A colleague of mine (Vasil) asked me today, how he can recursively chmod to all files in a directory whileexclude unreadable files for chmod (returning permission denied). He was supposed to fix a small script which was supposed to change permissions like :
Above find will print all files in . – current directory from where find is started, except files: onenote and file. To exclude
Search and show all files in Linux / UNIX except hidden . (dot) files
Another thing he wanted to do is ignore printing of hidden . (dot) files like .bashrc, .profile and .bash_history while searching for files – there are plenty of annoying .* files.
To ignore printing with find all filesystem hidden files from directory:
find . -type f ( -iname "*" ! -iname ".*" )
on web hosting webservers most common files which is required to be omitted on file searches is .htaccess
Another useful Linux find use for scripting purposes is listing only all files presented in current directory (simulating ls), in case if you wonder why on earth to use find and not a regular ls command?, this is useful for scripts which has to walk through millions of files (for reference see how to delete million of files in same folder with Linux find):
find . ! -name . -prune
./packages ./bin ./package
"! -name . " – means any file other than current directory
prune – prunes all the directories other than the current directory.
A more readable way to list only files in current folder with find is – identical to what above cmd:
find ./* -prune
./packages ./bin ./mnt
If you want to exclude /mnt folder and its sub-directories and files with find by using prune option:
There are plenty of Apache Performance Optimization things to do on a new server. However many sysadmins miss .htaccess mod_rewrite rules whole optimization often leads to a dramatic performance benefits and low webserver responce time, making website much more attractive for both Search Engine Crawlers and End User experience.
Normally most Apache + PHP CMS systems, websites, blogsetc. are configured to use various goodies of .htaccess files (mostly mod_rewrite rules, directory htpasswd authentication and allow forbid directives). All most popular open-source Content management systems like Drupal, Joomla, WordPress, TYPO3, Symphony CMS are configured to get use .htaccess file usually living in the DocumentRoot of a virtualhost ( website/s ) – httpd.conf , apache2.conf /etc/apache2/sites-enabled/customvhost.com or whichever config the Vhost resides…
It is also not uncommon practice to enable .htaccess files to make programmers life easier (allowing the coder to add and remove URL rewrite rules that makes URL pretty and SEO friendly, handle website redirection or gives live to the framework like it is the case with Zend PHP Framework).
However though having the possibility to get the advantages of dynamically using .htaccess inside site DocRoot or site's subdirectories is great for developers it is not a very good idea to have the .htaccess turned on Production server environment.
Having
AllowOverride All
switched on for a directory in order to have .htaccess enabled, makes the webserver lookup for .htaccess file and re-read its content dynamically on each client request. This has a negative influence on overall server performance and makes Apache preforked childs or workers (in case of mpm-worker engine used) to waste time parsing .htaccess file leading to slower request processing.
Normally a Virtualhost with enabled .htaccess looks like so:
Now CMS uses the previous .htaccess rules just as before, however to put more rewrite rules into the file you will need to restart webserver which is a downside of using rewrite rules through theInclude directive. Using the Include directive instead of AllowOverride leads to 7 to 10% faster individual page loads.
I have to mention Include directive though faster has a security downside because .htaccess files loaded with Include option (uses mod_include) via httpd.conf doesn't recognize <Directory> … </Directory> set security rules. Also including .htaccess from configuration on Main Website directory, could make any other sub-directories .htaccess Deny / Allow access rules invalid and this could expose site to security risk. Another security downside is because Include variable allows loading a full subset of Apache directives (including) loading other Apache configuration files (for example you can even override Virtualsthost pre-set directives such as ErrorLog, ScriptAlias etc.) and not only .htaccess standard directives allowed by AllowOverride All. This gives a potential website attacker who gains write permissions over the included /var/www/website/.htaccess access to this full set of VirtualHost directives and not only .htaccess standard allowed.
