
I’m realizing the more I’m converting to a fully functional GUI user, the less I’m doing coding or any interesting stuff…
I remembered of the old glorious times, when I was full time console user and got a memory on a nifty trick I was so used to back in the day.
Back then I was quite often writing shell scripts which were fetching (html) webpages and converting the html content into a plain TEXT (TXT) files
In order to fetch a page back in the days I used lynx – (a very simple UNIX text browser, which by the way lacks support for any CSS or Javascipt) in combination with html2text – (an advanced HTML-to-text converter).
Let’s say I wanted to fetch a my personal home page https://www.pc-freak.net/, I did that via the command:
$ lynx -source https://www.pc-freak.net/ | html2text > pcfreak_page.txt
The content from www.pc-freak.net got spit by lynx as an html source and passed html2pdf wchich saves it in plain text file pcfreak_page.txt
The bit more advanced elinks – (lynx-like alternative character mode WWW browser) provides better support for HTML and even some CSS and Javascript so to properly save the content of many pages in plain html file its better to use it instead of lynx, the way to produce .txt using elinks files is identical, e.g.:
$ elinks -source https://www.pc-freak.net/blog/ | html2text > pcfreak_blog_page.txt
By the way back in the days I was used more to links , than the superior elinks , nowdays I have both of the text browsers installed and testing to fetch an html like in the upper example and pipe to html2text produced garbaged output.
Here is the time to tell its not even necessery to have a text browser installed in order to fetch a webpage and convert it to a plain text TXT!. wget file downloading tools supports source dump as well, for all those who did not (yet) tried it and want to test it:
$ wget -qO- https://www.pc-freak.net | html2text
Anyways of course, some pages convertion of text inside HTML tags would not properly get saved with neither lynx or elinks cause some texts might be embedded in some elinks or lynx unsupported CSS or JavaScript. In those cases the GUI browser is useful. You can use any browser like Firefox, Epiphany or Opera ‘s File -> Save As (Text Files) embedded functionality, below is a screenshot showing an html page which I’m about to save as a plain Text File in Mozilla Firefox:
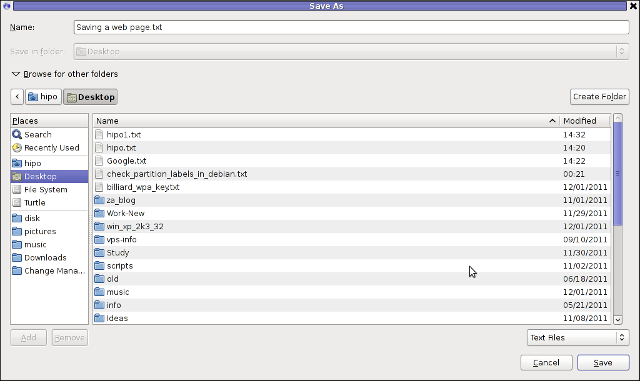
Besides being handy in conjunction with text browsers, html2text is also handy for converting .html pages already existing on the computer’s hard drive to a plain (.TXT) text format.
One might wonder, why would ever one would like to do that?? Well I personally prefer reading plain text documents instead of htmls 😉
Converting an html files already existing on hard drive with html2text is done with cmd:
$ html2text index.html >index.txt
To convert a whole directory full of .html (documentation) or whatever files to plain text .TXT , cd the directory with HTMLs and issue the one liner bash loop command:
$ cd html/
html$ for i in $(echo *.html); do html2text $i > $(echo $i | sed -e 's#.html#.txt#g'); done
Now lay off your back and enjoy reading the dox like in the good old hacker days when .TXT files were fashionable 😉




