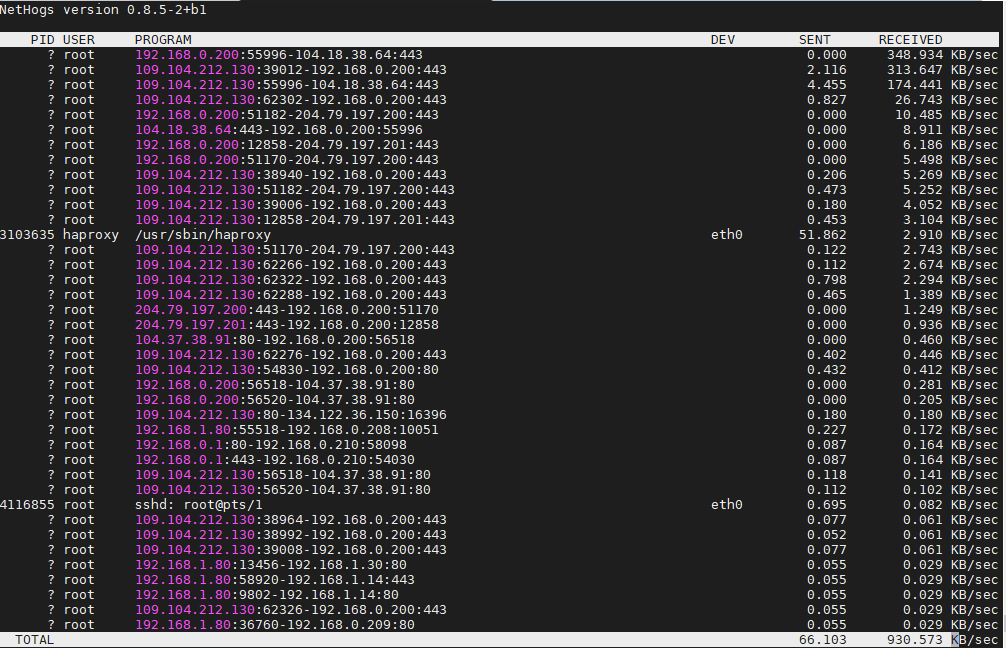
Haproxy could be configured to use the listen stats interface to provide a tiny web interface with statistics on all configured haproxy frontends / backends state status (UP / DOWN), current connections to proxy, errors and other interesting bandwidth information.
That is mostly useful but not every haproxy has it configured and if you did not configure the HAproxy load balancer machines on your own it might be, the previous person who build the LB infrastructure did not create the haproxy listener.
If that is the case and you still need to get various statistics on how haproxy performs and the status of active connections towards Frotnend i/ Backend interfaces this is still possible via configured stats socket (usually this is in Global or some of the other haproxy.cfg config sections..
It is possible to do many things with haproxy such as disable / enable frotnends / backends / servers
Lets say your Haproxy has a global section that looks like this:
global
stats socket /var/run/haproxy/haproxy.sock mode 0600 level admin #Creates Unix-Like socket to fetch stats
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn 99999
nbproc 1
nbthread 2
cpu-map 1 0
cpu-map 2 1
…
1. Listing all available options that can be send via the haproxy.sock UNIX socket interface
root@pcfreak:/home/hipo/info# echo "show help" | socat stdio /var/run/haproxy/haproxy.sock
Unknown command. Please enter one of the following commands only :
help : this message
prompt : toggle interactive mode with prompt
quit : disconnect
show tls-keys [id|*]: show tls keys references or dump tls ticket keys when id specified
set ssl tls-key [id|keyfile] <tlskey>: set the next TLS key for the <id> or <keyfile> listener to <tlskey>
add ssl crt-list <filename> <certfile> [options] : add a line <certfile> to a crt-list <filename>
del ssl crt-list <filename> <certfile[:line]> : delete a line <certfile> in a crt-list <filename>
show ssl crt-list [-n] [] : show the list of crt-lists or the content of a crt-list <filename>
new ssl cert <certfile> : create a new certificate file to be used in a crt-list or a directory
set ssl cert <certfile> <payload> : replace a certificate file
commit ssl cert <certfile> : commit a certificate file
abort ssl cert <certfile> : abort a transaction for a certificate file
del ssl cert <certfile> : delete an unused certificate file
show ssl cert [] : display the SSL certificates used in memory, or the details of a <certfile>
set maxconn global : change the per-process maxconn setting
set rate-limit : change a rate limiting value
set severity-output [none|number|string] : set presence of severity level in feedback information
set timeout : change a timeout setting
show env [var] : dump environment variables known to the process
show cli sockets : dump list of cli sockets
show cli level : display the level of the current CLI session
show fd [num] : dump list of file descriptors in use
show activity : show per-thread activity stats (for support/developers)
operator : lower the level of the current CLI session to operator
user : lower the level of the current CLI session to user
clear counters : clear max statistics counters (add 'all' for all counters)
show info : report information about the running process [desc|json|typed]*
show stat : report counters for each proxy and server [desc|json|typed]*
show schema json : report schema used for stats
show sess [id] : report the list of current sessions or dump this session
shutdown session : kill a specific session
shutdown sessions server : kill sessions on a server
disable agent : disable agent checks (use 'set server' instead)
disable health : disable health checks (use 'set server' instead)
disable server : disable a server for maintenance (use 'set server' instead)
enable agent : enable agent checks (use 'set server' instead)
enable health : enable health checks (use 'set server' instead)
enable server : enable a disabled server (use 'set server' instead)
set maxconn server : change a server's maxconn setting
