
If you have worked in a small or middle sized company and you're offered work into some of the top 100 world corporations, prepare yourself for some shocking 3 to 6 months depending on the company. This period in which you will be introduced to the company's field of business and way of work is called in corporate terms OnBoarding period. Even if everything looks to complicated and obscure, don't be quick to loose yourself or desperate as this is just a new beginning and as any new beginning it is hard. However once you're acquainted with basics it will be much easier for you.
After all most of the new things you will learn in Corporate Environment are just the good old ones you know already packaged under a different wrapper. You will be introduced to many portals, client names, have to watch a lot of "brain-dead" trainings, which told you basics on Corporation and its client essentials, be offered ways to advance, have to request Accounts and Credentials to servers via some obscure procedures, which change all the time, so it is likely the procedures you have to follow to get the necessery network / server accesses will be a procedure different from the one your colleagues followed few years ago, thus probably you will have to do account requests for a first time. In this on-boarding time you will deal with a lot of trainings teaching you to be ethical, respect your co-workers, learn basics of inter-cultural awareness and learn to get responsibility for your actions and some specific training regarding the job position (job description) you have.

You have to be patient and non-judgemental and ready to accept situation as it is and not be angry that so many people doesn't have idea on what is happening. Also it is a good start-up corporate advice to respect people's knowledge, don't thing that you're too knowledgable, as you will be amazed that there are a lot of people in huge companies which have better understanding and knowledge on tech than you. Also realize, the confusion that is taking place in Huge companies "The Right hand doesn't know what the left hand is doing", as our CCL Kalin used to say. The corporate world is a world where way of work is very different from tiny companies, you will have a chain of managers on top of you. The huge companies world is a world of big fish players ..
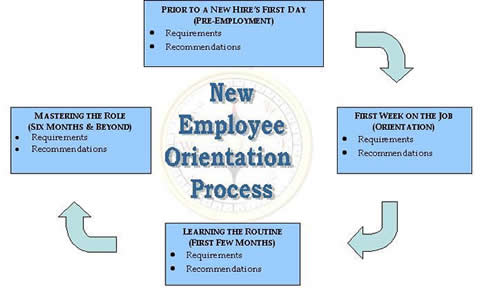
It is normal that in the first weeks / months you feel overwhelmed because of too much information and all looks too difficult, however just don't worry and go on. Now all is hard but in a few months everything comes to place and you realize in reality all is easy and it just seems hard in the beginning.
It is a good thing that you use the "Induction" / Onboarding period of first few months to find to make as many contacts as possible as this will be of a great help in your later job time. Get in contact with people from Database / Database and Storage / Load Balancers / Networking / Firewall Teams / Managers / Delivery Leads – the rule here is the more, the better. If you want to grow in the company's scale making social contacts is even more important than being a hard-worker. If you have friends in management of company and you do your work well and try to be proactive, sooner or later your managers will notice this and will recommend you for some kind of manager position.

Here's few abbreviation meanings, you will have to learn if you will have to work some kind of system administration or support work for a Hewlett Packard.
Microsoft Products – For people coming from Linux / UNIX background, the induction (onboarding) period into a large corporation is even more complicated because if you have been accustomed to using Open Source OS and tools in large corporations you will probably have to do a lot of things with proprietary tools which are hard to run on Linux / *nix, therefore it is good practice if you intend to work for Biggest Organizations in the world to get used to either running a MS Windows 7 / 8 into a Virtualbox or VMWare or get used to using Windows as a Desktop environment. Once you enter the huge organization it is likely you're handed in with your working notebook, shipped with a Customized Windows install to work well with the corporation where you're onboarding. However companies like HP did a great job, because they offer Ubuntu / Debian / Scientific Linux distributions tailored with most tools you will need for normal daily work, so it is not necessery to use Windows (though I find it personally much easier) to use Windows as desktop nowadays.
I really don't like running 20% of applications in Virtual Machines and doing occasional work-arounds to make things work. After all life is complex enough …
Microsoft Lync Communicator – This is the defacto standard program still used in corporation for internal VoIP / Video communication , One of coolest Lync feature is Sharing Screen. At any time you can share your screen (thing like you have installed teamviewer), give-control to remote party, you can share screen between multiple people and it is pretty much like a shared desktop conference, really useful! However sometimes when Internet is slow or network is failing occasionally MS Lync gives worse results than TeamViewer, so having TeamViewer just in case is useful too. Lync works making the VoIP connection by using some Exchange Mail server integration.
MS (Outlook) Calendar – Calendar is one of the top things you have to know to organize meetings with clients and colleagues to discuss various project aspects, server problems or just ask a question your Solution Designer regarding some server Environment designed by him .
MS Outlook – All mail communication is primary using Outlook Express, you can add Tasks, Contacts and set Calendar meetings with it. If you're like me and coming from UNIX world and get used too much to Mozilla Thunderbird, you will be in big shock until you get used to work with Outlook, not that it is difficult but it is quite different from Thunderbird. For efficient work with Outlook Mail you will have to learn creating Outlook Filters and Outlook Mail backups as often mailbox is just 1 or2G and mailbox fills in for a year time.
Monitoring Software IBM Netcool or something a like – Servers and services will be monitored with some kind of tool whose basics you will have to learn, if you have worked with Monit / Nagios or Munin you will quickly grasp the basic concept
MS Office / MS Project – You need Word and Excel quite often and for sysadmins this is very irritating. All office and client documents will be exchanged in Word and Excel format, if you're a Project Manager you will need heavily use of Microsoft Project too which needs to be installed additionally as it does not ship by default with most MS Office / Windows installs.
