt.c header:
freebsd# wget http://people.apache.org/~dirkx/mod_rangecnt.c
..
# compile the mod_rangecnt modulefreebsd# /usr/local/sbin/apxs -c mod_rangecnt.c
...
# install mod_rangecnt module to Apachefreebsd# /usr/local/sbin/apxs -i -a mod_rangecnt.la
...
Finally to load the newly installed mod_rangecnt, Apache restart is required:
freebsd# /usr/local/etc/rc.d/apache2 restart
...
I've tested the module on i386 FreeBSD install, so I can't confirm this steps works fine on 64 bit FreeBSD install, I would be glad if I can hear from someone if mod_rangecnt is properly compiled and installed fine also on 6 bit BSD arch.
Deploying the mod_rangecnt.c Range: Header to prevent against the Apache DoS on 64 bit x86_amd64 CentOS 5.6 Final is also done without any pitfalls.
[root@centos ~]# uname -a;
Linux centos 2.6.18-194.11.3.el5 #1 SMP Mon Aug 30 16:19:16 EDT 2010 x86_64 x86_64 x86_64 GNU/Linux
[root@centos ~]# /usr/sbin/apxs -c mod_rangecnt.c
...
/usr/lib64/apr-1/build/libtool --silent --mode=link gcc -o mod_rangecnt.la -rpath /usr/lib64/httpd/modules -module -avoid-version mod_rangecnt.lo
[root@centos ~]# /usr/sbin/apxs -i -a mod_rangecnt.la
...
Libraries have been installed in: /usr/lib64/httpd/modules
...
[root@centos ~]# /etc/init.d/httpd configtest
Syntax OK
[root@centos ~]# /etc/init.d/httpd restart
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
After applying the mod_rangecnt patch if all is fine the memory exhaustion perl DoS script's output should be like so:
freebsd# perl httpd_dos.pl www.patched-apache-host.com 50
Host does not seem vulnerable
All of the above pointed work-arounds are only a temporary solution to these Grave Apache DoS byterange vulnerability , a few days after the original vulnerability emerged and some of the up-pointed work arounds were pointed. There was information, that still, there are ways that the vulnerability can be exploited.
Hopefully in the coming few weeks Apache dev team should be ready with rock solid work around to the severe problem.
In 2 years duration these is the second serious Apache Denial of Service vulnerability after before a one and a half year the so called Slowloris Denial of Service attack was capable to DoS most of the Apache installations on the Net.
Slowloris, has never received the publicity of the Range Header DoS as it was not that critical as the mod_range, however this is a good indicator that the code quality of Apache is slowly decreasing and might need a serious security evaluation.
Tags: apache httpd, apache server, apache webserver, ATTACKING, bugzilla, CentOS, com, config, copy, CustomLog, deb package, denial of service, denial of service attack, dos attack, dos script, download, exploit, freebsd, host, HTTP, info, machine memory, memory exhaustion, minute time, mirror copy, mod, necessery, Netscape, number, perl httpd, poc, pPpPpppPpPPppPpppPp, REJECT, Remote, RewriteCond, script, simultaneous connections, work
Posted in Computer Security, Linux, System Administration | No Comments »
Wednesday, January 4th, 2012 
I have recently blogged how I've installed & configured ejabberd (jabber server) on Debian .
Today I decided to further extend, my previous jabberd installation by installing JWChat a web chat interface frontend to ejabberd (a good substitute for a desktop app like pidgin which allows you to access a jabber server from anywhere)
Anyways for a base of installing JWChat , I used the previously installed debian deb version of ejabberd from the repositories.
I had a lot of troubles until I actually make it work because of some very minor mistakes in following the official described tutorial ejabberd website jwchat install tutorual
The only way I can make jwchat work was by using the install jwchat with ejabberd's HTTP-Bind and file server method
Actually for quite a long time I was not realizing that, there are two ways to install JWChat , so by mistake I was trying to mix up some install instructions from both jwchat HTTP-Bind file server method and JWchat Apache install method …
I've seen many people complaining on the page of Install JWChat using Apache method which seemed to be experiencing a lot of strangle troubles just like the mines when I mixed up the jwchat php scripts install using instructions from both install methods. Therefore my guess is people who had troubles in installing using the Apache method and got the blank page issues while accessing http://jabber.servername.com:5280/http-poll/ as well as various XML Parsing Error: no element found errors on – http://ejabberd.oac.com:5280/http-poll/ is most probably caused by the same install instructions trap I was diluted in.