set server : change a server's state, weight or address
get weight : report a server's current weight
set weight : change a server's weight (deprecated)
show startup-logs : report logs emitted during HAProxy startup
clear table : remove an entry from a table
set table [id] : update or create a table entry's data
show table [id]: report table usage stats or dump this table's contents
add acl : add acl entry
clear acl <id> : clear the content of this acl
del acl : delete acl entry
get acl : report the patterns matching a sample for an ACL
show acl [id] : report available acls or dump an acl's contents
add map : add map entry
clear map <id> : clear the content of this map
del map : delete map entry
get map : report the keys and values matching a sample for a map
set map : modify map entry
show map [id] : report available maps or dump a map's contents
show events [] : show event sink state
show threads : show some threads debugging information
show peers [peers section]: dump some information about all the peers or this peers section
disable frontend : temporarily disable specific frontend
enable frontend : re-enable specific frontend
set maxconn frontend : change a frontend's maxconn setting
show servers conn [id]: dump server connections status (for backend <id>)
show servers state [id]: dump volatile server information (for backend <id>)
show backend : list backends in the current running config
shutdown frontend : stop a specific frontend
set dynamic-cookie-key backend : change a backend secret key for dynamic cookies
enable dynamic-cookie backend : enable dynamic cookies on a specific backend
disable dynamic-cookie backend : disable dynamic cookies on a specific backend
show errors : report last request and response errors for each proxy
show resolvers [id]: dumps counters from all resolvers section and
associated name servers
show pools : report information about the memory pools usage
show profiling : show CPU profiling options
set profiling : enable/disable CPU profiling
show cache : show cache status
trace <module> [cmd [args…]] : manage live tracing
show trace [] : show live tracing state
2. View haproxy running threads
root@pcfreak:/home/hipo/info# echo "show threads" | socat stdio /var/run/haproxy/haproxy.sock
Thread 1 : id=0x7f87b6e2c1c0 act=0 glob=0 wq=1 rq=0 tl=0 tlsz=0 rqsz=0
stuck=0 prof=0 harmless=1 wantrdv=0
cpu_ns: poll=3061065069437 now=3061065077880 diff=8443
curr_task=0
* Thread 2 : id=0x7f87b6e20700 act=1 glob=0 wq=1 rq=0 tl=0 tlsz=0 rqsz=0
stuck=0 prof=0 harmless=0 wantrdv=0
cpu_ns: poll=2969050092523 now=2969050197848 diff=105325
curr_task=0x7f87b006f740 (task) calls=1 last=0
fct=0x560978846340(task_run_applet) ctx=0x7f87b0190720(<CLI>)
strm=0x56097a763560 src=unix fe=GLOBAL be=GLOBAL dst=<CLI>
rqf=c48200 rqa=0 rpf=80008000 rpa=0 sif=EST,200008 sib=EST,204018
af=(nil),0 csf=0x56097a776ef0,8200
ab=0x7f87b0190720,9 csb=(nil),0
cof=0x56097a77fb00,1300:PASS(0x7f87b019a680)/RAW((nil))/unix_stream(22)
cob=(nil),0:NONE((nil))/NONE((nil))/NONE(0)
3. Show haproxy server connections
root@pcfreak:/home/hipo/info# echo "show servers conn" | socat stdio /var/run/haproxy/haproxy.sock
# bkname/svname bkid/svid addr port – purge_delay used_cur used_max need_est unsafe_nb safe_nb idle_lim idle_cur idle_per_thr[2]
http-websrv/ha1server-1 3/1 192.168.0.209 80 – 5000 0 12 12 0 0 -1 0 0 0
http-websrv/ha1server-2 3/2 192.168.0.200 80 – 5000 1 142 142 0 0 -1 0 0 0
http-websrv/ha1server-3 3/3 192.168.1.30 80 – 5000 0 0 0 0 0 -1 0 0 0
http-websrv/ha1server-4 3/4 192.168.1.14 80 – 5000 0 0 0 0 0 -1 0 0 0
http-websrv/ha1server-5 3/5 192.168.0.1 80 – 5000 0 13 13 0 0 -1 0 0 0
https-websrv/ha1server-1 5/1 192.168.0.209 443 – 5000 0 59 59 0 0 -1 0 0 0
https-websrv/ha1server-2 5/2 192.168.0.200 443 – 5000 11 461 461 0 0 -1 0 0 0
https-websrv/ha1server-3 5/3 192.168.1.30 443 – 5000 0 0 0 0 0 -1 0 0 0
https-websrv/ha1server-4 5/4 192.168.1.14 443 – 5000 0 0 0 0 0 -1 0 0 0
https-websrv/ha1server-5 5/5 192.168.0.1 443 – 5000 1 152 152 0 0 -1 0 0 0
MASTER/cur-1 6/1 – 0 – 0 0 0 0 0 0 0 0
4. Show Load balancer servers state
