Just few weeks ago it was the feast of our temple here in Dobrich the holy triniy. For this event a lot of priests either from Dobrich and the district as well as the Metropolit Kiril of Varna. Father Veliko has insisted to ordain me with a church rank. The church rank I received grants me oportunity to enter the holy altar and help in the church services (the holy liturgies). My sister has captured a couple of snapshots both video and pictures the pictures I’ve upload and can be seen
Posts Tagged ‘snapshots’
The Celebration of the feast of the temple Holy Trinity
Thursday, June 25th, 2009luckyBackup Linux GUI back-up and synchronization tool
Wednesday, May 14th, 2014 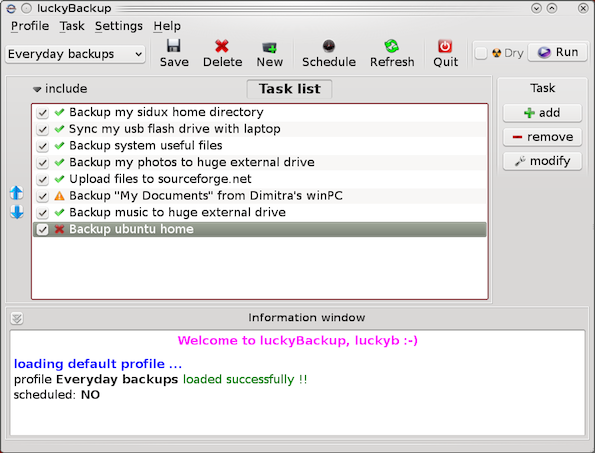
If you're a using GNU / Linux for Desktop and you're already tired of creating backups by your own hacks using terminal and you want to make your life a little bit more easier and easily automate your important files back up through GUI program take a look at luckyBackup.
Luckibackup is a GUI frontend to the infamous rsync command line backup tool. Luckibackup is available as a package in almost all modern Linux distributions its very easy to setup and can save you a lot of time especially if you have to manage a number of your Workplace Desktop Office Linux based computers.
Luckibackup is an absolute must have program for Linux Desktop start-up users. If you're migrating from Microsoft Windows realm and you're used to BackupPC, Luckibackup is probably the defacto Linux BackupPC substitute.
The sad news for Linux GNOME Desktop users is luckibackup is written in QT and it using it will load up a bit your notebook.
It is not installed by default so once a new Linux Desktop is installed you will have to install it manually on Debian and Ubuntu based Linux-es to install Luckibackup apt-get it.
debian:~# apt-get install --yes luckibackup
...
On Fedora and CentOS Linux install LuckiBackup via yum rpm package manager
[root@centos :~]# yum -y install luckibackup
.
Luckibackup is also ported for OpenSuSE Slackware, Gentoo, Mandriva and ArchLinux. In 2009 Luckibackup won the prize of Sourceforge Community Choice Awards for "best new project".
luckyBackup copies over only the changes you've made to the source directory and nothing more.
You will be surprised when your huge source is backed up in seconds (after the first backup).
Whatever changes you make to the source including adding, moving, deleting, modifying files / directories etc, will have the same effect to the destination.
Owner, group, time stamps, links and permissions of files are preserved (unless stated otherwise).
Luckibackup creates different multiple backup "snapshots".Each snapshot is an image of the source data that refers to a specific date-time.
Easy rollback to any of the snapshots is possible. Besides that luckibackup support Sync (just like rsync) od any directories keeping the files that were most recently modified on both of them.
Useful if you modify files on more than one PCs (using a flash-drive and don't want to bother remembering what did you use last. Luckibackup is capable of excluding certain files or directories from backups – Exclude any file, folder or pattern from backup transfer.
After each operation a logfile is created in your home folder. You can have a look at it any time you want.
luckyBackup can run in command line if you wish not to use the gui, but you have to first create the profile that is going to be executed.
Type "luckybackup –help" at a terminal to see usage and supported options.
There is also TrayNotification – Visual feedback at the tray area informs you about what is going on.
