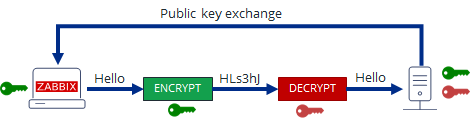
If you're a Desktop Linux or BSD UNIX user and your hard disk / external SSD / flash drive etc. space starts to be misteriously disapper due to whatever reaseon such as a crashing applications producing rapidly log error / warning messages leading quickly to filling up the disk or out of a sudden you have some Disk space lost without knowing what kind of data filled up the disk or you're downloading some big sized bittorrent files forgotten in your bittorrent client or complete mirroring a large website and you suddenly get the result of root directory ( / ) getting fully or nearly filled up, then you definitely would want to check out what has disk activity has eaten up your disk space and leaing to OS and Aplication slow responsiveness.
For the Linux regular *nix user finding out what is filling the disk is a trivial task with with find / du -hsc * but as people have different habits to use find and du I'll show you the most common ways I use this two command line tools to identify disk space low issues for the sake of comparison.
Others who have better easier ways to do it are very welcome to share it with me in the comments.
1. Finding large files on hard disk with find Linux command tool
host:~# find /home -type f -printf "%s\t%p\n" | sort -n | tail -10
2100000000 /home/hipo/Downloads/MameUIfx incl. ROMs/MameUIfx incl. ROMs-6.bin
2100000000 /home/hipo/Downloads/MameUIfx incl. ROMs/MameUIfx incl. ROMs-7.bin
2100000000 /home/hipo/Downloads/MameUIfx incl. ROMs/MameUIfx incl. ROMs-8.bin
2100000000 /home/hipo/Downloads/MameUIfx incl. ROMs/MameUIfx incl. ROMs-9.bin
2815424080 /home/hipo/.thunderbird/h3dasfii.default\
/ImapMail/imap.gmail.com/INBOX
2925584895 /home/hipo/Documents/.git/\
objects/pack/pack-8590b069cad26ac0af7560fb42b51fa9bfe41050.pack
4336918067 /home/hipo/Games/Mames_4GB-compilation-best-arcade-games-of-your-14_04_2021.tar.gz
6109003776 /home/hipo/VirtualBox VMs/CentOS/CentOS.vdi
23599251456 /home/hipo/VirtualBox VMs/Windows 7/Windows 7.vdi
33913044992 /home/hipo/VirtualBox VMs/Windows 10/Windows 10.vdi
I use less rarely find on Desktops and more when I have to do some kind of data usage analysis on servers, of course for my Linux home computer and any other Linux desktop machines, or just a small incomprehensive analysis du cmd is much more appropriate to use.
2. Finding large files Megabyte occupying space files sorted in Megabytes and Gigas with du
-
Check main 10 files sorted in megabytes that are hanging in a directory
pcfkreak:~# du -hsc /home/hipo/*|grep 'M\s'|sort -rn|head -n 10
956M /home/hipo/last_dump1.sql
711M /home/hipo/hipod
571M /home/hipo/from-thinkpad_r61
453M /home/hipo/ultimate-edition-themes
432M /home/hipo/metasploit-framework
355M /home/hipo/output-upgrade.txt
333M /home/hipo/Плот
209M /home/hipo/Work-New.tar.gz
98M /home/hipo/DOOM64
90M /home/hipo/mp3
-
Get 10 top larges files in Gigabytes that are space hungry and eating up your space
pcfkreak:~# du -hsc /home/hipo/*|grep 'G\s'|sort -rn|head -n 10
156G total
60G /home/hipo/VirtualBox VMs
37G /home/hipo/Downloads
18G /home/hipo/Desktop
11G /home/hipo/Games
7.4G /home/hipo/ownCloud
7.1G /home/hipo/Документи
4.6G /home/hipo/music
2.9G /home/hipo/root
2.8G /home/hipo/Documents
If you want to still work on the console terminal but you don't want to type too much you can use ncdu (ncurses) text tool, install it with
# apt install –yes ncdu
For the most lazy ones or complete Linux newbies that doesn't want to spend time typing / learing or using text commands or softwares you can also check what has eaten up your full disk space with GUI tools as well.