The steps to make JWChat install using the HTTP-Bind and file server method, if followed should be followed absolutely precisely or otherwise THEY WILL NOT WORK!!!
This are the exact steps I followed to make ejabberd work using the HTTP-Bind file server method :
1. Create directory to store the jwchat Ajax / htmls
debian:~# mkdir /var/lib/ejabberd/www
debian:~# chmod +x /var/lib/ejabberd
debian:~# chmod +x /var/lib/ejabberd/www
2. Modify /etc/ejabberd/ejabberd.cfg and include the following configs
While editting the conf find the section:
{listen,
[
…
Scrolling down you will fine some commented code marked with %% that will read:
{5269, ejabberd_s2s_in, [
{shaper, s2s_shaper},
{max_stanza_size, 131072}
]},
Right after it leave one new line and place the code:
{5280, ejabberd_http, [
{request_handlers, [
{["web"], mod_http_fileserver}
]},
http_bind,
http_poll,
web_admin
]}
]}.
Scrolling a bit down the file, there is a section which says:
%%% =======
%%% MODULES
%%
%% Modules enabled in all ejabberd virtual hosts.
%%
The section below the comments will look like so:
{modules, [ {mod_adhoc, []},
{mod_announce, [{access, announce}]}, % requires mod_adhoc
{mod_caps, []},
{mod_configure,[]}, % requires mod_adhoc
{mod_ctlextra, []},
{mod_disco, []},
%%{mod_echo, [{host, "echo.localhost"}]},
{mod_irc, []},
{mod_last, []},
After the {mod_last, … the following lines should be added:
{mod_http_bind, []},
{mod_http_fileserver, [
{docroot, "/var/lib/ejabberd/www"},
{accesslog, "/var/log/ejabberd/webaccess.log"}
]},
3. Download and extract latest version of jwchat
Of the time of writting the latest version of jwchat is jwchat-1.0 I have mirrored it on pc-freak for convenience:
debian:~# wget https://www.pc-freak.net/files/jwchat-1.0.tar.gz
….
debian:~# cd /var/lib/ejabberd/www
debian:/var/lib/ejabberd/www# tar -xzvf jwchat-1.0.tar.gz
...
debian:/var/lib/ejabberd/www# mv jwchat-1.0 jwchat
debian:/var/lib/ejabberd/www# cd jwchat
4. Choose the language in which you will prefer jwchat web interface to appear
I prefer english as most people would I suppose:
debian:/var/lib/ejabberd/www/jwchat# for a in $(ls *.en); do b=${a%.en}; cp $a $b; done
For other languages change in the small one liner shell script b=${a%.en} (en) to whatever language you will prefer to make primary.After selecting the correct langauge a rm cmd should be issued to get rid of the .js.* and .html.* in other language files which are no longer needed:
debian:/var/lib/ejabberd/www/jwchat# rm *.html.* *.js.*
5. Configure JWChat config.js
Edit /var/lib/ejabberd/www/jwchat/config.js , its necessery to have inside code definitions like:
/* If your Jabber server is jabber.example.org, set this: */
var SITENAME = "jabber.example.org";
/* If HTTP-Bind works correctly, you may want do remove HTTP-Poll here */
var BACKENDS =
[
{
name:"Native Binding",
description:"Ejabberd's native HTTP Binding backend",
httpbase:"/http-bind/",
type:"binding",
servers_allowed:[SITENAME]
}
];
6. Restart EJabberd server to load the new config settings
debian:~# /etc/init.d/ejabberd restart
Restarting jabber server: ejabberd..
7. Test JWChat HTTP-Bind and file server backend
I used elinksand my beloved Epiphany (default gnome browser) which by the way is the browser I use daily to test that the JWChat works fine with the ejabberd.