Linux webcam take pictures from tty console or terminal / How to make pictures of yourself using plain console and web-camera
Saturday, December 15th, 2012
I'm a great command line enthusiast, I share the believe of many other command line geeks thinking keyboard is the quickest way to access a computer. Historically keys were first and mouse second and I think there is definitely a good reason for that. Thus today I was curious if it is possible to take pictures from my external web-camera on my Debian GNU / Linux? I did a quick research and this little article springed out as result.
The answer is YES! It is possible and besides that there are many ways to take a webcamera picture using the console; Lastly it is very easy to achieve even for novice Linux buddies 😉 My little research on the topic show me there are 4 straightforward ways one can use to use his extended or embedded WebCam to take pictuers – using (vlc, mplayer, camshot, fswebcam and ffmpeg).
1. Taking a webcam picture using vlc
Invoke vlc with following arguments:
# vlc -I dummy v4l2:///dev/video0 --video-filter scene --no-audio --scene-path /home/hipo --scene-prefix webcam-taken-picture-prefix --scene-format png vlc://quit --run-time=1
I've prepared a little wrapper script, for the sake of simplifying the long and hard to remember vlc options. Below is the script;
#!/bin/sh
# This little script will take picture whilst in gnome-terminal / mlterm or any console tty
# As program uses vlc you need to have vlc properly configured and installed
# as well as the webcam video be properly working (detected by Linux kernel)
# licensed under GPLv2 script modified by hip0 14.12.2012
# Path where to store taken snapshots
STORE_PATH=/home/hipo
# Device locatation of webcam many webcams have default device in /dev/video0
WEBCAM_DEV=/dev/video0
# Stored grabbed picture filename prefix
FILE_NAME_PREF=image_prefix
# gets the current date and adds to set filename prefix
date_cur=$(date +%k_%d_%m_%Y|sed -e 's/^ *//');
vlc -I dummy v4l2://$WEBCAM_DEV --video-filter scene --no-audio --scene-path $STORE_PATH --scene-prefix $FILE_NAME_PREF.$date_cur --scene-format png vlc://quit --run-time=1
echo "WebCam picture taken and stored in $STORE_PATH/$FILE_NAME_PREF.$date_cur*.png";
echo '';
echo "To view picture in Gnome with Eye of GNOME type: eog $STORE_PATH/$FILE_NAME_PREF.$date_cur*.png";
You can also download copy of the webcam_take_picture_from_console.sh script here.
As you see the script uses, vlc's (dummy interface), and –video-filter-scene option to make the snapshot. The script can be stored in let's say /usr/local/bin/webcam_take_picture.sh and aliased through ~/.bashrc with some short alias, i.e.:
alias console-picture='/usr/local/bin/webcam_take_picture.sh'
Then at any time, when you run console-picture you will have a short way to make pictures of your room, your friends or whatever needed. One good application of script is whether you're in coffee with friends and you want to take a snapshot of them without them realizing (assuming, the webcam is embedded) 🙂
Another great application is whether you want to take a snapshot of the WebCam, from another shell script or little application using dialog ncurses interfaces etc.
Even just for the sake of fun it is so nice to take a picture from webcam, whether in plain tty console bash shell 🙂
One small note to make here is webcam_take_picture_from_console.sh should be run as non-root user (for security reasons vlc developers made smartly VLC this way), running it as root drops an err:
>VLC is not supposed to be run as root. Sorry.
If you need to use real-time priorities and/or privileged TCP ports
you can use /usr/bin/vlc-wrapper (make sure it is Set-UID root and
cannot be run by non-trusted users first).
By default, vlc resolution used is the automatically set to the maximum supported to the camera, with mine this is 640×480 SRGB
The quality of pictures taken is a bit low but my camera is a cheap one and even with some GUI program snapshot taking programs like GNOME's cheese, taken pictures are with low quality (though I think the brightnes of the ones taken with vlc is a bit poorer than the ones done with cheese).
Happily it is possible to correct picture brightness and lightning with v42l-ctl (v42l-ctl is not installed by default and on Debian you will have to install deb pack v4l-utils), e.g.:
apt-get install --yes v4l-utils
....