There are at least 3 tools to use to check in Graphical Interface what has occupied your disk space on Linux / BSD, I'm aware of:
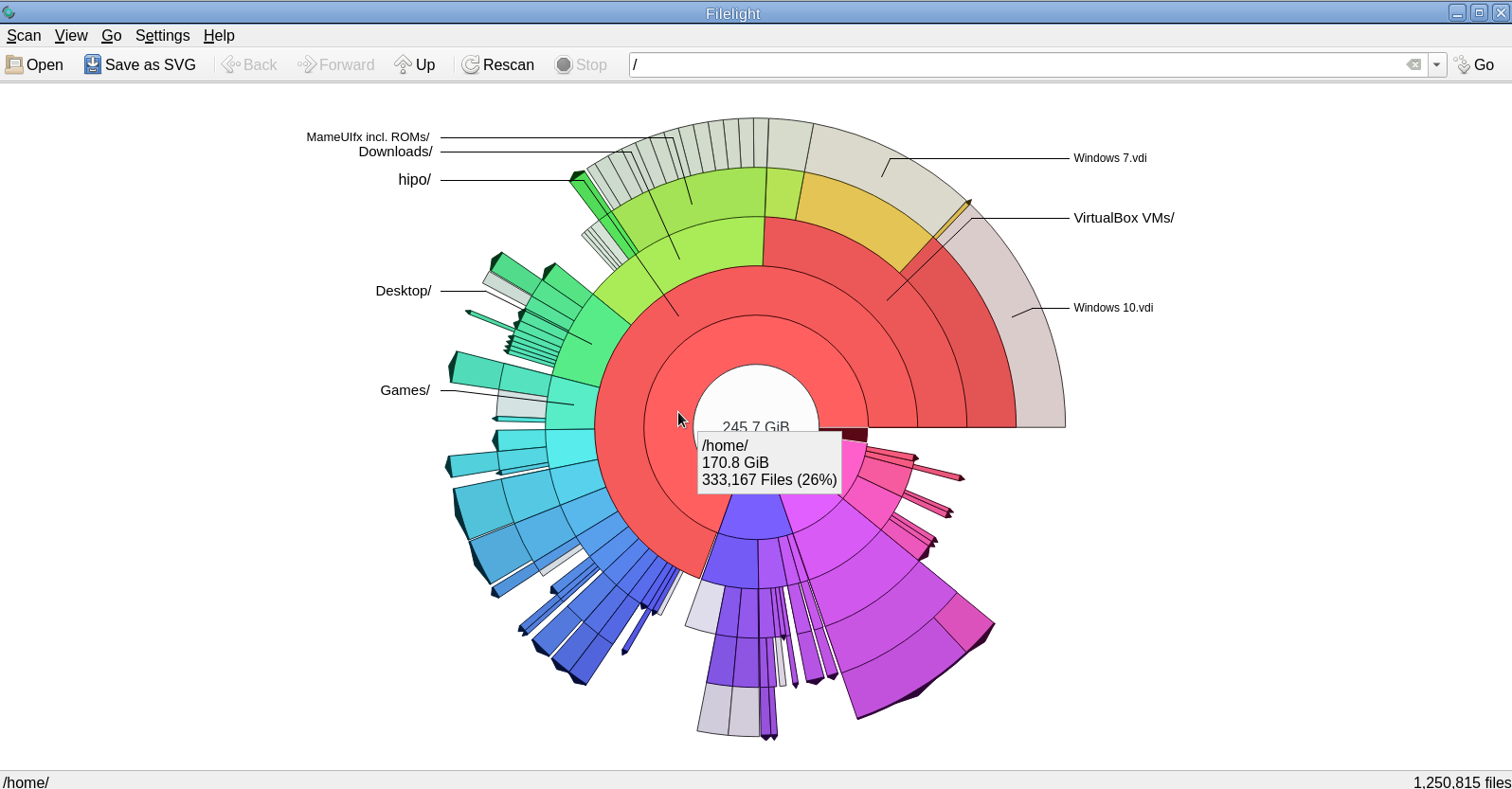
3. Filelight GUI disk usage analysis Linux tool
For those using KDE or preferring a shiny GUI interface that will capture the eye, perhaps filelight would be the option of choice tool to get analysis sum of your directory sturctures and file use on the laptop or desktop *unix OS.
unix-desktop:~# apt-cache show filelight|grep -i description-en -A 7
Description-en: show where your diskspace is being used
Filelight allows you to understand your disk usage by graphically
representing your filesystem as a set of concentric, segmented rings.
.
It is like a pie-chart, but the segments nest, allowing you to see both
which directories take up all your space, and which directories
and files inside those directories are the real culprits.
