![]() As a sysadmin that have my own Open Xen Debian Hypervisor running on a Lenovo ThinkServer few months ago due to a human error I managed to mess up one of my virtual machines and rebuild the Operating System from scratch and restore files service and MySQl data from backup that really pissed me of and this brought the need for having a decent Virtual Machine OpenXen backup solution I can implement on the Debian ( Buster) 10.10 running the free community Open Xen version 4.11.4+107-gef32c7afa2-1. The Hypervisor is a relative small one holding just 7 VM s:
As a sysadmin that have my own Open Xen Debian Hypervisor running on a Lenovo ThinkServer few months ago due to a human error I managed to mess up one of my virtual machines and rebuild the Operating System from scratch and restore files service and MySQl data from backup that really pissed me of and this brought the need for having a decent Virtual Machine OpenXen backup solution I can implement on the Debian ( Buster) 10.10 running the free community Open Xen version 4.11.4+107-gef32c7afa2-1. The Hypervisor is a relative small one holding just 7 VM s:
HypervisorHost:~# xl list
Name ID Mem VCPUs State Time(s)
Domain-0 0 11102 24 r—– 214176.4
pcfrxenweb 11 12288 4 -b—- 247425.5
pcfrxen 12 16384 10 -b—- 1371621.4
windows7 20 4096 2 -b—- 97887.2
haproxy2 21 4096 2 -b—- 11806.9
jitsi-meet 22 2048 2 -b—- 12843.9
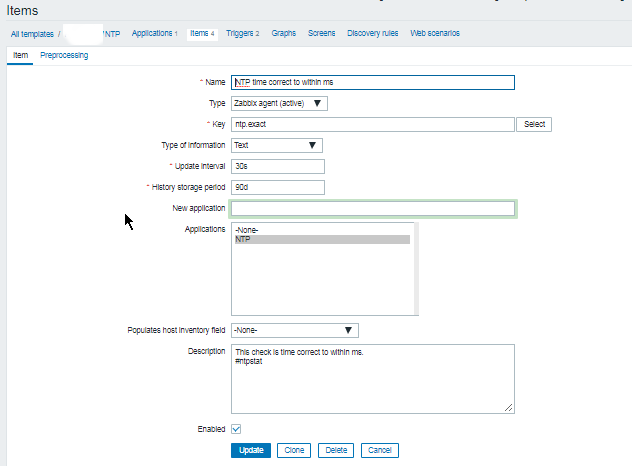
zabbix 23 2048 2 -b—- 20275.1
centos7 24 2040 2 -b—- 10898.2
HypervisorHost:~# xl list|grep -v 'Name ' |grep -v 'Domain-0' |wc -l
7
The backup strategy of the script is very simple to shutdown the running VM machine, make a copy with rsync to a backup location the image of each of the Virtual Machines in a bash shell loop for each virtual machine shown in output of xl command and backup to a preset local directory in my case this is /backups/ the backup of each virtual machine is produced within a separate backup directory with a respective timestamp. Backup VM .img files are produced in my case to mounted 2x external attached hard drives each of which is a 4 Terabyte Seagate Plus Backup (Storage). The original version of the script was made to be a slightly different by Zhiqiang Ma whose script I used for a template to come up with my xen VM backup solution. To prevent the Hypervisor's load the script is made to do it with a nice of (nice -n 10) this might be not required or you might want to modify it to better suit your needs. Below is the script itself you can fetch a copy of it /usr/sbin/xen_vm_backups.sh :
#!/bin/bash
# Author: Zhiqiang Ma (http://www.ericzma.com/)
# Modified to work with xl and OpenXen by Georgi Georgiev – https://pc-freak.net
# Original creation dateDec. 27, 2010
# Script takes all defined vms under xen_name_list and prepares backup of each
# after shutting down the machine prepares archive and copies archive in externally attached mounted /backup/disk1 HDD
# Latest update: 08.06.2021 G. Georgiev – hipo@pc-freak.netmark_file=/backups/disk1/tmp/xen-bak-marker
log_file=/var/log/xen/backups/bak-$(date +%Y_%m_%d).log
err_log_file=/var/log/xen/backups/bak_err-$(date +%H_%M_%Y_%m_%d).log
xen_dir=/xen/domains
xen_vmconfig_dir=/etc/xen/
local_bak_dir=/backups/disk1/tmp
#bak_dir=xenbak@backup_host1:/lhome/xenbak
bak_dir=/backups/disk1/xen-backups/xen_images/$(date +%Y_%m_%d)/xen/domains
#xen_name_list="haproxy2 pcfrxenweb jitsi-meet zabbix windows7 centos7 pcfrxenweb pcfrxen"
xen_name_list="windows7 haproxy2 jitsi-meet zabbix centos7"if [ ! -d /var/log/xen/backups ]; then
echo mkdir -p /var/log/xen/backups
mkdir -p /var/log/xen/backups
fiif [ ! -d $bak_dir ]; then
echo mkdir -p $bak_dir
mkdir -p $bak_dirfi
# check whether bak runned last week
if [ -e $mark_file ] ; then
echo rm -f $mark_file
rm -f $mark_file
else
echo touch $mark_file
touch $mark_file
# exit 0
fi# set std and stderr to log file
echo mv $log_file $log_file.old
mv $log_file $log_file.old
echo mv $err_log_file $err_log_file.old
mv $err_log_file $err_log_file.old
echo "exec 2> $err_log_file"
exec 2> $err_log_file
echo "exec > $log_file"
exec > $log_file
# check whether the VM is running
# We only backup running VMsecho "*** Check alive VMs"
xen_name_list_tmp=""
for i in $xen_name_list
do
echo "/usr/sbin/xl list > /tmp/tmp-xen-list"
/usr/sbin/xl list > /tmp/tmp-xen-list
grepinlist=`grep $i" " /tmp/tmp-xen-list`;
if [[ “$grepinlist” == “” ]]
then
echo $i is not alive.
else
echo $i is alive.
xen_name_list_tmp=$xen_name_list_tmp" "$i
fi
donexen_name_list=$xen_name_list_tmp
echo "Alive VM list:"
for i in $xen_name_list
do
echo $i
doneecho "End alive VM list."