root@pcfreak:/home/hipo/info# echo "show servers state" | socat stdio /var/run/haproxy/haproxy.sock
1
# be_id be_name srv_id srv_name srv_addr srv_op_state srv_admin_state srv_uweight srv_iweight srv_time_since_last_change srv_check_status srv_check_result srv_check_health srv_check_state srv_agent_state bk_f_forced_id srv_f_forced_id srv_fqdn srv_port srvrecord
3 http-websrv 1 ha1server-1 192.168.0.209 2 0 254 254 3929 6 3 4 6 0 0 0 – 80 –
3 http-websrv 2 ha1server-2 192.168.0.200 2 0 255 255 3928 6 3 4 6 0 0 0 – 80 –
3 http-websrv 3 ha1server-3 192.168.1.30 2 0 252 252 3927 6 3 4 6 0 0 0 – 80 –
3 http-websrv 4 ha1server-4 192.168.1.14 2 0 253 253 3929 6 3 4 6 0 0 0 – 80 –
3 http-websrv 5 ha1server-5 192.168.0.1 2 0 251 251 1708087 6 3 4 6 0 0 0 – 80 –
5 https-websrv 1 ha1server-1 192.168.0.209 2 0 254 254 3929 6 3 4 6 0 0 0 – 443 –
5 https-websrv 2 ha1server-2 192.168.0.200 2 0 255 255 3928 6 3 4 6 0 0 0 – 443 –
5 https-websrv 3 ha1server-3 192.168.1.30 2 0 252 252 3927 6 3 4 6 0 0 0 – 443 –
5 https-websrv 4 ha1server-4 192.168.1.14 2 0 253 253 3929 6 3 4 6 0 0 0 – 443 –
5 https-websrv 5 ha1server-5 192.168.0.1 2 0 251 251 1708087 6 3 4 6 0 0 0 – 443 –
6 MASTER 1 cur-1 – 2 0 0 0 1708087 1 0 0 0 0 0 0 – 0 –
5. Get general haproxy info on variables that can be used for Load Balancer fine tuning
root@pcfreak:/home/hipo/info# echo "show info" | socat stdio /var/run/haproxy/haproxy.sock
Name: HAProxy
Version: 2.2.9-2+deb11u5
Release_date: 2023/04/10
Nbthread: 2
Nbproc: 1
Process_num: 1
Pid: 3103635
Uptime: 19d 18h11m49s
Uptime_sec: 1707109
Memmax_MB: 0
PoolAlloc_MB: 1
PoolUsed_MB: 0
PoolFailed: 0
Ulimit-n: 200059
Maxsock: 200059
Maxconn: 99999
Hard_maxconn: 99999
CurrConns: 8
CumConns: 19677218
CumReq: 2740072
MaxSslConns: 0
CurrSslConns: 0
CumSslConns: 0
Maxpipes: 0
PipesUsed: 0
PipesFree: 0
ConnRate: 1
ConnRateLimit: 0
MaxConnRate: 2161
SessRate: 1
SessRateLimit: 0
MaxSessRate: 2161
SslRate: 0
SslRateLimit: 0
MaxSslRate: 0
SslFrontendKeyRate: 0
SslFrontendMaxKeyRate: 0
SslFrontendSessionReuse_pct: 0
SslBackendKeyRate: 0
SslBackendMaxKeyRate: 0
SslCacheLookups: 0
SslCacheMisses: 0
CompressBpsIn: 0
CompressBpsOut: 0
CompressBpsRateLim: 0
ZlibMemUsage: 0
MaxZlibMemUsage: 0
Tasks: 32
Run_queue: 1
Idle_pct: 100
node: pcfreak
Stopping: 0
Jobs: 13
Unstoppable Jobs: 0
Listeners: 4
ActivePeers: 0
ConnectedPeers: 0
DroppedLogs: 0
BusyPolling: 0
FailedResolutions: 0
TotalBytesOut: 744390344175
BytesOutRate: 30080
DebugCommandsIssued: 0
Build info: 2.2.9-2+deb11u5
root@pcfreak:/home/hipo/info# echo "show errors" | socat stdio /var/run/haproxy/haproxy.sock
Total events captured on [14/Dec/2023:17:29:17.930] : 0
6. View all opened sessions and, the session age (time since it has been opened) and session exp (expiry)
root@pcfreak:/home/hipo/info# echo "show sess" | socat stdio /var/run/haproxy/haproxy.sock
0x56097a763560: proto=tcpv4 src=113.120.74.123:54651 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=37s calls=3 rate=0 cpu=0 lat=0 rq[f=848000h,i=0,an=00h,rx=1m58s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=,wx=1m58s,ax=] s0=[8,200000h,fd=24,ex=] s1=[8,40018h,fd=25,ex=] exp=1m51s
0x56097a812830: proto=tcpv4 src=190.216.236.134:35526 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=17s calls=3 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m42s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m42s,wx=,ax=] s0=[8,200008h,fd=40,ex=] s1=[8,200018h,fd=41,ex=] exp=12s
0x56097a784ad0: proto=tcpv4 src=103.225.203.131:33835 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=17s calls=2 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m44s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m44s,wx=,ax=] s0=[8,200008h,fd=20,ex=] s1=[8,200018h,fd=21,ex=] exp=13s
0x7f87b0082cc0: proto=tcpv4 src=190.216.236.134:35528 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=14s calls=3 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m46s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m46s,wx=,ax=] s0=[8,200008h,fd=34,ex=] s1=[8,200018h,fd=35,ex=] exp=15s
