In my last article How to create multiple haproxy instance separate processes for different configuration listeners, I've shortly explained how to create a multiple instances of haproxies by cloning the systemd default haproxy.service and the haproxy.cfg to haproxyX.cfg.
But what if you need also to configure a separate logging for both haproxy.service and haproxy-customname.service instances how this can be achieved?
The simplest way is to use some system local handler staring from local0 to local6, As local 1,2,3 are usually used by system services a good local handler to start off would be at least 4.
Lets say we already have the 2 running haproxies, e.g.:
[root@haproxy2:/usr/lib/systemd/system ]# ps -ef|grep -i hapro|grep -v grep
root 128464 1 0 Aug11 ? 00:01:19 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock
haproxy 128466 128464 0 Aug11 ? 00:49:29 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock
root 346637 1 0 13:15 ? 00:00:00 /usr/sbin/haproxy-customname-wrapper -Ws -f /etc/haproxy/haproxy_customname_prod.cfg -p /run/haproxy_customname_prod.pid -S /run/haproxy-customname-master.sock
haproxy 346639 346637 0 13:15 ? 00:00:00 /usr/sbin/haproxy-customname-wrapper -Ws -f /etc/haproxy/haproxy_customname_prod.cfg -p /run/haproxy_customname_prod.pid -S /run/haproxy-customname-master.sock
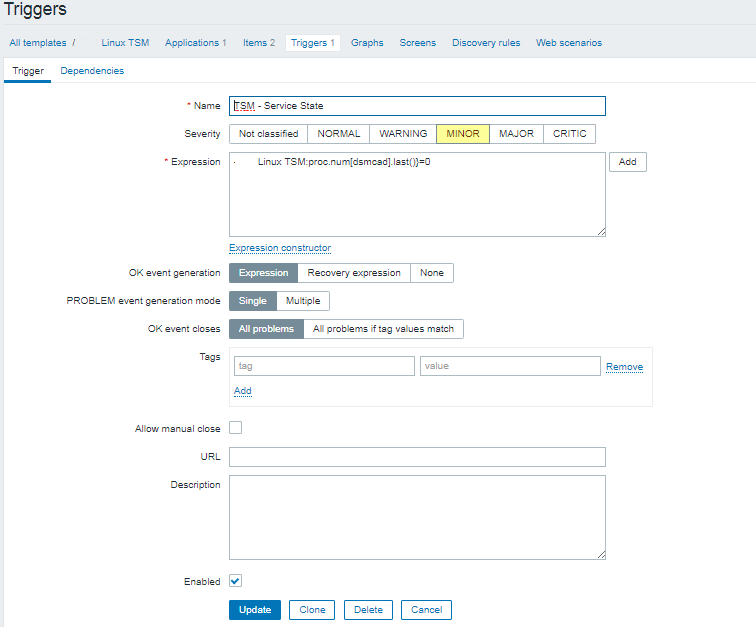
1. Configure local messaging handlers to work via /dev/log inside both haproxy instance config files
To congigure the separte logging we need to have in /etc/haproxy/haproxy.cfg and in /etc/haproxy/haproxy_customname_prod.cfg the respective handlers.
To log in separate files you should already configured in /etc/haproxy/haproxy.cfg something like:
global
stats socket /var/run/haproxy/haproxy.sock mode 0600 level admin #Creates Unix-Like socket to fetch stats
log /dev/log local0
log /dev/log local1 notice
# nbproc 1
# nbthread 2
# cpu-map auto:1/1-2 0-1
nbproc 1
nbthread 2
cpu-map 1 0
cpu-map 2 1
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn 99999
defaults
log global
mode tcp
timeout connect 5000
timeout connect 30s
timeout server 10s
timeout queue 5s
timeout tunnel 2m
timeout client-fin 1s
timeout server-fin 1s
option forwardfor
maxconn 3000
retries 15
frontend http-in
mode tcp
option tcplog
log global
option logasap
option forwardfor
bind 0.0.0.0:80
default_backend webservers_http
backend webservers_http
fullconn 20000
balance source
stick match src
stick-table type ip size 200k expire 30m
server server-1 192.168.1.50:80 check send-proxy weight 255 backup
server server-2 192.168.1.54:80 check send-proxy weight 254
server server-3 192.168.0.219:80 check send-proxy weight 252 backup
server server-4 192.168.0.210:80 check send-proxy weight 253 backup
server server-5 192.168.0.5:80 maxconn 3000 check send-proxy weight 251 backup
For the second /etc/haproxy/haproxy_customname_prod.cfg the logging configuration should be similar to:
global
stats socket /var/run/haproxy/haproxycustname.sock mode 0600 level admin #Creates Unix-Like socket to fetch stats
log /dev/log local5
log /dev/log local5 notice
# nbproc 1
# nbthread 2
# cpu-map auto:1/1-2 0-1
nbproc 1
nbthread 2
cpu-map 1 0
cpu-map 2 1
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn 99999
defaults
log global
mode tcp
2. Configure separate haproxy Frontend logging via local5 inside haproxy.cfg
As a minimum you need a configuration for frontend like:
frontend http-in
mode tcp
option tcplog
log /dev/log local5 debug
…..
