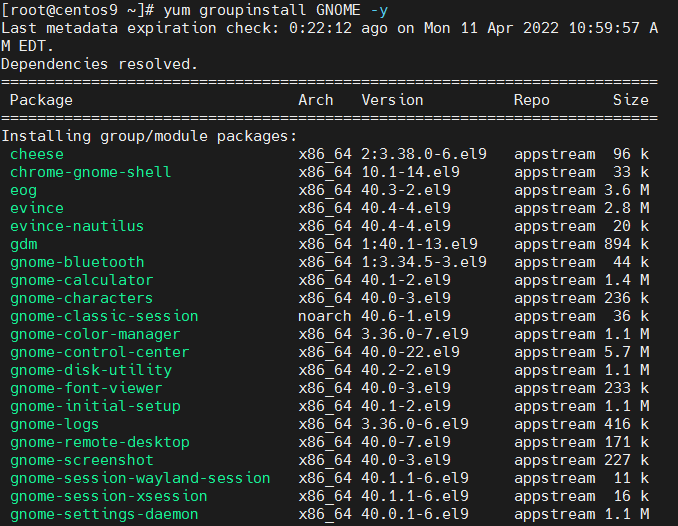
Installing sendmail on Debian Linux is something not so common these days. As sendmail has been overshadowed by his competitors Exim and Postfix. By default Debian Linux comes with Exim (light) installed as Exim is tiny and perfectly suitable for dealing with small and mid-sized SMTP needs. The reason why sendmail has been moved out by its competitors over the last 15 years is sendmail configuration is one big hell and besides that sendmail has been well known for its many security remote exploit holes – making it a famous target for crackers. Well anyways in some cases sendmail is necessary to install especially if you have a client which wants to have it set up. In this short article I will show how very basic sendmail installation on Debian host is done.
blackstar:~# apt-get install sendmail-bin sensible-mda
Reading package lists… Done
Building dependency tree
Reading state information… Done
The following extra packages will be installed:
sendmail-base sendmail-cf sensible-mda
Suggested packages:
sendmail-doc logcheck resolvconf sasl2-bin
The following packages will be REMOVED:
exim4 exim4-base exim4-config exim4-daemon-light sa-exim task-mail-server
The following NEW packages will be installed:
sendmail-base sendmail-bin sendmail-cf
0 upgraded, 3 newly installed, 6 to remove and 26 not upgraded.
Need to get 1,626 kB of archives.
After this operation, 592 kB disk space will be freed.
Do you want to continue [Y/n]? Y
Get:1 http://ftp.bg.debian.org/debian/ wheezy/main sendmail-base all 8.14.4-2.1 [362 kB]
Get:2 http://ftp.bg.debian.org/debian/ wheezy/main sendmail-cf all 8.14.4-2.1 [300 kB]
Get:3 http://ftp.bg.debian.org/debian/ wheezy/main sendmail-bin i386 8.14.4-2.1 [964 kB]
Fetched 1,626 kB in 0s (3,057 kB/s)
(Reading database … 199577 files and directories currently installed.)
Removing task-mail-server …
Selecting previously unselected package sendmail-base.
(Reading database … 199577 files and directories currently installed.)
Unpacking sendmail-base (from …/sendmail-base_8.14.4-2.1_all.deb) …
Selecting previously unselected package sendmail-cf.
Unpacking sendmail-cf (from …/sendmail-cf_8.14.4-2.1_all.deb) …
Processing triggers for man-db …
(Reading database … 199939 files and directories currently installed.)
Removing sa-exim …
[….] Reloading exim4 configuration files:invoke-rc.d: initscript exim4, action "reload" failed.
dpkg: exim4-config: dependency problems, but removing anyway as you requested:
exim4-base depends on exim4-config (>= 4.30) | exim4-config-2; however:
Package exim4-config is to be removed.
Package exim4-config-2 is not installed.
Package exim4-config which provides exim4-config-2 is to be removed.
exim4-base depends on exim4-config (>= 4.30) | exim4-config-2; however:
Package exim4-config is to be removed.
Package exim4-config-2 is not installed.
Package exim4-config which provides exim4-config-2 is to be removed.
Removing exim4-config …
dpkg: exim4-daemon-light: dependency problems, but removing anyway as you requested:
exim4 depends on exim4-daemon-light | exim4-daemon-heavy | exim4-daemon-custom; however:
Package exim4-daemon-light is to be removed.
Package exim4-daemon-heavy is not installed.
Package exim4-daemon-custom is not installed.
bsd-mailx depends on default-mta | mail-transport-agent; however:
Package default-mta is not installed.
Package exim4-daemon-light which provides default-mta is to be removed.
Package mail-transport-agent is not installed.