Because of the increased security risk most people recommend not to use Include .htaccess rules, however for those who want to get the few percentage page load acceleration of using static Include from Apache config, just set your Included .htaccess file to be owned by user/group root, e.g.:
I've been recently writting this Apache webserver / Tomcat / JBoss / Java decomissioning bash script. Part of the script includes extraction from httpd.conf of DocumentRoot variable configured for Apache host. I was using following one liner to grep and store DocumentRoot set directory into new variable:
Above line greps for documentroot prints 2nd column of the matchi (which is the Apache server set docroot and then removes any " chars).
However I faced the issue that parsed string contained in $documentroot variable there was mysteriously containing r – return carriage – this is usually Carriage Return (CR) sent by Mac OS and Apple computers. For those who don't know the End of Line of files in UNIX / Linux OS-es isLF – often abreviated as n – often translated as return new line), while Windows PCs use for EOF CR + LF – known as the infamous rn. I was running the script from the server which is running SuSE SLES 11 Linux, meaning the CR + LF end of file is standardly used, however it seem someone has editted the httpd.conf earlier with a text editor from Mac OS X (Terminal). Thus I needed a way to remove the r from CR character out of the variable, because otherwise I couldn't use it to properly exec tar to archive the documentroot set directory, cause the documentroot directory was showing unexistent.
Opening the httpd.conf in standard editor didn't show the r at the end of "directory", e.g. I could see in the file when opened with vim
DocumentRoot "/usr/local/apache/htdocs/site/www"
However obviously the r character was there to visualize it I had to use cat command -v option (–show-nonprinting):
6. Converting file DOS / UNIX OSes with dos2unix and unix2dos command line tools
For sysadmins who don't want to bother with writting code to convert CR when moving files between Windows and UNIX hosts there are dos2unix and unix2dos installable commands.
If you are logged in to Oracle SQL server with sqlplus and you're not sure to which Database, Tables, Object instances you have permissions to below 2 queries will be of use:
SQL> SELECT DISTINCT OWNER, OBJECT_NAME FROM ALL_OBJECTS WHERE OBJECT_TYPE = 'TABLE';
Query lists all queries in a Oracle table schema. Alternavite shorter way to do the query is via:
SQL> SELECT table_name FROM user_tables;
SQL> SELECT * FROM TAB;
Shows your own schema's all tables and views.
Other oracle useful query is the Oracle equivalent of MySQLSHOW TABLES;
SQL> SELECT table_name FROM user_tables;
It will also output info only for logged in user credentials, if you're logged in as oracle database administrator (DBA role) account and you would like to check what Instances are owned by any user lets say user GEORGI query should be;
SQL> SELECT DISTINCT OWNER, OBJECT_NAME FROM ALL_OBJECTS WHERE OBJECT_TYPE = 'TABLE' AND OWNER = 'GEORGI;
Other way to do it is via:
SQL> SELECT Table_Name from All_Tables WHERE OWNER = 'YOURSCHEMA';
Recently I blogged a tiny article on how to add line numbering to ASCII text files with nl cmd. Today I needed to do the same line numbering, except I wanted to add a prefix text "R0" to each line number to match requirements of program which will later take use of .txt database file. I looked through nl (number lines) command manual but didn't find option with which I can insert a prefix string to each numbered line. I'm not a regular expression GURU, thus I asked for some help in irc.freenode.net on how to do it. Thanks to the kind guys in #bash I got it.
Here is how to add line numbering starting from 01onwards by adding a text prefix "R0":
The file to number in my case included a huge text file containing verses from Holy Bible, here is few lines from it before and after parsing and numbering with string prefix:
In the beginning God created the heaven and the earth. — Genesis 1:1 % And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters. — Genesis 1:2 % And God said, Let there be light: and there was light. — Genesis 1:3
R001 In the beginning God created the heaven and the earth. R002 — Genesis 1:1 R003 % R004 And the earth was without form, and void; and darkness was upon R005 the face of the deep. And the Spirit of God moved upon the face of R006 the waters. R007 — Genesis 1:2 R008 % R009 And God said, Let there be light: and there was light. R010 — Genesis 1:3
To add any other prefix except R0 for example SAMPLE_PREFIX_STRING, substitute in above awk expression R0 with whatever expression;
As a system administrator, sometimes is necessary to do basic plain text processing for various sysadmin tasks. One very common task I do to remove empty lines in file. There are plenty of ways to do it i.e. – with grep, sed, awk, bash, perl etc.