MS OneNote – is a software like notepad supporting tabs and allowing to make notes which are stored to a SharePoint
SharePoint (SP) – in large companies they like placing things into Sharepoints so a lot of the documentation is found on some random sharepoints (this is like a Directory Listing Apache server) – very annoying as it is really chaotic – I don't like it.
CMO – Chief Marketing Officer
CMO – Current Mode of Operations
FMO – Future Mode of Operations
SMO – Separation Management Office / Separation Management Officer
WFH – Work From Home, mail header message aiming to report someone is going to work from his home during the day
CFO – Chief Financial Officer
CEO – Chief Execute Officer
PM – Project Manager
FCR – Firewall Change Request (Any new or old firewall rule nr. which has to be created / modified / deleted)
RTPA – Ready to Production
ORT – Operational Readiness Test (some basic tests to be made and documented), before a server is handed in to RTPA
HPSM – HP Service Manager (a ticket / change web desktop frontend)
Change – a ticket like ID and system which has to be used necessery to describe any server config / file / service modification
Ticket – A support ticket oped in case of some emergency with some server service happens
CI = Configuration Item
Instance – Any service that is running more than once on a server lets (say 2 MySQL and 2 Apache servers) running on same server on different port numbers will be 4 instances
LB = Load Balancer (Load Balancers include capabilities of Intelligent Switches are in essence routers which can balance load ovr number of hosts running different services in order to ensure traffic received to a service is balanced between members of a cluster most often they're Active and Standby. Different methods to load balance traffic exist round-robin etc., traffic to Apache / MySQL / PostgreSQL and virtually any service could be load balanced.
SD – Solution Design / Solution Designer (The person preparing the graphics and documentation for how a combination of servers environment will be operating)
MTR – Maximum Time to Repair (Maximum time to repair client service or env, lets say 2 hours / 5 / 10 hrs)
SLA = Service Level Agreement (Agreement document between Company Corporation and End customer about services / servers or any work to be provided under what conditions and cost and time interval. In short SLA is a contract document between Corporation and customer.
Service Window – Mon – Fri 08:00 – 17:00 (The time in which server is on active support and will has to be repaired by a support team promptly if emergency occurs)
TOP Process – Turn to Production (The processes which PM follows, before project turns to production TTP).
Top Approver – The list of people involved in project which has to approve the Top process until set as completed.
DL / CCL – Delivery Lead / Collaboration Capability Lead / Client
Capability Lead – This is a job position one step behind a Team Manager. DL's goals are to help teams manage internal issues and deal with clients requests, next to doing some minor technical job. In short this position is like a Junior Manager (or a position which is held before), people emerge to Team Managers.
TDL – Technical Delivery Lead
Prod or just P env – Production environment (if many servers) or P server if it is single one
QA env – Quality Assurance (something like a testing environment or server)
UAT (User Acceptance Testing) / Test server, env – UAT is the last phase of software testing process.
During UAT, actual software users test the software to make sure it can handle required tasks in real-world scenarios, according to specifications. UAT is also known as beta testing
Test server usually same configuration as Prod whose purpose is to test new releases before deployed to Prod environment
DNS Internal / External record – (Whether DNS is seen only in a client local network (from Internal DNS only) – its called Internal record, External record is when a hostname is resolved from all the Internet)
EMEA – Common Abbreviation for: Europe, Middle East Asia sometimes to mean Europe Middle East, Africa
DC – Data Center (location) in some address room / rack numbers etc.
SN – Serial Number (Serial number of server or hardware component
DB – Server Database (DataGuard is Oracle Db special solution for synchronization of databases for higher Db protection)
Security Class – The levels of security of access to a server (Different countries and Unions legislation world-wide require different rules and regulations on server security).
Examples of Server security classes are: White, Grey, Black (servers). For example according to EU legislation Black servers
can only be administrated / managed by people originating from
same country as where server is physically located.
Digital Key / (Digital Certificate) / Active Identity – This is a Flash drive USB (storage) with installed digital certificate which is used to authenticate you to internel corporate network
PC COE – PC COE – is a set of services and tools that has helped HP reduce its desktop computing costs by $200 million per year. HP also establishes a new organization within the HP OpenView division to market TCO solutions. From PC-COE you can install almost all proprietary software for free and use them for your daily work. The software comes with free Licensing for internal HP Use.
Junos Pulse / Remote Access to HP Network – Dynamic SSL VPN Connectivity at most companies to access a corporate network you connect via some encrypted VPN client, some companies probably use OpenVPN.
Citrix Receiver – Citrix Receiver is the easy-to-install client software that provides access to your XenDesktop and XenApp installations. With this free download you can access applications, desktops and data easily and securely from any device, including smartphones, tablets, PCs and Macs
Above terminology is specific to HP however, most of the terminology and procedures during onboarding time (period) should be very similar or even the same for other of the Top 100 Largest Companies by Revenue such as:
IBM, Dell, E.ON, Apple, Samsung, Toyota, Daimler, Gazprom, RosNeft, Volkswagen Group, Honda, AT&T, General Motors, Allianz, LukOil, Carrefour, Siemens, BASF, Philips, Ford Motor Company, Koch Industries, Tesco, Royal Dutch Shell, BP, Chevron, Vitol, SK Group, Verizon, General Electric, Wal-Mart Stores, Nestle etc.
Probably there are things I'm missing so, if there is something else you have learned understand during onboarding, please share it in comments!
That's it, Happy Onboarding !!! 🙂