To test the newly installed HTTP-Bind ejabberd server backend on port 5280 I used URL:
http://jabber.mydomain.com:5280/web/jwchat/I had quite a struggles with 404 not found errors, which I couldn't explain for half an hour. After a thorough examination, I've figured out the reasons for the 404 errors was my stupidity …
The URL http://jabber.mydomain.com:5280/web/jwchat/ was incorrect because I fogrot to move jwchat-1.0 to jwchat e.g. (mv jwchat-1.0 jwchat) earlier explained in that article was a step I missed. Hence to access the web interface of the ejabberd without the 404 error I had to access it via:
http://jabber.mydomain.com:5280/web/jwchat-1.0
Finally it is handy to add a small index.php redirect to redirect to http://jabber.mydomain.com:5280/web/jwchat-1.0/
The php should like so:
<?
php
header( 'Location: http://jabber.mydomain.com:5280/web/jwchat-1.0' ) ;
?>
Tags: ajax, amp, Bind, Binding, config, configure, deb, Desktop, ejabberd, element, exact steps, fil, file, file server, frontend, good, guess, htmls, HTTP, Install, installation, Jabber, jabber server, jwchat, long time, minor mistakes, mistake, mod, nbsp, official, page, php scripts, pidgin, quot, repositories, Scrolling, server method, substitute, time, tutorial, two ways, web chat, work, wwwdebian, xml parsing error
Posted in Linux, Linux and FreeBSD Desktop, System Administration | No Comments »
Tuesday, August 30th, 2011
Recently has become publicly known for the serious hole found in all Apache webserver versions 1.3.x and 2.0.x and 2.2.x. The info is to be found inside the security CVE-2011-3192 – https://issues.apache.org/bugzilla/show_bug.cgi?id=51714
Apache remote denial of service is already publicly cirtuculating, since about a week and is probably to be used even more heavily in the 3 months to come. The exploit can be obtained from exploit-db.com a mirror copy of #Apache httpd Remote Denial of Service (memory exhaustion) is for download here
The DoS script is known in the wild under the name killapache.pl
killapache.pl PoC depends on perl ForkManager and thus in order to be properly run on FreeBSD, its necessery to install p5-Parallel-ForkManager bsd port :
freebsd# cd /usr/ports/devel/p5-Parallel-ForkManager
freebsd# make install && make install clean
...
Here is an example of the exploit running against an Apache webserver host.
freebsd# perl httpd_dos.pl www.targethost.com 50
host seems vuln
ATTACKING www.targethost.com [using 50 forks]
:pPpPpppPpPPppPpppPp
ATTACKING www.targethost.com [using 50 forks]
:pPpPpppPpPPppPpppPp
...
In about 30 seconds to 1 minute time the DoS attack with only 50 simultaneous connections is capable of overloading any vulnerable Apache server.
It causes the webserver to consume all the machine memory and memory swap and consequently makes the server to crash in most cases.
During the Denial of Service attack is in action access the websites hosted on the webserver becomes either hell slow or completely absent.
The DoS attack is quite a shock as it is based on an Apache range problem which started in year 2007.
Today, Debian has issued a new versions of Apache deb package for Debian 5 Lenny and Debian 6, the new packages are said to have fixed the issue.
I assume that Ubuntu and most of the rest Debian distrubtions will have the apache’s range header DoS patched versions either today or in the coming few days.
Therefore work around the issue on debian based servers can easily be done with the usual apt-get update && apt-get upgrade
On other Linux systems as well as FreeBSD there are work arounds pointed out, which can be implemented to close temporary the Apache DoS hole.
1. Limiting large number of range requests
The first suggested solution is to limit the lenght of range header requests Apache can serve. To implement this work raround its necessery to put at the end of httpd.conf config:
# Drop the Range header when more than 5 ranges.
# CVE-2011-3192
SetEnvIf Range (?:,.*?){5,5} bad-range=1
RequestHeader unset Range env=bad-range
# We always drop Request-Range; as this is a legacy
# dating back to MSIE3 and Netscape 2 and 3.
RequestHeader unset Request-Range
# optional logging.
CustomLog logs/range-CVE-2011-3192.log common env=bad-range
CustomLog logs/range-CVE-2011-3192.log common env=bad-req-range
2. Reject Range requests for more than 5 ranges in Range: header
Once again to implement this work around paste in Apache config file:
This DoS solution is not recommended (in my view), as it uses mod_rewrite to implement th efix and might be additionally another open window for DoS attack as mod_rewrite is generally CPU consuming.