1. Deleting empty file lines with sed
The most standard way to do it is with sed, as sed was written to do in shell quick regexp. Here is how;
sed '/^\s*$/d' file_with_empty_lines.txt > output_no_empty_lines.txt
2. Deleting empty file lines with awk
It is less of writting with awk, but I always forget the syntax and thus I like more sed, anyways here is how with awk;
Listing all table names from a MySQL database is a very easy and trivial task that every sql or system administrator out there is aware of.
However excluding certain table names from a whole list of tables belonging to a database is not that commonly used and therefore I believe many people have no clue how to do it when they have to.
Today for one of my sql backup scripts it was necessary that certain tables from a database to be excluded from the whole list of tables for a database I’m backupping. My example database has the sample name exampledatabase and usually I do list all the table contents from that database with the well known command:
mysql> SHOW tables from exampledatabase;
However as my desire was to exclude certain tables from the list (preferrably with a certain SQL query) I had to ask around in irc.freenode.net for some hints on a ways to achieve my exclude table goals.
I was adviced by some people in #mysql that what I need to achieve my goal is the information_schema mysql structure, which is available since MySQL version 5.0.
After a bit of look around in the information_schema and the respective documentation on mysql.com, thanksfully I could comprehend the idea behind the information_schema, though to be honest the first time I saw the documentation it was completly foggy on how to use this information_schema; It seems using the information_schema is very easy and is not much different from your normal queries syntax used to do trivial operations in the mysql server.
If you wonder just like I did what is mysql’s information_schema go and use the information_schema database (which I believe is a virtual database that is stored in the system memory).
To get a general view on what each of the tables in the information_schema database contains I used the normal SELECT command for example
mysql> select * from TABLES limit 10;
I used the limit clause in order to prevent being overfilled with data, where I could still see the table fields name to get general and few lines of the table to get an idea what kind of information the TABLES table contains.
If you haven’t got any ecperience with using the information_schema I would advice you do follow my example select and look around through all the listed tables in the information_schema database
That will also give you a few hints about the exact way the MySQL works and comprehends it’s contained data structures.
In short information_schema virtual database and it’s existing tables provides a very thorough information and if you’re an SQL admin you certainly want to look over it every now and then.
A bit of playing with it lead me to a command which is actually a good substitute for the normal SHOW TABLES; mysql command. To achieve a SHOW TABLES from exampledatabase via the information_schema info structure you can for example issue:
select TABLE_NAME from TABLES where TABLE_SCHEMA='exampledatabase';
Now as I’ve said a few words about information_schema let me go back to the main topic of this small article, which is How to exclude table names from a SHOW tables list
Here is how exclude a number of tables from a complete list of tables belonging to a database:
select TABLE_NAME from TABLES where TABLE_SCHEMA='exampledatabase'
AND TABLE_NAME not in
('mysql_table1_to_exlude_from_list', 'mysql_table2_to_exclude_from_list', 'table3_to_exclude');
In this example the above mysql command will list all the tables content belonging to exampledatabase and instruct the MySQL server not to list the table names with names mysql_table1_to_exlude_from_list, mysql_table2_to_exclude_from_list, table3_to_exclude
If you need to exclude more tables from your mysql table listing just add some more tables after the …’table3_to_exclude’, ‘new_table4_to_exclude’,’etc..’);
Of course this example can easily be adopted to a MySQL backup script which requires the exclusion of certain tables from a backed up database.
An example on how you can use the above table exclude command straight from the bash shell would be:
debian:~# echo "use information_schema; select TABLE_NAME from TABLES where
TABLE_SCHEMA='exampledatabase' AND TABLE_NAME not in
('mysql_table1_to_exlude_from_list', 'mysql_table2_to_exclude_from_list', 'table3_to_exclude',);"
| mysql -u root -p
Now this little bash one-liner can easily be customized to a backup script to create backups of a certain databases with a certain tables (e.g. with excluded number of tables) from the backup.