Description-md5: 397ff9a469e07a772f22460c66b66875
To use it simply go ahead and install it with apt or yum / dnf or whatever Linux package manager your distro uses:
unix-desktop:~# apt-get install –yes filelight
…
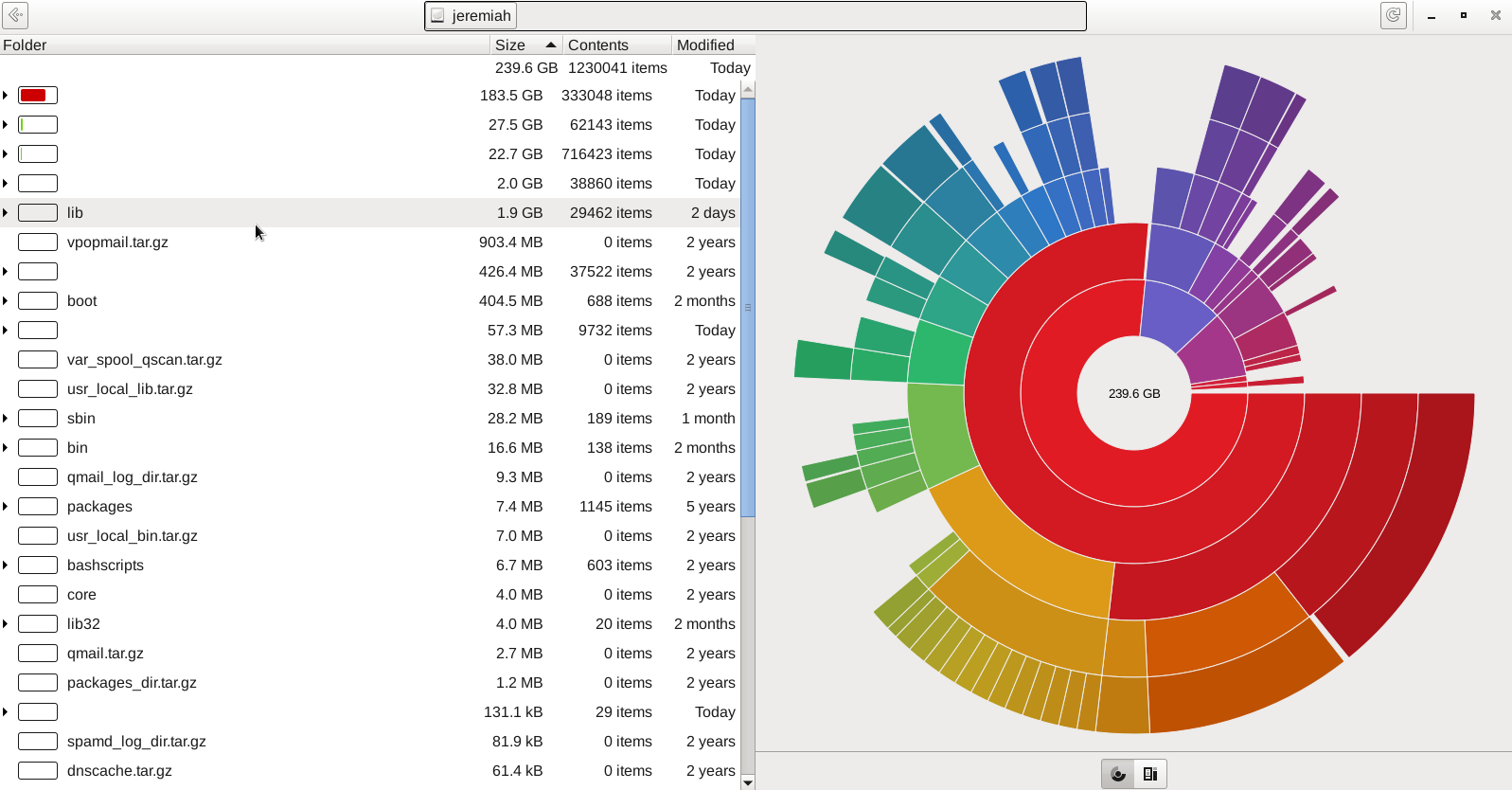
4. GNOME DIsk Usage Analyzer Baobab GUI tool
For those being a GNOME / Mate / Budgie / Cinnamon Graphical interface users baobab shold be the program to use as it uses the famous LibGD library.
unix-desktop:~# apt-cache show baobab|grep -i description-en -A10
Description-en: GNOME disk usage analyzer
Disk Usage Analyzer is a graphical, menu-driven application to analyse
disk usage in a GNOME environment. It can easily scan either the whole
filesystem tree, or a specific user-requested directory branch (local or
remote).
.