# Reject request when more than 5 ranges in the Range: header.
# CVE-2011-3192
#
RewriteEngine on
RewriteCond %{HTTP:range} !(bytes=[^,]+(,[^,]+){0,4}$|^$)
# RewriteCond %{HTTP:request-range} !(bytes=[^,]+(?:,[^,]+){0,4}$|^$)
RewriteRule .* - [F]
# We always drop Request-Range; as this is a legacy
# dating back to MSIE3 and Netscape 2 and 3.
RequestHeader unset Request-Range
3. Limit the size of Range request fields to few hundreds
To do so put in httpd.conf:
LimitRequestFieldSize 200
4. Dis-allow completely Range headers: via mod_headers Apache module
In httpd.conf put:
RequestHeader unset Range
RequestHeader unset Request-Range
This work around could create problems on some websites, which are made in a way that the Request-Range is used.
5. Deploy a tiny Apache module to count the number of Range Requests and drop connections in case of high number of Range: requests
This solution in my view is the best one, I’ve tested it and I can confirm on FreeBSD works like a charm.
To secure FreeBSD host Apache, against the Range Request: DoS using mod_rangecnt, one can literally follow the methodology explained in mod_rangecnt.c header:
freebsd# wget http://people.apache.org/~dirkx/mod_rangecnt.c
..
# compile the mod_rangecnt module
freebsd# /usr/local/sbin/apxs -c mod_rangecnt.c
...
# install mod_rangecnt module to Apache
freebsd# /usr/local/sbin/apxs -i -a mod_rangecnt.la
...
Finally to load the newly installed mod_rangecnt, Apache restart is required:
freebsd# /usr/local/etc/rc.d/apache2 restart
...
I’ve tested the module on i386 FreeBSD install, so I can’t confirm this steps works fine on 64 bit FreeBSD install, I would be glad if I can hear from someone if mod_rangecnt is properly compiled and installed fine also on 6 bit BSD arch.
Deploying the mod_rangecnt.c Range: Header to prevent against the Apache DoS on 64 bit x86_amd64 CentOS 5.6 Final is also done without any pitfalls.
[root@centos ~]# uname -a;
Linux centos 2.6.18-194.11.3.el5 #1 SMP Mon Aug 30 16:19:16 EDT 2010 x86_64 x86_64 x86_64 GNU/Linux
[root@centos ~]# /usr/sbin/apxs -c mod_rangecnt.c
...
/usr/lib64/apr-1/build/libtool --silent --mode=link gcc -o mod_rangecnt.la -rpath /usr/lib64/httpd/modules -module -avoid-version mod_rangecnt.lo
[root@centos ~]# /usr/sbin/apxs -i -a mod_rangecnt.la
...
Libraries have been installed in:
/usr/lib64/httpd/modules
...
[root@centos ~]# /etc/init.d/httpd configtest
Syntax OK
[root@centos ~]# /etc/init.d/httpd restart
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
After applying the mod_rangecnt patch if all is fine the memory exhaustion perl DoS script‘s output should be like so:
freebsd# perl httpd_dos.pl www.patched-apache-host.com 50
Host does not seem vulnerable
All of the above pointed work-arounds are only a temporary solution to these Grave Apache DoS byterange vulnerability , a few days after the original vulnerability emerged and some of the up-pointed work arounds were pointed. There was information, that still, there are ways that the vulnerability can be exploited.
Hopefully in the coming few weeks Apache dev team should be ready with rock solid work around to the severe problem.
In 2 years duration these is the second serious Apache Denial of Service vulnerability after before a one and a half year the so called Slowloris Denial of Service attack was capable to DoS most of the Apache installations on the Net.
Slowloris, has never received the publicity of the Range Header DoS as it was not that critical as the mod_range, however this is a good indicator that the code quality of Apache is slowly decreasing and might need a serious security evaluation.
Tags: apache httpd, apache server, apache webserver, ATTACKING, Auto, bugzilla, com, config, copy, CustomLog, deb package, denial of service, denial of service attack, dos attack, dos script, dos vulnerability, download, Draft, exploit, freebsd, header, host, HTTP, info, machine memory, memory exhaustion, minute time, mirror copy, mod, necessery, Netscape, number, perl httpd, poc, pPpPpppPpPPppPpppPp, REJECT, Remote, RewriteCond, script, simultaneous connections, work
Posted in Computer Security, FreeBSD, Linux, System Administration, Web and CMS | No Comments »
Friday, July 22nd, 2011 
Lately, I’m basicly using htop‘s nice colourful advanced Linux top command frontend in almost every server I manage, therefore I’ve almost abondoned top usage these days and in that reason I wanted to have htop installed on few of the OpenVZ CentOS 5.5 Linux servers at work.