0x7f87b0089e10: proto=tcpv4 src=40.130.105.242:50669 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=11s calls=2 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m49s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m49s,wx=,ax=] s0=[8,200008h,fd=15,ex=] s1=[8,200018h,fd=16,ex=] exp=18s
0x7f87b010b450: proto=tcpv4 src=64.62.202.82:37562 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=7s calls=2 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m52s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m52s,wx=,ax=] s0=[8,200008h,fd=26,ex=] s1=[8,200018h,fd=27,ex=] exp=22s
0x56097a7b8bc0: proto=tcpv4 src=85.208.96.211:54226 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=0s calls=2 rate=2 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m59s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m59s,wx=,ax=] s0=[8,200008h,fd=22,ex=] s1=[8,200018h,fd=23,ex=] exp=29s
0x7f87b008ec00: proto=tcpv4 src=3.135.192.206:60258 fe=http-in be=http-websrv srv=ha1server-2 ts=00 age=0s calls=2 rate=2 cpu=0 lat=0 rq[f=848000h,i=0,an=00h,rx=1m59s,wx=1m59s,ax=] rp[f=80008000h,i=0,an=00h,rx=1m59s,wx=1m59s,ax=] s0=[8,200008h,fd=28,ex=] s1=[8,200018h,fd=29,ex=] exp=29s
0x56097a7b2490: proto=tcpv4 src=45.147.249.119:62283 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=0s calls=3 rate=3 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m59s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m59s,wx=,ax=] s0=[8,200008h,fd=17,ex=] s1=[8,200018h,fd=18,ex=] exp=29s
0x7f87b0114f90: proto=unix_stream src=unix:1 fe=GLOBAL be=<NONE> srv=<none> ts=00 age=0s calls=1 rate=1 cpu=0 lat=0 rq[f=c48200h,i=0,an=00h,rx=,wx=,ax=] rp[f=80008002h,i=0,an=00h,rx=,wx=,ax=] s0=[8,200008h,fd=30,ex=] s1=[8,204018h,fd=-1,ex=] exp=
root@pcfreak:/home/hipo/info#
7. Disabling an haproxy frontend via UNIX socket
If you get some frontend that gets broken and this is monitored in Zabbix or other monitoring tool used to monitor you can use the haproxy stats interface to disable frontend
root@pcfreak:/home/hipo/info# echo "disable frontend https-websrv" | socat stdio /var/run/haproxy/haproxy.sock
…
8. Show general haproxy statistics (could tell you much about customer connections health state) and state of connection to backend
Lets check uptime details for frontends / backends, that is done with show stat command.
root@pcfreak:/home/hipo/info# echo "show stat" | socat stdio /var/run/haproxy/haproxy.sock
#
pxname,svname,qcur,qmax,scur,smax,slim,stot,bin,bout,dreq,dresp,ereq,econ,eresp
,wretr,wredis,status,weight,act,bck,chkfail,chkdown,lastchg,downtime,qlimit,
pid,iid,sid,throttle,lbtot,tracked,type,rate,rate_lim,rate_max,check_status
,check_code,check_duration,hrsp_1xx,hrsp_2xx,hrsp_3xx,hrsp_4xx
,hrsp_5xx,hrsp_other,hanafail,req_rate,req_rate_max,req_tot,cli_abrt
,srv_abrt,comp_in,comp_out,comp_byp,comp_rsp,lastsess,last_chk
,last_agt,qtime,ctime,rtime,ttime,agent_status,agent_code,
agent_duration,check_desc,agent_desc,check_rise,
check_fall,check_health,agent_rise,
agent_fall,agent_health,addr,cookie,mode,
algo,conn_rate,conn_rate_max,conn_tot,intercepted
,dcon,dses,wrew,connect,reuse,cache_lookups,
cache_hits,srv_icur,src_ilim,qtime_max,ctime_max,
rtime_max,ttime_max,eint,idle_conn_cur,
safe_conn_cur,used_conn_cur,need_conn_est,
http-in,FRONTEND,,,0,142,99999,371655,166897324,
1462777381,0,0,62,,,,,OPEN,,,,,,,,,1,2,0,,,,0,0,0,
1080,,,,,,,,,,,0,0,0,,,0,0,0,0,,,,,,,,,,,,,,,,,,,,,tcp,,0,1080,
371655,,0,0,0,,,,,,,,,,,0,,,,,
http-websrv,ha1server-1,0,0,0,12,,9635,3893561
,64880833,,0,,0,3,15,0,UP
,254,0,1,41,9,4686,34728,,1,3,1,,4924,,2,0,,56,L4OK
,,0,,,,,,,,,,,900,168,,,,,1292679,,,0,0,0,2843,,,,
Layer4 check passed,,2,3,4,,,,192.168.0.209:80,,tcp,,,,,,,,
0,9635,0,,,0,,0,15024,0,672888,0,0,0,0,12,
http-websrv,ha1server-2,0,0,0,142,,321867,
149300590,1350577153,,0,,
1,4,30,0,UP,255,1,0,37,10,4685,89418,,1,3,2,,111864,,2
,0,,1080,L4OK,,0,,,,,,,,,,,37161,4822,,,,,6,,,0,12,0,
2120,,,,Layer4 check passed,,2,3,4,,,,192.168.0.200:80,,tcp,,,,,,,,0,321867,
0,,,0,,0,30223,0,1783442,0,0,0,0,142,
List continues here
….