###############################
date
echo "*** Backup starts"###############################
date
echo "*** Copy VMs to local disk"for i in $xen_name_list
do
date
echo "Shutdown $i"
echo /usr/sbin/xl shutdown $i
/usr/sbin/xl shutdown $i
if [ $? != ‘0’ ]; then
echo 'Not Xen Disk image destroying …';
/usr/sbin/xl destroy $i
fi
sleep 30echo "Copy $i"
echo "Copy to local_bak_dir: $local_bak_dir"
echo /usr/bin/rsync -avhW –no-compress –progress $xen_dir/$i/{disk.img,swap.img} $local_bak_dir/$i/
time /usr/bin/rsync -avhW –no-compress –progress $xen_dir/$i/{disk.img,swap.img} $local_bak_dir/$i/
echo /usr/bin/rsync -avhW –no-compress –progress $xen_vmconfig_dir/$i.cfg $local_bak_dir/$i.cfg
time /usr/bin/rsync -avhW –no-compress –progress $xen_vmconfig_dir/$i.cfg $local_bak_dir/$i.cfg
date
echo "Create $i"
# with vmmem=1024"
# /usr/sbin/xm create $xen_dir/vm.run vmid=$i vmmem=1024
echo /usr/sbin/xl create $xen_vmconfig_dir/$i.cfg
/usr/sbin/xl create $xen_vmconfig_dir/$i.cfg
## Uncomment if you need to copy with scp somewhere
### echo scp $log_file $bak_dir/xen-bak-111.log
### echo /usr/bin/rsync -avhW –no-compress –progress $log_file $local_bak_dir/xen-bak-111.log
done####################
date
echo "*** Compress local bak vmdisks"for i in $xen_name_list
do
date
echo "Compress $i"
echo tar -z -cfv $bak_dir/$i-$(date +%Y_%m_%d).tar.gz $local_bak_dir/$i-$(date +%Y_%m_%d) $local_bak_dir/$i.cfg
time nice -n 10 tar -z -cvf $bak_dir/$i-$(date +%Y_%m_%d).tar.gz $local_bak_dir/$i/ $local_bak_dir/$i.cfg
echo rm -vf $local_bak_dir/$i/ $local_bak_dir/$i.cfg
rm -vrf $local_bak_dir/$i/{disk.img,swap.img} $local_bak_dir/$i.cfg
done####################
date
echo "*** Copy local bak vmdisks to remote machines"copy_remote () {
for i in $xen_name_list
do
date
echo "Copy to remote: vm$i"
echo scp $local_bak_dir/vmdisk0-$i.tar.gz $bak_dir/vmdisk0-$i.tar.gz
done#####################
date
echo "Backup finishes"
echo scp $log_file $bak_dir/bak-111.log}
date
echo "Backup finished"
Things to configure before start using using the script to prepare backups for you is the xen_name_list variable
# directory skele where to store already prepared backups
bak_dir=/backups/disk1/xen-backups/xen_images/$(date +%Y_%m_%d)/xen/domains
# The configurations of the running Xen Virtual Machines
xen_vmconfig_dir=/etc/xen/
# a local directory that will be used for backup creation ( I prefer this directory to be on the backup storage location )
local_bak_dir=/backups/disk1/tmp
#bak_dir=xenbak@backup_host1:/lhome/xenbak
# the structure on the backup location where daily .img backups with be produced with rsync and tar archived with bzip2
bak_dir=/backups/disk1/xen-backups/xen_images/$(date +%Y_%m_%d)/xen/domains
# list here all the Virtual Machines you want the script to create backups of
xen_name_list="windows7 haproxy2 jitsi-meet zabbix centos7"
If you need the script to copy the backup of Virtual Machine images to external Backup server via Local Lan or to a remote Internet located encrypted connection with a passwordless ssh authentication (once you have prepared the Machines to automatically login without pass over ssh with specific user), you can uncomment the script commented section to adapt it to copy to remote host.
Once you have placed at place /usr/sbin/xen_vm_backups.sh use a cronjob to prepare backups on a regular basis, for example I use the following cron to produce a working copy of the Virtual Machine backups everyday.
# crontab -u root -l
# create windows7 haproxy2 jitsi-meet centos7 zabbix VMs backup once a month
00 06 1,2,3,4,5,6,7,8,9,10,11,12 * * /usr/sbin/xen_vm_backups.sh 2>&1 >/dev/null
I do clean up virtual machines Images that are older than 95 days with another cron job
# crontab -u root -l
# Delete xen image files older than 95 days to clear up space from backup HDD
45 06 17 * * find /backups/disk1/xen-backups/xen_images* -type f -mtime +95 -exec rm {} \; 2>&1 >/dev/null#### Delete xen config backups older than 1 year+3 days (368 days)
45 06 17 * * find /backups/disk1/xen-backups/xen_config* -type f -mtime +368 -exec rm {} \; 2>&1 >/dev/null
# Delete xen image files older than 95 days to clear up space from backup HDD
45 06 17 * * find /backups/disk1/xen-backups/xen_images* -type f -mtime +95 -exec rm {} \; 2>&1 >/dev/null#### Delete xen config backups older than 1 year+3 days (368 days)
45 06 17 * * find /backups/disk1/xen-backups/xen_config* -type f -mtime +368 -exec rm {} \; 2>&1 >/dev/null