I looked online but unfortunately I couldn’t find any rpm pre-built binary packages. The source rpm package I tried to build from dag wieers repository failed as well, so finally I went further and decided to install htop from source
Here is how I did it:
1. Install gcc and glibc-devel prerequired rpm packages
[root@centos ~]# yum install gcc glibc-devel
2. Download htop and compile from source
[root@centos src]# cd /usr/local/src
[root@centos src]# wget "http://sourceforge.net/projects/htop/files/htop/0.9/htop-0.9.tar.gz/download"
Connecting to heanet.dl.sourceforge.net|193.1.193.66|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 418767 (409K) [application/x-gzip]
Saving to: "download"
100%[======================================>] 418,767 417K/s in 1.0s
2011-07-22 13:30:28 (417 KB/s) – “download” saved [418767/418767]
[root@centos src]# mv download htop.tar.gz
[root@centos src]# tar -zxf htop.tar.gz
[root@centos src]# cd htop-0.9
[root@centos htop-0.9]# ./configure && make && make install
make install should install htop to /usr/local/bin/htop
That’s all folks! , now my OpenVZ CentOS server is equipped with the nifty htop tool 😉
Tags: amp, CentOS, colourful, command, dag wieers, devel, frontend, heanet, htop, HTTP, Install, Installing, Linux, linux servers, mv, OKLength, online, openvz, package, reason, repository, request, response, root, rpm, src, tar gz, tar zxf, tool, wget, yum, zxf
Posted in Linux, System Administration | No Comments »





How to resolve (fix) WordPress wp-cron.php errors like “POST /wp-cron.php?doing_wp_cron HTTP/1.0″ 404” / What is wp-cron.php and what it does
Monday, March 12th, 2012One of the WordPress websites hosted on our dedicated server produces all the time a wp-cron.php 404 error messages like:
xxx.xxx.xxx.xxx - - [15/Apr/2010:06:32:12 -0600] "POST /wp-cron.php?doing_wp_cron HTTP/1.0
I did not know until recently, whatwp-cron.php does, so I checked in google and red a bit. Many of the places, I've red are aa bit unclear and doesn't give good exlanation on what exactly wp-cron.php does. I wrote this post in hope it will shed some more light on wp-config.php and how this major 404 issue is solved..
So
what is wp-cron.php doing?
Suppose you're writting a new post and you want to take advantage of WordPress functionality to schedule a post to appear Online at specific time:
The Publish Immediately, field execution is being issued on the scheduled time thanks to the wp-cron.php periodic invocation.
Another example for wp-cron.php operation is in handling flushing of WP old HTML Caches generated by some wordpress caching plugin like W3 Total Cache
wp-cron.php takes care for dozens of other stuff silently in the background. That's why many wordpress plugins are depending heavily on wp-cron.php proper periodic execution. Therefore if something is wrong with wp-config.php, this makes wordpress based blog or website partially working or not working at all.
Our company wp-cron.php errors case
In our case the:
212.235.185.131 – – [15/Apr/2010:06:32:12 -0600] "POST /wp-cron.php?doing_wp_cron HTTP/1.0" 404
is occuring in Apache access.log (after each unique vistor request to wordpress!.), this is cause wp-cron.php is invoked on each new site visitor site request.
This puts a "vain load" on the Apache Server, attempting constatly to invoke the script … always returning not found 404 err.
As a consequence, the WP website experiences "weird" problems all the time. An illustration of a problem caused by the impoper wp-cron.php execution is when we are adding new plugins to WP.
Lets say a new wordpress extension is download, installed and enabled in order to add new useful functioanlity to the site.
Most of the time this new plugin would be malfunctioning if for example it is prepared to add some kind of new html form or change something on some or all the wordpress HTML generated pages.WP cache directory is manually deleted with rm -rf /var/www/blog/wp-content/cache/…
This troubles are result of wp-config.php's inability to update settings in wp SQL database, after each new user request to our site.
So the newly added plugin website functionality is not showing up at all, until
I don't know how thi whole wp-config.php mess occured, however my guess is whoever installed this wordpress has messed something in the install procedure.