It also auto-detects in real-time any changes made to your home
directory as far as any mounted/unmounted device. Disk Usage Analyzer
also provides a full graphical treemap window for each selected folder.
Description-md5: 5f6072b89ebb1dc83433fa7658814dc6
Homepage: https://wiki.gnome.org/Apps/Baobab
5. Qdirstat graphical application to show where your disk space has gone on Linux
Qdirstat is perhaps well known tool to track disk space issues on Linux desktop hosts, known by the hardcore KDE / LXDE / LXQT / DDE GUI interface / environment lovers and as a KDE tool uses the infamous Qt library. I personally don't like it and don't put it on machines I use because I never use kde and don't want to waste my disk space with additional libraries such as the QT Library which historically was not totally free in terms of licensing and even now is in both free and non free licensing GPL / LGPL and QT Commercial Licensing license.
unix-desktop:~# apt-cache show qdirstat|grep -i description-en -A10
Description-en: Qt-based directory statistics
QDirStat is a graphical application to show where your disk space has gone and
to help you to clean it up.
.
QDirStat has a number of new features compared to KDirStat. To name a few:
* Multi-selection in both the tree and the treemap.
* Unlimited number of user-defined cleanup actions.
* Properly show errors of cleanup actions (and their output, if desired).
* File categories (MIME types) and their treemap color are now configurable.
* Exclude rules for directories are easily configurable.
* Desktop-agnostic; no longer relies on KDE or any other specific desktop.
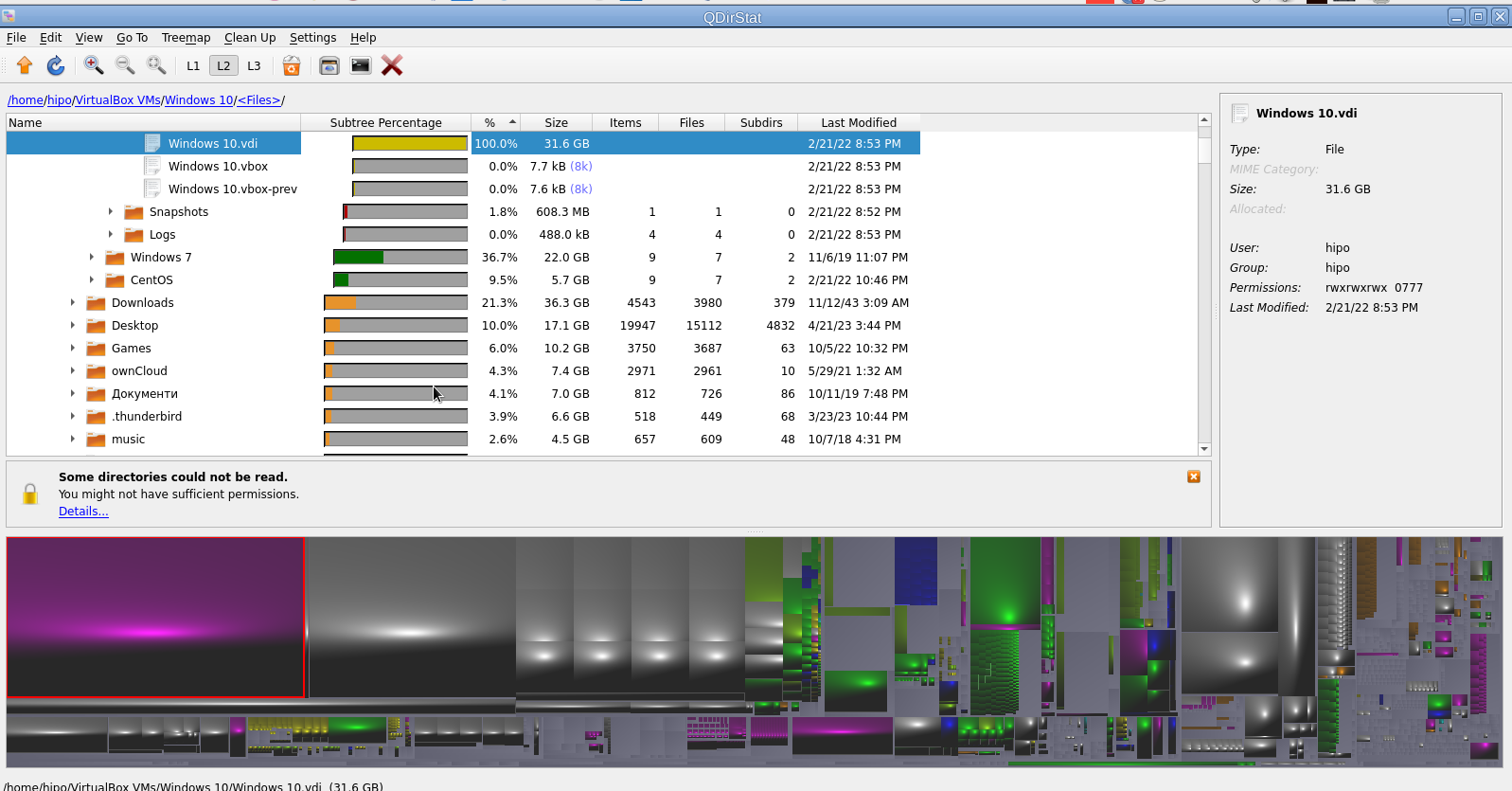
That shiny fuzed graphics is actually a repsesantation of all directories the bigger and if one scrolls on the colorful gamma a text with directory and size or file will appear. Though the graphical represantation is really c00l to me it is a bit unreadable, thus I prefer and recommend the other two GUI tools filelight or baobab instead.