…
..
.
9. Using netcat to view UNIX socket instead of socat
If you don't have the socat command on the server but you have netcat installed, you can also send the commands to the running haproxy daemon via nc's capability to send via UNIX socket via nc -U option.
-U Use UNIX-domain sockets. Cannot be used together with -F or -x.
root@pcfreak:/home/hipo/info# echo "set server"|nc -U /var/run/haproxy/haproxy.sock
Require 'backend/server'.
10. Get only statistics about running LB Backends and Frontends
To get only haproxy statistics about running Load Balancer BACKENDs and FRONTENDs
root@pcfreak:/home/hipo/info# echo "show stat" | sudo socat unix-connect:/var/run/haproxy/haproxy.sock stdio | awk -F '.' '/BACKEND/ {print $1, $6}'
http-websrv,BACKEND,0,0,2,142,10000,371880,167022255,1462985601,0,0,,1,7,46,0,UP
,255,1,4,,0,1709835,0,,1,3,0,,118878,,1,0,,1080,,,,,,,,,,,,,,38782,5001,0,0,0,0,5,,,0,8,0,2034
,,,,,,,,,,,,,,tcp,source,,,,,,,0,371864,0,,,,,0,30223,0,1783442,0,,,,,
https-websrv,BACKEND,0,0,5,461,10000,2374328,3083873321,740021649129,0,0,,28,42,626,0,UP
,255,1,4,,0,1709835,0,,1,5,0,,474550,,1,1,,1081,,,,,,,,,,,,,,451783,72307,0,0,0,0,0,,,0,0,0,6651
,,,,,,,,,,,,,,tcp,source,,,,,,,0,2374837,0,,,,,0,32794,0,46414141,0,,,,,
As you can see there are two configured BACKENDs that are in UP state, the other possibility is that they're DOWN if haproxy can't reach the backend.
root@pcfreak:/home/hipo/info# echo "show stat" | sudo socat unix-connect:/var/run/haproxy/haproxy.sock stdio | awk -F '.' '/FRONTEND/ {print $1, $6}'
http-in,FRONTEND,,,2,142,99999,371887,167024040,1462990718,0,0,62,,,,,OPEN
,,,,,,,,,1,2,0,,,,0,1,0,1080,,,,,,,,,,,0,0,0,,,0,0,0,0,,,,,,,,,,,,,,,,,,,,,tcp,,1,1080,371887,,0,0,0,,,,,,,,,,,0,,,,,
https-in,FRONTEND,,,4,461,99999,2374337,3083881912,740021909870,0,0,112,,,,,OPEN
,,,,,,,,,1,4,0,,,,0,1,0,1081,,,,,,,,,,,0,0,0,,,0,0,0,0,,,,,,,,,,,,,,,,,,,,,tcp,,1,1081,2374337,,0,0,0,,,,,,,,,,,0,,,,,
root@pcfreak:/home/hipo/info#
As you can see from the list of show help you can change maxconns supported, change the proxy rate-limit and even in real time change a haproxy.cfg configured section timeouts or even modify ACLs dynamicly for Backends and Frontends.
If you use those to make a modifications to the haproxy, that modifications should been written also to Haproxy's configured instance haproxy.cfg file.
If you want to check it reload the haproxy instance with the new written haproxy.cfg, through the Unix socket.
