I’ve been experimenting since some time in order to understand better what is the current situation with Video Desktop Capturing Software available today for Linux and FreeBSD.
My previous investigations has led me to write an article about xvidcap called How to make Video from your Linux Desktop with xvidcap
Though xvidcap works pretty well, it is currently uncapable of capturing the audio stream of a Linux Desktop env and hence part of the interactivity of the videos is missing when used.
A bit of further investigation on the topic has pointed me to 3 free software programs which are capable to record Desktop environment on Linux with sound embedded
The interesting screen video capturing Desktop tools I’ve found are:
1. recordMyDesktop
2. Istanbul
and
3. vnc2swf
Installing them on a Debian based distribution is pleasable, as there are installable debian packages of each one which I installed easily with apt:
debian:~# apt-get install istanbul recordmydesktop gtk-recordmydesktop vnc2swf
RecordMyDesktop‘s package contains a command line little tool which when started directly starts capturing video and audio of the Linux Desktop. After a Ctrl+C is pressed the program quits, saves and encodes the video in ogg-encapsulated theora-vorbis file format.
Here is the output I got in saving a sample file by launching recordmydesktop without any arguments:
hipo@debian:~/Desktop$ recordmydesktop
Initial recording window is set to:
X:0 Y:0 Width:1024 Height:768
Adjusted recording window is set to:
X:0 Y:0 Width:1024 Height:768
Your window manager appears to be Metacity
Initializing…
Buffer size adjusted to 4096 from 4096 frames.
Opened PCM device hw:0,0
Recording on device hw:0,0 is set to:
2 channels at 22050Hz
Capturing!
Broken pipe: Overrun occurred.
Broken pipe: Overrun occurred.
Broken pipe: Overrun occurred.
^C
*********************************************
Cached 5 MB, from 207 MB that were received.
Average cache compression ratio: 97.3 %
*********************************************
Saved 69 frames in a total of 69 requests
Shutting down..Broken pipe: Overrun occurred.
…
STATE:ENCODING
Encoding started!
This may take several minutes.
Pressing Ctrl-C will cancel the procedure (resuming will not be possible, but
any portion of the video, which is already encoded won’t be deleted).
Please wait…
Output file: out.ogv
[100%]
Encoding finished!
Wait a moment please…
Done.
Written 692529 bytes
(635547 of which were video data and 56982 audio data)
Cleanning up cache…
Done!!!
Goodbye!
The captured file as I you see in the above output is saved in file out.ogv
RecordMyDesktop has also a GUI interface (written in Python) called gtk-recordmydesktop
Below you see a screenshot of the GUI gtk-recordmydesktop:
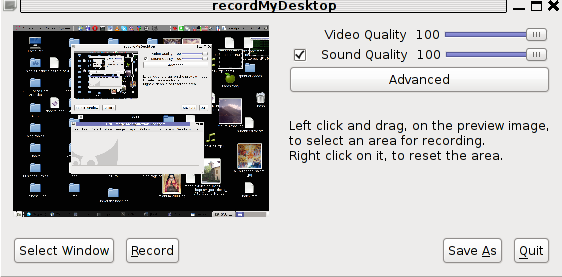
gtk-recordmydesktop is a super-easy to use as you already see in the picture, you can either configure it with Advanced button or use Save As button to select where you want the Desktop captured video and audio to be stored.
In Debian Squeeze 6.0, the Advanced GUI button interface button is not working but that’s not such an issue, as the rest of the buttons works fine.
After the recordmydesktop‘s Record button is pressed it will start capturing from your Desktop and the window seen in the above screenshot will disappear/hide in the system tray:
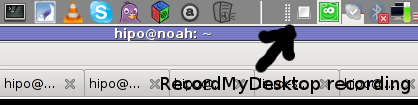
When you press over the white little square in the system tray the screen capturing will be interrupted and a window will pop-up informing you that the captured video and audio is being encoded, here is another screenshot of recordmydesktop encoding a saved Desktop video stream:
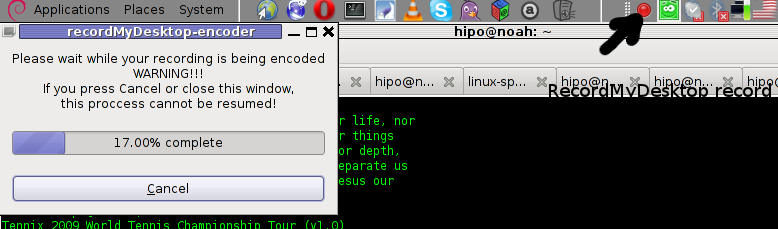
After the final .ogv file is encoded and saved to further transfer it into (.flv) I used ffmpeg;
debian:~# ffmpeg -i test.ogv test.flv
...
Now let’s evaluate a bit on the the final results, the produced test.ogv‘s synchronization between sound and video was not good as the sound was starting earlier than the video and therefore even though recordmydesktop used to be highly praised on the net, the proggie developers still needs to do some bug fixing
Further on, I continued and (gave the other Desktop screen capturer) Istanbul a try hoping that at least with it the video and audio of my Linux desktop will be properly captured. But guess what, the results with Istanbul was even more unsatisfactory as the produced videos and sounds, were slow and a lot of frames from the screens were missing completely.
Moreover the sound which was supposed to accompany the video was completely 🙁
Thus I will skip on talking about Istanbul as in my view, this piece of software is far away from being production ready.
I also tested vnc2swf , launched it by: pressing alt+f2 and typing in vnc2swf in GNOME’s run application prompt, just to be surprised by an error …:
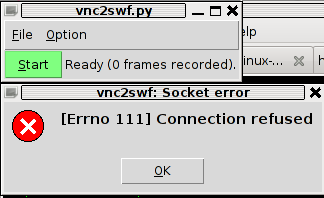
The reason for this error is caused by the xserver (Xorg) port 5900 is being closed by default on Debian
However this error is easily solvable, by making the Xserver to listen to a the port 5900, to make the Xorg server on Debian to listen on this port you need to edit the file:
/etc/X11/xinit/xserverrc
and change inside it:
exec /usr/bin/X -nolisten tcp "$@"
with:
exec /usr/bin/X "$@"
and either reboot your Linux or restart only the Xorg server by pressing Ctrl+Alt+BackSpace
Now let me conclude, the results from my desktop video screen capturing experiments prooved that vnc2swf is superior (as it is capable of properly saving a movie with sound and video from a Linux Desktop). It appears this soft is actually the best one you can use to make a video of your Linux desktop.
Sadly my testing has proven that Linux is still lacking behind Windows and Mac in even doing the most simple tasks …
Let’s hope that situation will get better soon and Gnome or KDE developers will soon provide us with better software capable to save properly a video and audio captured from the Linux Desktop.