Further, check out the possible options available with:
v4l2-ctl -L - (list all possible options)
and to set a concrete option do:
v4l2-ctl -c <options>=<value> (set an option)
I don't have a BSD (FreeBSD, NetBSD, OpenBSD) at hand, but with a working supported Webcam, correct location to the webcam /dev/ and installed VLC from ports :
vlc -I dummy v4l2:///dev/video0--video-filter scene --no-audio --scene-path $STORE_PATH --scene-prefix $FILE_NAME_PREF.$date_cur --scene-format png vlc://quit --run-time=1
should be working fine as well.
If someone has access to a BSD with a working installed webcam, please test it and drop a comment to confirm if working …
2. Creating pictures from WebCamera using mplayer cmd
Theoretically mplayer, should be able to take snapshots from the Cam with:
mplayer -vo png -frames 1 tv://
There is possibility to pass output webcam picture (resolution) dimensions too:
mplayer tv:// -tv driver=v4l:device=/dev/video0:width=320:height=240:outfmt=rgb24 -frames 1 -vo jpeg
With my "NoName" (Eltron Technology) webcam the produced images were filled up with solid green color (maybe due to bug of my webcam used driver). Normally it should be working; I've seen many posts around claiming using both of above cmd lines to produce pictures normally, but not for me.
3. Making pictures with WebCamera (camshot) console tool
I've seen around also another tiny tool (camshot) especially written to take pictures from webcam. The tool is available only to be compiled from source (whether source is fetched through Subversion repo (SVN)). I took a minute to test it as well, e.g.:
hipo@noah:~Desktop$ svn checkout http://camshot.googlecode.com/svn/trunk/ camshot-read-only
hipo@noah:~/Desktop/camshot-read-only$ make
....
hipo@noah:~/Desktop/camshot-read-only$ ls
arguments.c arguments.o camera.h camshot image.h main.c Makefile shmem.h shmem_test.c
arguments.h camera.c camera.o image.c image.o main.o shmem.c shmem.o
hipo@noah:~Desktop/camshot-read-only$ ./camshot
Letting the camera automaticaly adjust the picture:..........Done.
Command (h for help): h
Commands:
x Capture a picture from camera.
h Prints this help.
q Quits the program.
Command (h for help): x
Command (h for help): q
Don't know why, but for me camshot did not produce, any output picture from webcam. Maybe my Webcam which is a cheap (all OS) compatible one is not detected fine by the tool? As you see from above help output there are not many options so it is definitely something with webcam detection or just it needs some kind of little "hack" in the source to make it working, I was lazy to further investigate so I leave it.
4. Making pictures from terminal using fswebcam
fswebcam is not so popular as vlc and mplayer, but is existent from default repostiries on both Debian and Ubuntu Linuces. Here is it how it is described when pkg info requested with apt-cache:
apt-cache show fswebcam | grep -i descrip -A 8
Description: Tiny and flexible webcam program
Fswebcam is a tiny and flexible webcam command-line program for capturing
images from a V4L1/V4L2 device. It accepts a number of formats, can skip
the first (possibly bad) frames before performing the actual capture, and
can perform simple manipulation on the captured image, such as resizing,
averaging multiple frames or overlaying a caption or an image.
Homepage: http://www.firestorm.cx/fswebcam/
Tag: implemented-in::c, role::program
To use it first install it with apt-get or yum (yes it is available also for RedHat based Linux distros via yum).
Depending whether on Debian or Fedora etc. do:
apt-get install --yes fswebcam
.....
or
yum -y install fswebcam
....
fswebcam's syntax is much easier than all of rest cmd tools available around; to create picture from webcam;
# fswebcam -r 640x480 --jpeg 85 -D 1 web-cam-shot.jpg
--- Opening /dev/video0...
Trying source module v4l2...
/dev/video0 opened.
No input was specified, using the first.
Delaying 1 seconds.
--- Capturing frame...
Captured frame in 0.00 seconds.
--- Processing captured image...
Setting output format to JPEG, quality 85
Unable to load font 'luxisr': Could not find/open font
Disabling the the banner.