It’s seriously a pity that by default the mysqldump command does not have an option for a certain tables exclude while making a database dump. I’ve saw the mysqldump exclude option, being suggested somewhere online as a future feature of mysqldump, I’ve also seen it being reported in the mysql.com’s bug database, I truly hope in the upcoming releases we will see the exclude option to appear as a possible mysqldump argument.
A friend of mine (Dido) who is learning C programming, has written a tiny chat server / client (peer to peer) program in C. His program is a very good learning curve for anyone desiring to learn basic C socket programming. The program is writen in a way so it can be easily modified to work over UDP protocol with code:
To Use the client/server compile on the server host tiny-chat-serer-client.c with:
$ cc -o tiny-chat-server tiny-chat-server.c
Then on the client host compile the client;
$ cc -o tiny-chat-client tiny-chat-client.c
On the server host tiny-chat-server should be ran with port as argument, e.g. ;
$ ./tiny-chat-server 8888
To chat with the person running tiny-chat-server the compiled server should be invoked with:
$ ./tiny-chat-client 123.123.123.123 8888
123.123.123.123 is the IP address of the host, where tiny-chat-server is executed. The chat/server C programs are actually a primitive very raw version of talk.
The programs are in a very basic stage, there are no condition checks for incorrectly passed arguments and with wrongly passed arguments it segfaults. Still for C beginners its useful …
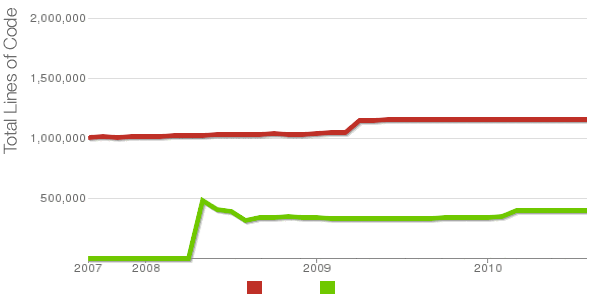
Being able to count the number of PHP source code lines for a website is a major statistical information for timely auditting of projects and evaluating real Project Managment costs. It is inevitable process for any software project evaluation to count the number of source lines programmers has written. In many small and middle sized software and website development companies, it is the system administrator task to provide information or script quickly something to give info on the exact total number of source lines for projects.
Even for personal use out of curiousity it is useful to know how many lines of PHP source code a wordpress or Joomla website (with the plugins) contains. Anyone willing to count the number of PHP source code lines under one directory level, could do it with:::
This will count and show statistics, for each and every PHP source file within wordpress-website (non-recursively), to get only information about the total number of PHP source code lines within the directory, one could grep it, e.g.:::
server:/var/www/wordpress-website:# wc -l *.php |grep -i '\stotal$' 4280 total
The command grep -i '\stotal$' has \s in beginning and $ at the end of total keyword in order to omit erroneously matching PHP source code file names which contain total in file name; for example total.php …. total_blabla.php …. blabla_total_bla.php etc. etc.
The \s grep regular expression meaning is "put empty space", "$" is placed at the end of tital to indicate to regexp grep only for words ending in string total.
So far, so good … Now it is most common that instead of counting the PHP source code lines for a first directory level to count complete number of PHP, C, Python whatever source code lines recursively – i. e. (a source code of website or projects kept in multiple sub-directories). To count recursively lines of programming code for any existing filesystem directory use find in conjunction with xargs:::
As you see the cmd counts and displays the number of source code lines encountered in each and every file, for big directory structures the screen gets floated and passing | less is nice, e.g.:
find . -name '*.php' | xargs wc -l | less
Displaying lines of code for each file within the directories is sometimes unnecessery, whether just a total number of programming source code line is required, hence for scripting purposes it is useful to only get the source lines total num:::
For more professional and bigger projects using pure Linux bash and command line scripting might not be the best approach. For counting huge number of programming source code and displaying various statistics concerning it, there are two other tools – SLOCCount as well as clock (count lines of code)
As I've pointed earlier there is plenty of "secretly" kept and less known by public research on how colors influence us daily. The biggest companies are heavily taking advantage of what is found and known for colors impact on our minds (psyche). Actually there is a whole branch in psychology which deals with impact of colors perception on us.Besides companies, many modern governments are well aware of the many facts on how citizens percept colors and use this in color 'installment' in government offices and government institutions.