Package exim4-daemon-light which provides mail-transport-agent is to be removed.
bsd-mailx depends on default-mta | mail-transport-agent; however:
Package default-mta is not installed.
Package exim4-daemon-light which provides default-mta is to be removed.
Package mail-transport-agent is not installed.
Package exim4-daemon-light which provides mail-transport-agent is to be removed.
Removing exim4-daemon-light …
[ ok ] Stopping MTA:.
ALERT: exim paniclog /var/log/exim4/paniclog has non-zero size, mail system possibly broken
dpkg: exim4-base: dependency problems, but removing anyway as you requested:
exim4 depends on exim4-base (>= 4.80).
Removing exim4-base …
Processing triggers for man-db …
Selecting previously unselected package sendmail-bin.
(Reading database … 199786 files and directories currently installed.)
Unpacking sendmail-bin (from …/sendmail-bin_8.14.4-2.1_i386.deb) …
Processing triggers for man-db …
Setting up sendmail-base (8.14.4-2.1) …
adduser: Warning: The home directory `/var/lib/sendmail' does not belong to the user you are currently creating.
Setting up sendmail-cf (8.14.4-2.1) …
Setting up sendmail-bin (8.14.4-2.1) …
update-rc.d: warning: default stop runlevel arguments (0 1 6) do not match sendmail Default-Stop values (1)
update-alternatives: using /usr/lib/sm.bin/sendmail to provide /usr/sbin/sendmail-mta (sendmail-mta) in auto mode
update-alternatives: using /usr/lib/sm.bin/sendmail to provide /usr/sbin/sendmail-msp (sendmail-msp) in auto mode
update-alternatives: warning: not replacing /usr/share/man/man8/sendmail.8.gz with a link
You are doing a new install, or have erased /etc/mail/sendmail.mc.
If you've accidentaly erased /etc/mail/sendmail.mc, check /var/backups.
I am creating a safe, default sendmail.mc for you and you can
run sendmailconfig later if you need to change the defaults.
[ ok ] Stopping Mail Transport Agent (MTA): sendmail.
Updating sendmail environment …
Validating configuration.
Writing configuration to /etc/mail/sendmail.conf.
Writing /etc/cron.d/sendmail.
Could not open /etc/mail/databases(No such file or directory), creating it.
Could not open /etc/mail/sendmail.mc(No such file or directory)
Reading configuration from /etc/mail/sendmail.conf.
Validating configuration.
Writing configuration to /etc/mail/sendmail.conf.
Writing /etc/cron.d/sendmail.
Turning off Host Status collection
Could not open /etc/mail/databases(No such file or directory), creating it.
Reading configuration from /etc/mail/sendmail.conf.
Validating configuration.
Creating /etc/mail/databases…
Checking filesystem, this may take some time – it will not hang!
… Done.
Checking for installed MDAs…
Adding link for newly extant program (mail.local)
Adding link for newly extant program (procmail)
sasl2-bin not installed, not configuring sendmail support.
To enable sendmail SASL2 support at a later date, invoke "/usr/share/sendmail/update_auth"
Creating/Updating SSL(for TLS) information
Creating /etc/mail/tls/starttls.m4…
Creating SSL certificates for sendmail.
Generating DSA parameters, 2048 bit long prime
This could take some time
…+………………..+.+..+..+++
..+.+………….+.++++++++++++++++++++++++++++++*
Generating RSA private key, 2048 bit long modulus
………………..+++
…………………+++
e is 65537 (0x10001)
*** *** *** WARNING *** WARNING *** WARNING *** WARNING *** *** ***
Everything you need to support STARTTLS (encrypted mail transmission
and user authentication via certificates) is installed and configured
but is *NOT* being used.
To enable sendmail to use STARTTLS, you need to:
1) Add this line to /etc/mail/sendmail.mc and optionally
to /etc/mail/submit.mc:
include(`/etc/mail/tls/starttls.m4')dnl
2) Run sendmailconfig
3) Restart sendmail
Updating /etc/hosts.allow, adding "sendmail: all".
Please edit /etc/hosts.allow and check the rules location to
make sure your security measures have not been overridden –
it is common to move the sendmail:all line to the *end* of
the file, so your more selective rules take precedence.
Checking {sendmail,submit}.mc and related databases…
Reading configuration from /etc/mail/sendmail.conf.
Validating configuration.
Creating /etc/mail/databases…
Reading configuration from /etc/mail/sendmail.conf.
Validating configuration.
Creating /etc/mail/databases…
Reading configuration from /etc/mail/sendmail.conf.
Validating configuration.
Creating /etc/mail/Makefile…
Reading configuration from /etc/mail/sendmail.conf.
Validating configuration.
Writing configuration to /etc/mail/sendmail.conf.
Writing /etc/cron.d/sendmail.