….
…
..
.
Of course the mode tcp in my case is conditional you might be using mode http etc.
3. Optionally but (preferrably) make local5 / local6 handlers to work via rsyslogs UDP imudp protocol
In this example /dev/log is straightly read by haproxy instead of sending the messages first to rsyslog, this is a good thing in case if you have doubts that rsyslog might stop working and respectively you might end up with no logging, however if you prefer to use instead rsyslog which most of people usually do you will have instead for /etc/haproxy/haproxy.cfg to use config:
global
log 127.0.0.1 local6 debug
defaults
log global
mode tcp
And for /etc/haproxy_customname_prod.cfg config like:
global
log 127.0.0.1 local5 debug
defaults
log global
mode tcp
If you're about to send the haproxy logs directly via rsyslog, it should have enabled in /etc/rsyslog.conf the imudp module if you're not going to use directly /dev/log
# provides UDP syslog reception
module(load="imudp")
input(type="imudp" port="514")
4. Prepare first and second log file and custom frontend output file and set right permissions
Assumably you already have /var/log/haproxy.log and this will be the initial haproxy log if you don't want to change it, normally it is installed on haproxy package install time on Linux and should have some permissions like following:
root@haproxy2:/etc/rsyslog.d# ls -al /var/log/haproxy.log
-rw-r–r– 1 haproxy haproxy 6681522 1 сеп 16:05 /var/log/haproxy.log
To create the second config with exact permissions like haproxy.log run:
root@haproxy2:/etc/rsyslog.d# touch /var/log/haproxy_customname.log
root@haproxy2:/etc/rsyslog.d# chown haproxy:haproxy /var/log/haproxy_customname.log
Create the haproxy_custom_frontend.log file that will only log output of exact frontend or match string from the logs
root@haproxy2:/etc/rsyslog.d# touch /var/log/haproxy_custom_frontend.log
root@haproxy2:/etc/rsyslog.d# chown haproxy:haproxy /var/log/haproxy_custom_frontend.log
5. Create the rsyslog config for haproxy.service to log via local6 to /var/log/haproxy.log
root@haproxy2:/etc/rsyslog.d# cat 49-haproxy.conf
# Create an additional socket in haproxy's chroot in order to allow logging via
# /dev/log to chroot'ed HAProxy processes
$AddUnixListenSocket /var/lib/haproxy/dev/log
# Send HAProxy messages to a dedicated logfile
:programname, startswith, "haproxy" {
/var/log/haproxy.log
stop
}
Above configs will make anything returned with string haproxy (e.g. proccess /usr/sbin/haproxy) to /dev/log to be written inside /var/log/haproxy.log and trigger a stop (by the way the the stop command works exactly as the tilda '~' discard one, except in some newer versions of haproxy the ~ is no now obsolete and you need to use stop instead (bear in mind that ~ even though obsolete proved to be working for me whether stop not ! but come on this is no strange this is linux mess), for example if you run latest debian Linux 11 as of September 2022 haproxy with package 2.2.9-2+deb11u3.