There is no universal knowledge on how colors completely affect us as every human on earth is very unique and saying this or that color has this or that impact on indivirual or group is not 100% accurate. However there are general traits nowdays formed especially with globalization and unification of TV ads and big companies corporate image, a unification started on how different nationality people perceive colors.
Nowdays in developed countries there are more and more people who perceive certain colors in similar fashion. Therefore every serious top marketer should carefully study colors and their relation with ancient time people believes and understanding on what each of the 'rainbow' colors symbolize. Most likely because there is no completely unified understanding of colors between various individuals may companies like Google and Microsoft started using all the rainbow colors in their basic company logos and branding for more on this topic please check my previous blog post Color trick Microsoft and Google use to keep their users loyal
Another large industry area, where color programming is very heavy is Computer and Video Games. You certainly still remember large portions of the games like Sega’s Sonic the HendgeHog or Mario Super Bros. or even the old arcade machines with games like Punisher or Cadillacs and Dinosaurs, Street Fighter etc. All this old arcade games have a big portion of Color programming embedded in and this is one of the main reasons we remember them for a long time and playing them evoked such a strong feelings in youth.
This trend of using colors to make up our minds is being observed for many other physical goods as well as is starting to get more and more heavy adoption by websites branding on the internet. Actually those with most succesful businesses on the internet have already integrated some kind of color programming scheme. An example for this would be the Internet top domain names seller GoDaddy. The have adopted a green scheme as a primary color combined with some other ones to create in the customer a feeling of ecology, naturality, peace and solitude.
The study of color programming is one major field to be known by anyone truly willing to understand why certain big store chainslike Carrefour, Lidl, Billa, MediaMarkt – in western europe or TechnoMarket, TechnoPolis (MediaMarkt copied tech equipment by shops here in Bulgaria) are decorated inside the way they are. I personally didn't like the concept of color programming since from Spiritual point of view it is a big evil. Trying to manipulate people perception to do something you would like to in general is very evil from spiritual point of view. A mixture of rainbow colors in a natural environment for example flowers in the wood or wild mountain place is one thing, but making it artificial and placing it in certain pre-desired order is totally another. Besides that the colors in the natural environment are natural and therefore the impact on us even if colorful is very much better than if it is done with a certain intention like in the big supermarkets stores, fast just food companies – McDonalds, Burger King etc.
The research on color mind influcence – Color mind programming is a controversial science. Nowdays many big businesses however use this as a granted science, even whole business sects with some mambo-jambo believes universities, children garden and schools in modern countries have employed the use of some type of color programming aiming to influence their pupils, students (organizational members – you call it). Color mind programming and heavy use on advertisements on the TV, the Internet, Stores and mostly everywhere are however starting to took their tolls. The high increase in mental problems and dumbness in developed and some undeveloped countries as well as the increased number of people who go insane because of too much color programming is reality. The believe that mental programming is one of the ultimate tools to influence somebody and push him to do things you want like consome more of a product or generally consume (buy) more goods creates another severe issue it makes people to constantly over-consume (eat more than the body needs) and this increases the number of over-consumption evoked diseases …
But color programming doesn't stop with just the material (physical) surrounding world it is a concept highly employed in online based marketing. Online business is seen on so many top used websites, social networks like take for instance (facebook). It is so spread that even the software primary vendors like Microsoft, search engines Google Inc. have already heavily employed the color programming as a basis of their products.
There is another reason why most vendors nowdays issue their physical or 'virtual' products so colorful using all the colors of the rainbow. The reason is the fact that as a kids through animation, cartoons, toys and surrounding environment we have been exposed already even from our very youth age to a kind of color programming through kids toys we've been given by our parents). Hence the young years color programming became a basis for a future time color programming. The colorfulness of our kids years are already sub-consciously stored in our minds, so almost naturally there is a feeling of joy to pop-up once we see something childishly colorful.