11. Shutting down specific opened sessions
Shutting down specific session that has been opened for too long is particularly useful to do, especially if you have some kind of VPN encryption device before the Haproxy server and an Application Backend server that is buggy and fails to properly close sessions at time, to cut off a specific sessions that has been hanging for days after reviewing it with "show sess".
root@pcfreak:/home/hipo/info# echo "shutdown session 0x56097a7707d0" | socat stdio /var/run/haproxy/haproxy.sock
12. Sending shutdown to backend on a certain configured LB service
To bring down a configured backend on a certain server after listing it:
root@pcfreak:/home/hipo/info# echo "disable server bk_mybackend/srv_myserver" | socat /var/run/haproxy.sock stdio
12. Sending multiple commands to haproxy socket
# echo "show info;show stat" | socat /var/run/haproxy/haproxy.sock stdio
…
13. Report table usage information or dump table data content
It is possible to view exact queued connections inside the sticky table. To get a list of available, available configured tables on the haproxy
root@pcfreak:/home/hipo/info# echo "show table" | socat /var/run/haproxy/haproxy.sock stdio
# table: https-websrv, type: ip, size:204800, used:498
# table: http-websrv, type: ip, size:204800, used:74
To get the exact record of queued IPs inside https-websrv.
root@pcfreak:/home/hipo/info# echo "show table https-websrv" | socat /var/run/haproxy/haproxy.sock stdio|head -10
# table: https-websrv, type: ip, size:204800, used:502
0x56097a7444e0: key=2.147.73.42 use=0 exp=1090876 server_id=2 server_name=ha1server-2
0x56097a792ac0: key=3.14.130.119 use=0 exp=1038004 server_id=2 server_name=ha1server-2
0x7f87b006a4e0: key=3.15.203.28 use=0 exp=1536721 server_id=2 server_name=ha1server-2
0x56097a7467f0: key=3.16.54.132 use=0 exp=387191 server_id=2 server_name=ha1server-2
0x7f87b0075f90: key=3.17.180.28 use=0 exp=353211 server_id=2 server_name=ha1server-2
0x56097a821b10: key=3.23.114.130 use=0 exp=1521100 server_id=2 server_name=ha1server-2
0x56097a7475b0: key=3.129.250.144 use=0 exp=121043 server_id=2 server_name=ha1server-2
0x7f87b004d240: key=3.134.112.27 use=0 exp=1182169 server_id=2 server_name=ha1server-2
0x56097a754c90: key=3.135.192.206 use=0 exp=1383882 server_id=2 server_name=ha1server-2
14. Show information about Haproxy startup
Sometimes, where logrotation is integrated on the server and haproxy's logs are log rotated to a central logging server, it might be hard to get information about Haproxy startup messages (warnings, errors etc.).
As digging through old haproxy logs might be tedious, you can simply get it via the stats interface.
root@pcfreak:/home/hipo/info# echo "show startup-logs" | socat unix-connect:/var/run/haproxy/haproxy.sock stdio
[WARNING] 327/231534 (3103633) : parsing [/etc/haproxy/haproxy.cfg:62] : 'fullconn' ignored because frontend 'http-in' has no backend capability. Maybe you want 'maxconn' instead ?
[WARNING] 327/231534 (3103633) : parsing [/etc/haproxy/haproxy.cfg:69] : 'maxconn' ignored because backend 'http-websrv' has no frontend capability. Maybe you want 'fullconn' instead ?
[WARNING] 327/231534 (3103633) : parsing [/etc/haproxy/haproxy.cfg:114] : 'maxconn' ignored because backend 'https-websrv' has no frontend capability. Maybe you want 'fullconn' instead ?
[WARNING] 327/231534 (3103633) : config : missing timeouts for frontend 'http-in'.
| While not properly invalid, you will certainly encounter various problems
| with such a configuration. To fix this, please ensure that all following
| timeouts are set to a non-zero value: 'client', 'connect', 'server'.
[WARNING] 327/231534 (3103633) : config : 'option forwardfor' ignored for frontend 'http-in' as it requires HTTP mode.
[WARNING] 327/231534 (3103633) : config : 'option forwardfor' ignored for backend 'http-websrv' as it requires HTTP mode.
[WARNING] 327/231534 (3103633) : config : missing timeouts for frontend 'https-in'.
| While not properly invalid, you will certainly encounter various problems
| with such a configuration. To fix this, please ensure that all following
| timeouts are set to a non-zero value: 'client', 'connect', 'server'.
[WARNING] 327/231534 (3103633) : config : 'option forwardfor' ignored for frontend 'https-in' as it requires HTTP mode.
[WARNING] 327/231534 (3103633) : config : 'option forwardfor' ignored for backend 'https-websrv' as it requires HTTP mode.
15. Disable / Enable health check for haproxy configured backend
Disable health checks is useful, especially on non production server environments, during integration phase of application with Haproxy load balancer.