6. Create configuration for rsyslog to log from single Frontend outputting local2 to /var/log/haproxy_customname.log
root@haproxy2:/etc/rsyslog.d# cat 48-haproxy.conf
# Create an additional socket in haproxy's chroot in order to allow logging via
# /dev/log to chroot'ed HAProxy processes
$AddUnixListenSocket /var/lib/haproxy/dev/log
# Send HAProxy messages to a dedicated logfile
#:programname, startswith, "haproxy" {
# /var/log/haproxy.log
# stop
#}
# GGE/DPA 2022/08/02: HAProxy logs to local2, save the messages
local5.* /var/log/haproxy_customname.log
You might also explicitly define the binary that will providing the logs inside the 48-haproxy.conf as we have a separate /usr/sbin/haproxy-customname-wrapper in that way you can log the output from the haproxy instance only based
on its binary command and you can omit writting to local5 to log via it something else 🙂
root@haproxy2:/etc/rsyslog.d# cat 48-haproxy.conf
# Create an additional socket in haproxy's chroot in order to allow logging via
# /dev/log to chroot'ed HAProxy processes
$AddUnixListenSocket /var/lib/haproxy/dev/log
# Send HAProxy messages to a dedicated logfile
#:programname, startswith, "haproxy" {
# /var/log/haproxy.log
# stop
#}
# GGE/DPA 2022/08/02: HAProxy logs to local2, save the messages
:programname, startswith, "haproxy-customname-wrapper " {
/var/log/haproxy_customname.log
stop
}
7. Create the log file to log the custom frontend of your preference e.g. /var/log/haproxy_custom_frontend.log under local5 /prepare rsyslog config for
root@haproxy2:/etc/rsyslog.d# cat 47-haproxy-custom-frontend.conf
$ModLoad imudp
$UDPServerAddress 127.0.0.1
$UDPServerRun 514
#2022/02/02: HAProxy logs to local6, save the messages
local4.* /var/log/haproxy_custom_frontend.log
:msg, contains, "https-in" ~
The 'https-in' is my frontend inside /etc/haproxy/haproxy.cfg it returns the name of it every time in /var/log/haproxy.log therefore I will log the frontend to local5 and to prevent double logging inside /var/log/haproxy.log of connections incoming towards the same frontend inside /var/log/haproxy.log, I have the tilda symbol '~' which instructs rsyslog to discard any message coming to rsyslog with "https-in" string in, immediately after the same frontend as configured inside /etc/haproxy/haproxy.cfg will output the frontend operations inside local5.
!!! Note that for rsyslog it is very important to have the right order of configurations, the configuration order is being considered based on the file numbering. !!!
Hence notice that my filter file number 47_* preceeds the other 2 configured rsyslog configs.
root@haproxy2:/etc/rsyslog.d# ls -1
47-haproxy-custom-frontend.conf
48-haproxy.conf
49-haproxy.conf
This will make 47-haproxy-custom-frontend.conf to be read and processed first 48-haproxy.conf processed second and 49-haproxy.conf processed third.
8. Reload rsyslog and haproxy and test
root@haproxy2: ~# systemctl restart rsyslog
root@haproxy2: ~# systemctl restart haproxy
root@haproxy2: ~# systemctl status rsyslog
● rsyslog.service – System Logging Service
Loaded: loaded (/lib/systemd/system/rsyslog.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2022-09-01 17:34:51 EEST; 1s ago
TriggeredBy: ● syslog.socket
Docs: man:rsyslogd(8)
man:rsyslog.conf(5)
https://www.rsyslog.com/doc/
Main PID: 372726 (rsyslogd)
Tasks: 6 (limit: 4654)
Memory: 980.0K
CPU: 8ms
CGroup: /system.slice/rsyslog.service
└─372726 /usr/sbin/rsyslogd -n -iNONE
сеп 01 17:34:51 haproxy2 systemd[1]: Stopped System Logging Service.
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: warning: ~ action is deprecated, consider using the 'stop' statement instead [v8.210>
сеп 01 17:34:51 haproxy2 systemd[1]: Starting System Logging Service…
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: [198B blob data]
сеп 01 17:34:51 haproxy2 systemd[1]: Started System Logging Service.
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: [198B blob data]
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: [198B blob data]
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: [198B blob data]
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: imuxsock: Acquired UNIX socket '/run/systemd/journal/syslog' (fd 3) from systemd. [>
сеп 01 17:34:51 haproxy2 rsyslogd[372726]: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="372726" x-info="https://www.
Do some testing with some tool like curl / wget / lynx / elinks etc. on each of the configured haproxy listeners and frontends and check whether everything ends up in the correct log files.
That's all folks enjoy ! 🙂