Disabling HOST statistics file(/var/lib/sendmail/host_status).
Creating /etc/mail/sendmail.cf…
*** ERROR: FEATURE() should be before MAILER()
*** MAILER(`local') must appear after FEATURE(`always_add_domain')*** ERROR: FEATURE() should be before MAILER()
*** MAILER(`local') must appear after FEATURE(`allmasquerade')*** ERROR: FEATURE() should be before MAILER()
Creating /etc/mail/submit.cf…
Informational: confCR_FILE file empty: /etc/mail/relay-domains
Warning: confCT_FILE source file not found: /etc/mail/trusted-users
it was created
Informational: confCT_FILE file empty: /etc/mail/trusted-users
Warning: confCW_FILE source file not found: /etc/mail/local-host-names
it was created
Warning: access_db source file not found: /etc/mail/access
it was created
Updating /etc/mail/access…
Linking /etc/aliases to /etc/mail/aliases
Updating /etc/mail/aliases…
WARNING: local host name (blackstar) is not qualified; see cf/README: WHO AM I?
/etc/mail/aliases: 13 aliases, longest 10 bytes, 145 bytes total
Warning: 3 database(s) sources
were not found, (but were created)
please investigate.
Warning: These messages were issued while creating sendmail.cf
make sure they are benign before starting sendmail!
Errors in generating sendmail.cf
*** ERROR: FEATURE() should be before MAILER()
*** MAILER(`local') must appear after FEATURE(`always_add_domain')*** ERROR: FEATURE() should be before MAILER()
*** MAILER(`local') must appear after FEATURE(`allmasquerade')*** ERROR: FEATURE() should be before MAILER()
[ ok ] Starting Mail Transport Agent (MTA): sendmail.
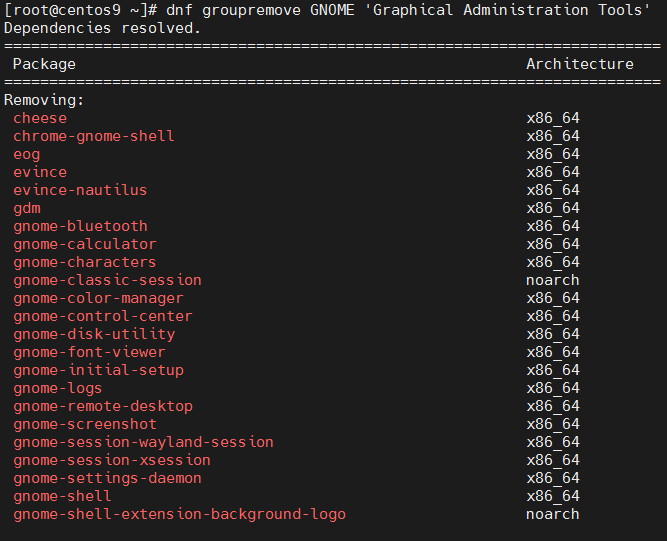
(Reading database … 199837 files and directories currently installed.)
Removing exim4 …
Right after packages gets installed it is good idea to get rid of any remains of previous exim SMTP install, run;
blackstar:~# dpkg --purge exim4
blackstar:~# dpkg --purge exim4-base
blackstar:~# dpkg --purge exim4-config
blackstar:~# dpkg --purge exim4-daemon-light
blackstar:~# dpkg --purge sa-exim
blackstar:~# grep -i sendmail /etc/passwd
smmta:x:121:128:Mail Transfer Agent,,,:/var/lib/sendmail:/bin/false
smmsp:x:124:129:Mail Submission Program,,,:/var/lib/sendmail:/bin/false
blackstar:~# grep -i -E "smmta|smmsp" /etc/passwd
smmta:x:121:128:Mail Transfer Agent,,,:/var/lib/sendmail:/bin/false
smmsp:x:124:129:Mail Submission Program,,,:/var/lib/sendmail:/bin/false
Sendmail install does create two new users smmta and smmsp in /etc/passwd and /etc/group
As you see from earlier apt-get output sendmail is provided on Debian via 4 packs:
root@blackstar:~# dpkg -l |grep -i sendmail
ii libmail-sendmail-perl 0.79.16-1 all Send email from a perl script
ii sendmail-base 8.14.4-2.1 all powerful, efficient, and scalable Mail Transport Agent
ii sendmail-bin 8.14.4-2.1 i386 powerful, efficient, and scalable Mail Transport Agent
ii sendmail-cf 8.14.4-2.1 all powerful, efficient, and scalable Mail Transport Agent
libmail-sendmail-perl installs a perl module (class) /usr/share/perl5/Mail/Sendmail.pm.