The general syntax is like this:
> disable health backend/server1
root@pcfreak:/home/hipo/info# echo "show servers state" | socat unix-connect:/var/run/haproxy/haproxy.sock stdio 1
# be_id be_name srv_id srv_name srv_addr srv_op_state srv_admin_state srv_uweight srv_iweight srv_time_since_last_change srv_check_status srv_check_result srv_check_health srv_check_state srv_agent_state bk_f_forced_id srv_f_forced_id srv_fqdn srv_port srvrecord
3 http-websrv 1 ha1server-1 192.168.0.209 2 0 254 254 13709 6 3 4 6 0 0 0 – 80 –
3 http-websrv 2 ha1server-2 192.168.0.200 2 0 255 255 13708 6 3 4 6 0 0 0 – 80 –
3 http-websrv 3 ha1server-3 192.168.1.30 2 0 252 252 13707 6 3 4 6 0 0 0 – 80 –
3 http-websrv 4 ha1server-4 192.168.1.14 2 0 253 253 13709 6 3 4 6 0 0 0 – 80 –
3 http-websrv 5 ha1server-5 192.168.0.1 2 0 251 251 1717867 6 3 4 6 0 0 0 – 80 –
5 https-websrv 1 ha1server-1 192.168.0.209 2 0 254 254 13709 6 3 4 6 0 0 0 – 443 –
5 https-websrv 2 ha1server-2 192.168.0.200 2 0 255 255 13708 6 3 4 6 0 0 0 – 443 –
5 https-websrv 3 ha1server-3 192.168.1.30 2 0 252 252 13707 6 3 4 6 0 0 0 – 443 –
5 https-websrv 4 ha1server-4 192.168.1.14 2 0 253 253 13709 6 3 4 6 0 0 0 – 443 –
5 https-websrv 5 ha1server-5 192.168.0.1 2 0 251 251 1717867 6 3 4 6 0 0 0 – 443 –
6 MASTER 1 cur-1 – 2 0 0 0 1717867 1 0 0 0 0 0 0 – 0 –
Lets disable health checks for ha1server-1 server and http-websrv backend.
root@pcfreak:/home/hipo/info# echo "disable health http-websrv/ha1server-1" | socat unix-connect:/var/run/haproxy/haproxy.sock stdio
To enable back health checks
root@pcfreak:/home/hipo/info# echo "enable health http-websrv/ha1server-1" | socat unix-connect:/var/run/haproxy/haproxy.sock stdio
16. Change weight for server
if you have a round-robin Load balancing configured and already have a predefined configuration on how many percentage of the server to be sent to which application server (e.g. have a configured weight to dynamically change it via UNIX sock iface).
# Change weight by percentage of its original value
# socat unix-connect:/var/run/haproxy/haproxy.sock stdio
> set server be_app/webserv1 weight 50%
# Change weight in proportion to other servers
> set server be_app/webserv1 weight 100
root@pcfreak:/home/hipo/info# socat unix-connect:/var/run/haproxy/haproxy.sock stdio
set server http-websrv/ha1server-1 weight 50%
Backend is using a static LB algorithm and only accepts weights '0%' and '100%'.
17. Draining traffic from server / backend App in case of Maintenance
You can gradually drain traffic away from a particular server if those backend Application server should be put in maintenance mode for update or whatever. The drain option is very interesting and combined with scripting does open a lot of possibilities for the Load balancer system administrator to put an extra automation.
To drain, set server command with the state argument set to drain:
# Drain traffic
> set server backend_app/server1 state drain
# Allow server to accept traffic again
> set server backend_app/server1 state ready
root@pcfreak:/home/hipo/info# socat unix-connect:/var/run/haproxy/haproxy.sock stdio
set server http-websrv/ha1server-1 state drain
root@pcfreak:/home/hipo/info# socat unix-connect:/var/run/haproxy/haproxy.sock stdio
set server http-websrv/ha1server-1 state ready
18. Run Interactive Mode connection to haproxy UNIX stats socket
For a haproxies that has multiple configured proxied rules backends / frontends, it is nice to use the interactive mode.
Instead of processing a single line of semicolon separate commands, HAProxy takes one command at a time and waits for the user.
In interactive mode, HAProxy sends a “>” character and waits for input command. After command is submitted, HAProxy sends back the result and waits for a new command.
The interactive mode is especially useful during phase of integrating a new haproxy towards an application, where multiple things has to be tuned on the fly without, reloading the haproxy again and again.
