While browsing I stumbled upon a nice blog article
The arcitle, points at few ways to DUMP the HTTP headers obtained from user browser.
As I'm not proficient with Ruby, Java and AOL Server what catched my attention is a tiny php for loop, which loops through all the HTTP_* browser set variables and prints them out. Here is the PHP script code:
<?php<br />
foreach($_SERVER as $h=>$v)<br />
if(ereg('HTTP_(.+)',$h,$hp))<br />
echo "<li>$h = $v</li>\n";<br />
header('Content-type: text/html');<br />
?>
The script is pretty easy to use, just place it in a directory on a WebServer capable of executing php and save it under a name like:
show_HTTP_headers.php
If you don't want to bother copy pasting above code, you can also download the dump_HTTP_headers.php script here , rename the dump_HTTP_headers.php.txt to dump_HTTP_headers.php and you're ready to go.
Follow to the respective url to exec the script. I've installed the script on my webserver, so if you are curious of the output the script will be returning check your own browser HTTP set values by clicking here.
PHP will produce output like the one in the screenshot you see below, the shot is taken from my Opera browser:
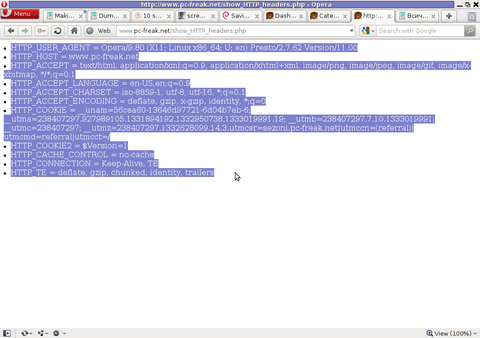
Another sample of the text output the script produce whilst invoked in my Epiphany GNOME browser is:
HTTP_HOST = www.pc-freak.net
HTTP_USER_AGENT = Mozilla/5.0 (X11; U; Linux x86_64; en-us) AppleWebKit/531.2+ (KHTML, like Gecko) Version/5.0 Safari/531.2+ Debian/squeeze (2.30.6-1) Epiphany/2.30.6
HTTP_ACCEPT = application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
HTTP_ACCEPT_ENCODING = gzip
HTTP_ACCEPT_LANGUAGE = en-us, en;q=0.90
HTTP_COOKIE = __qca=P0-2141911651-1294433424320;
__utma_a2a=8614995036.1305562814.1274005888.1319809825.1320152237.2021;wooMeta=MzMxJjMyOCY1NTcmODU1MDMmMTMwODQyNDA1MDUyNCYxMzI4MjcwNjk0ODc0JiYxMDAmJjImJiYm; 3ec0a0ded7adebfeauth=22770a75911b9fb92360ec8b9cf586c9;
__unam=56cea60-12ed86f16c4-3ee02a99-3019;
__utma=238407297.1677217909.1260789806.1333014220.1333023753.1606;
__utmb=238407297.1.10.1333023754; __utmc=238407297;
__utmz=238407297.1332444980.1586.413.utmcsr=www.pc-freak.net|utmccn=(referral)|utmcmd=referral|utmcct=/blog/
You see the script returns, plenty of useful information for debugging purposes:
HTTP_HOST – Virtual Host Webserver name
HTTP_USER_AGENT – The browser exact type useragent returnedHTTP_ACCEPT – the type of MIME applications accepted by the WebServerHTTP_ACCEPT_LANGUAGE – The language types the browser has support for
HTTP_ACCEPT_ENCODING – This PHP variable is usually set to gzip or deflate by the browser if the browser has support for webserver returned content gzipping.
If HTTP_ACCEPT_ENCODING is there, then this means remote webserver is configured to return its HTML and static files in gzipped form.
HTTP_COOKIE – Information about browser cookies, this info can be used for XSS attacks etc. 🙂
HTTP_COOKIE also contains the referrar which in the above case is:
__utmz=238407297.1332444980.1586.413.utmcsr=www.pc-freak.net|utmccn=(referral)
The Cookie information HTTP var also contains information of the exact link referrar:
|utmcmd=referral|utmcct=/blog/
For the sake of comparison show_HTTP_headers.php script output from elinks text browser is like so:
* HTTP_HOST = www.pc-freak.net
One good reason, why it is good to give this script a run is cause it can help you reveal problems with HTTP headers impoperly set cookies, language encoding problems, security holes etc. Also the script is a good example, for starters in learning PHP programming.
* HTTP_USER_AGENT = Links (2.3pre1; Linux 2.6.32-5-amd64 x86_64; 143x42)
* HTTP_ACCEPT = */*
* HTTP_ACCEPT_ENCODING = gzip,deflate * HTTP_ACCEPT_CHARSET = us-ascii, ISO-8859-1, ISO-8859-2, ISO-8859-3, ISO-8859-4, ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8, ISO-8859-9, ISO-8859-10, ISO-8859-13, ISO-8859-14, ISO-8859-15, ISO-8859-16, windows-1250, windows-1251, windows-1252, windows-1256,
windows-1257, cp437, cp737, cp850, cp852, cp866, x-cp866-u, x-mac, x-mac-ce, x-kam-cs, koi8-r, koi8-u, koi8-ru, TCVN-5712, VISCII,utf-8 * HTTP_ACCEPT_LANGUAGE = en,*;q=0.1
* HTTP_CONNECTION = keep-alive