sendmail-bin contains main sendmail components binary files, cron bindings related to sendmail, some manual pages and creates structure necessary for sendmail to process email queue. sendmail-cf provides a multitude of sendmail configurations in macroses and few documentation files on the macros configuration. All sendmail configuration macros are stored in /usr/share/sendmail/* – there are pleny of .m4 configs so for people who never installed sendmail it is really confusing.
sendmail-base package contains some bindings on how to to log rotate sendmail log files, few more sendmail binaries who deal with sendmail architecture, few files whether sendmail is run via PPP or DHCP connection, some documentation and example files. Sendmail documentation is installed in /usr/share/doc/sendmail*, unfortunately documentation there is scarce so for extended documentation it is good to check Sendmail's Official site
To check if sendmail is running you should have it visible in the list of running processes;
root@blackstar:~# ps xa|grep sendmail|grep -v grep
468 ? Ss 0:00 sendmail: MTA: accepting connections
Further on it should be accepting connections on localhost / 25, i.e.
root@blackstar:~# telnet localhost 25
Trying ::1...
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
220 blackstar ESMTP Sendmail 8.14.4/8.14.4/Debian-2.1; Sat, 30 Mar 2013 19:09:47 +0200; (No UCE/UBE) logging access from: localhost(OK)-localhost [127.0.0.1] ^]
telnet> quit
Sendmail's configuration is being generated using a macro file using a macro processor via m4 command. There are few files, used as a basis for generation the final m4 most important of course is /etc/mail/sendmail.mc and sendmail.cf – /etc/mail/sendmail.cf, sendmail.mc after processed with the mambo-jambo with m4 generates the complex and about 15 times larger by size sendmail.cf.
All configs related to generating files instructing how sendmail will operate are stored in /etc/mail;
blackstar:~# ls -1
access
access.db
address.resolve
aliases
aliases.db
databases
helpfile
local-host-names
m4
Makefile
peers
sasl
sendmail.cf
sendmail.cf.errors
sendmail.conf
sendmail.mc
service.switch
service.switch-nodns
smrsh
spamassassin
submit.cf
submit.mc
tls
sendmail.cf.errors – contains errors during processing of macros config files.
root@blackstar:/etc/mail# cat sendmail.cf.errors
*** ERROR: FEATURE() should be before MAILER()
*** MAILER(`local') must appear after FEATURE(`always_add_domain')*** ERROR: FEATURE() should be before MAILER()
*** MAILER(`local') must appear after FEATURE(`allmasquerade')*** ERROR: FEATURE() should be before MAILER()
This errors, are not fatal as sendmail.cf is there and sendmail is from now on ready to send mails via localhost.
To check if sendmail delivers mails onwards, use mail cmd;
hipo@blackstar:~$ mail -s "testing" test@www.pc-freak.net
this is a simple test email
Do you get it?
.
Cc:
To see all is fine with mail delivery check out /var/log/mail.log
blackstar:~# tail -f /var/log/mail/log
Mar 30 21:23:05 blackstar sm-msp-queue[1495]: unable to qualify my own domain name (blackstar) -- using short name
Mar 30 21:23:09 blackstar sm-mta[1499]: STARTTLS=client, relay=mail.www.pc-freak.net., version=TLSv1/SSLv3, verify=FAIL, cipher=AES256-SHA, bits=256/256
Mar 30 21:23:11 blackstar sm-mta[1524]: r2UJN8x2001524: localhost [127.0.0.1] did not issue MAIL/EXPN/VRFY/ETRN during connection to MTA-v4
Mar 30 21:23:13 blackstar sm-mta[1499]: r2UJKwqR001412: to=<hipo@www.pc-freak.net>, ctladdr=<root@blackstar> (0/0), delay=00:02:15, xdelay=00:00:10, mailer=esmtp, pri=210313, relay=mail.www.pc-freak.net. [83.228.93.76], dsn=2.0.0, stat=Sent (ok 1364671405 qp 7492)
Mar 30 21:24:28 blackstar sendmail[1532]: My unqualified host name (blackstar) unknown; sleeping for retry
Mar 30 21:27:16 blackstar sendmail[1633]: My unqualified host name (blackstar) unknown; sleeping for retry
As you see there is an error in mail.log
blackstar sendmail[1532]: My unqualified host name (blackstar) unknown; sleeping for retry
This is because blackstar is not assigned as a a host recognized to 127.0.0.1 in /etc/hosts. To solve it on my host I had to change /etc/hosts which looked like so:
blackstar:~# cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 blackstar
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
to
blackstar:~# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain blackstar
127.0.1.1 blackstar
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
Then restart sendmail to reread /etc/hosts
root@blackstar:/etc/mail# /etc/init.d/sendmail restart
[ ok ] Restarting Mail Transport Agent (MTA): sendmail.