On RPM based distros socat is compiled to have the readline interactive capability. Thus to use the haproxy haproxy stats connect interactive mode on RHEL / CentOS / Fedora and other RPM based distros simply use:
# socat /var/run/haproxy.sock readline
> show info
Name: HAProxy
Version: 2.2.9-2+deb11u5
Release_date: 2023/04/10
Nbthread: 2
Nbproc: 1
Process_num: 1
Pid: 3103635
Uptime: 19d 20h48m50s
Uptime_sec: 1716530
Memmax_MB: 0
PoolAlloc_MB: 1
PoolUsed_MB: 0
PoolFailed: 0
Ulimit-n: 200059
Maxsock: 200059
Maxconn: 99999
Hard_maxconn: 99999
CurrConns: 9
CumConns: 19789176
CumReq: 2757976
MaxSslConns: 0
CurrSslConns: 0
CumSslConns: 0
Maxpipes: 0
PipesUsed: 0
PipesFree: 0
ConnRate: 0
ConnRateLimit: 0
MaxConnRate: 2161
SessRate: 0
SessRateLimit: 0
MaxSessRate: 2161
SslRate: 0
SslRateLimit: 0
MaxSslRate: 0
SslFrontendKeyRate: 0
SslFrontendMaxKeyRate: 0
SslFrontendSessionReuse_pct: 0
SslBackendKeyRate: 0
SslBackendMaxKeyRate: 0
SslCacheLookups: 0
SslCacheMisses: 0
CompressBpsIn: 0
CompressBpsOut: 0
CompressBpsRateLim: 0
ZlibMemUsage: 0
MaxZlibMemUsage: 0
Tasks: 35
Run_queue: 1
Idle_pct: 100
node: pcfreak
Stopping: 0
Jobs: 14
Unstoppable Jobs: 0
Listeners: 4
ActivePeers: 0
ConnectedPeers: 0
DroppedLogs: 0
BusyPolling: 0
FailedResolutions: 0
TotalBytesOut: 744964070459
BytesOutRate: 0
DebugCommandsIssued: 0
Build info: 2.2.9-2+deb11u5
On Deb (Debian) based distributions such as Debian, Ubuntu Mint Linux, unfortunately the readline inractive mode is disabled due to licensing issues that makes readline not GPL license compliant.
root@pcfreak:/home/hipo/info# socat -V|awk 'NR < 5 || tolower($0) ~ /readline/'
socat by Gerhard Rieger and contributors – see www.dest-unreach.org
socat version 1.7.4.1 on Feb 3 2021 12:58:17
running on Linux version #1 SMP Debian 5.10.179-3 (2023-07-27), release 5.10.0-23-amd64, machine x86_64
features:
#undef WITH_READLINE
There is a workaround to emulate the Intearactive mode on Debians however like this:
root@pcfreak:/home/hipo/info# while [ 1 ]; do socat – /var/run/haproxy/haproxy.sock ; done
show table
# table: https-websrv, type: ip, size:204800, used:511
# table: http-websrv, type: ip, size:204800, used:67
show sess
0x56097a784ad0: proto=tcpv4 src=45.61.161.66:51416 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=1m13s calls=3 rate=0 cpu=0 lat=0 rq[f=848000h,i=0,an=00h,rx=47s,wx=,ax=] rp[f=80048000h,i=0,an=00h,rx=47s,wx=,ax=] s0=[8,200008h,fd=17,ex=] s1=[8,200018h,fd=23,ex=] exp=47s
0x56097a7707d0: proto=tcpv4 src=47.128.41.242:39372 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=16s calls=2 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m45s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m45s,wx=,ax=] s0=[8,200008h,fd=35,ex=] s1=[8,200018h,fd=36,ex=] exp=14s
0x56097a781300: proto=tcpv4 src=54.36.148.40:17439 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=13s calls=2 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m47s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m47s,wx=,ax=] s0=[8,200008h,fd=26,ex=] s1=[8,200018h,fd=28,ex=] exp=17s
0x56097a7fca80: proto=tcpv4 src=18.217.94.243:4940 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=7s calls=2 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m53s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m53s,wx=,ax=] s0=[8,200008h,fd=21,ex=] s1=[8,200018h,fd=22,ex=] exp=23s
0x7f87b00778c0: proto=tcpv4 src=85.208.96.206:51708 fe=https-in be=https-websrv srv=ha1server-2 ts=00 age=4s calls=3 rate=0 cpu=0 lat=0 rq[f=848202h,i=0,an=00h,rx=1m56s,wx=,ax=] rp[f=80048202h,i=0,an=00h,rx=1m56s,wx=,ax=] s0=[8,200008h,fd=20,ex=] s1=[8,200018h,fd=24,ex=] exp=26s
0x56097a80c1e0: proto=unix_stream src=unix:1 fe=GLOBAL be=<NONE> srv=<none> ts=00 age=3s calls=1 rate=0 cpu=0 lat=0 rq[f=c48202h,i=0,an=00h,rx=10s,wx=,ax=] rp[f=80008002h,i=0,an=00h,rx=,wx=,ax=] s0=[8,200008h,fd=15,ex=] s1=[8,204018h,fd=-1,ex=] exp=7s
To end the eternal loop press CTRL + z and kill first detached job %1 run:
# kiill %1
Sum it up what learned
What we learned in this article is how to use socat and netcat to connect and manage dynamically haproxy via its haproxy stats interface, without reloading the proxqy itself. We learned how to view various statistics and information on the proxy, its existing tables, caches, session information (such as age, and expiry). Also you've seen how to disable / enable configured backends as well as get available backends and frontends and their state.
You've seen how the drained option could be used to slowly drain connections towards configured backend, in case if you need to a maintenance on a backend node.
Also was pointed how to shutdown a specific long lived sessions that has been hanging and creating troubles towards app backends.
Finally, you've seen how to open an interactive connection towards the haproxy socket and send commands in a raw with socat (on distros where compiled with readline support) as well shown how to emulate the interactive mode of rest of distros whose socat is missing the readline support.