Writing JPEG image to 'web-cam-shot.jpg'.
I liked supports, saving in multiple formats, can set resolution and is probably the number 1 choice for anyone looking for high level of customization of cam taken picture.. Saying this I think fswebcam is definitely the tool of choice as it is written with the one and only aim to take webcam pictures from console.
5. Capturing picture from Webcam using ffmpeg
With ffmpeg, there are plenty of things possible;
Just to mention few interesting ones, I've written about earlier, ffmeg is capable of;
– convert .OGG vorbis to MP3
– convert .FLV to .AVI and .AVI to .FLV
– convert .AVI .MP4 and .FLV to OGG Vorbis (Free Format)
– convert .OGG video to .FLV Video
– extract sounds / music from .FLV to a MP3 / MP4
– Add .SRT and .SUB files subtitles to Flash Videos
Along with all this, interestingly ffmpeg can get content using command line from WebCamera (nomatter if it's a VIDEO stream or just a Picture snapshot).
The syntax to take a picture with it is:
ffmpeg -f video4linux2 -i /dev/v4l/by-id/usb-Etron_Technology__Inc._USB2.0_Camera-video-index0 -vframes 1 output-picture.jpeg
The precise /dev/(v4l – video 4 linux) assigned to different cameras will differ so in order to find what kind of /dev, to use ls it:
# ls -al /dev/v4l/by-id/*
lrwxrwxrwx 1 root root 12 Dec 14 22:40 /dev/v4l/by-id/usb-Etron_Technology__Inc._USB2.0_Camera-video-index0 -> ../../video0
The picture resolution taken on my Eltron Technology Webcam is same like with vlc – the cam optimum 640×480, the quality and brightness gamma is also identical to pics taken using VLC.
Therefore if you're wondering if one tool, might make a better pictures from command line than the other the answer, according to my tests is they produce identical quality and all can be customized easily for different set of resolution. It is possible thought, this is not so with other Web Cam models, if you happen to read this post and take the time to try taking pictures with 5 methods and some of the 5 progs is making superior pictures, please drop a comment with the tool you used and the WebCam exact version as detected in dmesg or lsusb.
As a sort of Outtro, from purely functional / usability point of view I think fswebcam is probably be the tool of choice for mostly all as it is most simple, easily customizable and especially crafted for creating webcam console shots. That's all Enjoy, taking pics from GUI terminal or console 🙂
P.S. – I know there are plenty of people who have written on the topic, so this article is nothing new under the sun, but as I couldn't find a post synthesizing in one all of the 5 methods I've come up with this little article. Feedback is mostly welcome
Happy picturing 😉
Recovering long lost website information (data) with wayback machine
Monday, May 9th, 2011![]()
I needed a handy way to recover some old data of an expired domain containing a website, with some really imprtant texts.
The domains has expired before one year and it was not renewed for the reason that it’s holder was not aware his website was gone. In the meantime somebody registered this domain as a way to generate ads profit from it the website was receiving about 500 to 1000 visitors per day.
Now I have the task to recover this website permanently lost from the internet data. I was not able to retrieve anything from the old domain name be contained via google cache, yahoo cache, bing etc.
It appears most of the search engines store a cached version of a crawled website for only 34 months. I’ve found also a search engine gigablast which was claimed to store crawled website data for 1 year, but unfortunately gigablast contained not any version of the website I was looking for.Luckily (thanks God) after a bit of head-banging there I found a website that helped me retrieve at least some parts from the old lost website.
The website which helped me is called WayBack Machine
The Wayback Machine , guys keeps website info snapshots of most of the domain names on the internet for a couple of years back, here is how wayback machine website describes its own provided services:
The Internet Archive's Wayback Machine puts the history of the World Wide Web at your fingertips.
Another handy feature wayback machine provides is checking out how certain websites looked like a couple of years before, let’s say you want to go back in the past and see how yahoo’s website looked like 2 years ago.
Just go to web.archive.org and type in yahoo and select a 2 years old website snapshot and enjoy 😉
It’s really funny how ridiculous many websites looked like just few years from now 😉