Anyways, as I researched thoroughfully, I red many people complaining of having experienced same wp-config.php 404 errs. As I red, most of the people troubles were caused by their shared hosting prohibiting the wp-cron.php execution.
It appears many shared hostings providers choose, to disable the wordpress default wp-cron.php execution. The reason is probably the script puts heavy load on shared hosting servers and makes troubles with server overloads.
Anyhow, since our company server is adedicated server I can tell for sure in our case wordpress had no restrictions for how and when wp-cron.php is invoked.
I've seen also some posts online claiming, the wp-cron.php issues are caused of improper localhost records in /etc/hosts, after a thorough examination I did not found any hosts problems:
hipo@debian:~$ grep -i 127.0.0.1 /etc/hosts
127.0.0.1 localhost.localdomain localhost
You see from below paste, our server, /etc/hosts has perfectly correct 127.0.0.1 records.
Changing default way wp-cron.php is executed
As I've learned it is generally a good idea for WordPress based websites which contain tens of thousands of visitors, to alter the default way wp-cron.php is handled. Doing so will achieve some efficiency and improve server hardware utilization.
Invoking the script, after each visitor request can put a heavy "useless" burden on the server CPU. In most wordpress based websites, the script did not need to make frequent changes in the DB, as new comments in posts did not happen often. In most wordpress installs out there, big changes in the wordpress are not common.
Therefore, a good frequency to exec wp-cron.php, for wordpress blogs getting only a couple of user comments per hour is, half an hour cron routine.
To disable automatic invocation of wp-cron.php, after each visitor request open /var/www/blog/wp-config.php and nearby the line 30 or 40, put:
define('DISABLE_WP_CRON', true);
An important note to make here is that it makes sense the position in wp-config.php, where define('DISABLE_WP_CRON', true); is placed. If for instance you put it at the end of file or near the end of the file, this setting will not take affect.
With that said be sure to put the variable define, somewhere along the file initial defines or it will not work.
Next, with Apache non-root privileged user lets say www-data, httpd, www depending on the Linux distribution or BSD Unix type add a php CLI line to invoke wp-cron.php every half an hour:
linux:~# crontab -u www-data -e
0,30 * * * * cd /var/www/blog; /usr/bin/php /var/www/blog/wp-cron.php 2>&1 >/dev/null
To assure, the php CLI (Command Language Interface) interpreter is capable of properly interpreting the wp-cron.php, check wp-cron.php for syntax errors with cmd:
linux:~# php -l /var/www/blog/wp-cron.php
No syntax errors detected in /var/www/blog/wp-cron.php
That's all, 404 wp-cron.php error messages will not appear anymore in access.log! 🙂
Just for those who can find the root of the /wp-cron.php?doing_wp_cron HTTP/1.0" 404 and fix the issue in some other way (I'll be glad to know how?), there is also another external way to invoke wp-cron.php with a request directly to the webserver with short cron invocation via wget or lynx text browser.
– Here is how to call wp-cron.php every half an hour with lynxPut inside any non-privileged user, something like:
01,30 * * * * /usr/bin/lynx -dump "http://www.your-domain-url.com/wp-cron.php?doing_wp_cron" 2>&1 >/dev/null
– Call wp-cron.php every 30 mins with wget:
01,30 * * * * /usr/bin/wget -q "http://www.your-domain-url.com/wp-cron.php?doing_wp_cron"
Invoke the wp-cron.php less frequently, saves the server from processing the wp-cron.php thousands of useless times.
Altering the way wp-cron.php works should be seen immediately as the reduced server load should drop a bit.
Consider you might need to play with the script exec frequency until you get, best fit cron timing. For my company case there are only up to 3 new article posted a week, hence too high frequence of wp-cron.php invocations is useless.
With blog where new posts occur once a day a script schedule frequency of 6 up to 12 hours should be ok.
Tags: akismet, Auto, caches, checks, commentor, cr, cron, daySuppose, dedicated server, doesn, dozens, Draft, email, error messages, execution, exlanation, file, google, HTML, HTTP, invocation, localhost, nbsp, newsletter, operation, periodic execution, php, plugin, quot, request, scheduler, someone, something, spam, SQL, time, time thanks, Wordpress, wordpress plugins, wp
Posted in System Administration, Web and CMS, Wordpress | 3 Comments »