6. Finding duplicate files on Linux system with duff command tool
Talking about big unknown left-over files on your hard drives, it is appropriate to mention one tool here that is a console one but very useful to anyone willing to get rid of old duplicate files that are hanging around on the disk. Sometimes such copies are produced while copying large amount of files from place to place or simply by mistake while copying Photo / Video files from your Smart Phone to Linux desktop etc.
This is where the duff command line utility might be super beneficial for you.
unix-desktop:~# apt-cache show duff|grep -i description-en -A3
Description-en: Duplicate file finder
Duff is a command-line utility for identifying duplicates in a given set of
files. It attempts to be usably fast and uses the SHA family of message
digests as a part of the comparisons.
Using duff tool is very straight forward to see all the duplicate files hanging in a directory lets say your home folder.
unix-desktop:~# duff -rP /home/hipo
…/home/hipo/music/var/Quake II Soundtrack – Kill Ratio.mp3
/home/hipo/mp3/Quake II Soundtrack – Kill Ratio.mp3
2 files in cluster 44 (7913472 bytes, digest 98f38be49e2ffcbf90927f9357b3e24a81d5a649)
/home/hipo/music/var/HYPODIL_01-Scakauec.mp3
/home/hipo/mp3/HYPODIL_01-Scakauec.mp3
2 files in cluster 45 (2807808 bytes, digest ce9067ce1f132fc096a5044845c7fac73e99c0ed)
/home/hipo/music/var/Quake II Suondtrack – March Of The Stoggs.mp3
/home/hipo/mp3/Quake II Suondtrack – March Of The Stoggs.mp3
2 files in cluster 46 (3506176 bytes, digest efcc401b4ebda9b0b2367aceb8e334c8ba1a357d)
/home/hipo/music/var/Quake II Suondtrack – Quad Machine.mp3
/home/hipo/mp3/Quake II Suondtrack – Quad Machine.mp3
2 files in cluster 47 (7917568 bytes, digest 0905c1d790654016c2ecf2949f78d47a870c3822)
/home/hipo/music/var/Cyberpunk Group – Futureshock!.mp3
/home/hipo/mp3/Cyberpunk Group – Futureshock!.mp3
-r (Recursively search into all specified directories.)
–P (Don't follow any symbolic links. This overrides any previous -H or -L option. This is the default. Note that this only applies to directories, as sym‐
bolic links to files are never followed.)
7. Deleting duplicate files with duff
If you're absolutely sure you know what you're doing and you have a backup in case if something messes up during duplicate teletions, to get rid of lets say any duplicate Picture files found by duff run sommething like:
# duff -e0 -r /home/hipo/Pictures/ | xargs -0 rm
!!! Please note that using duff is for those who absolutely know what they're doing and have their data recent data. Deleting the wrong data by mistake with the tool might put you in the first grade and you'll be the only one to blame 🙂 !!!
Wrap it Up
Filling up the disk with unknown large files is a task to resolve that happens often. For the unlazy on Linux / BSD / Mac OS and other UNIX like OS-es the easiest way is to use find or du with some one liner command. For the lazy Windows addicted Graphical users filelight, qdirstat or baobab GUI disk usage analysis tools are there.
If you have a lot of files and many of thems are duplicates you can use duff to check them out and remove all unneded duplicates and save space.
Hope this article, was helpful for someone.
That's all folks, enjoy your data profilactics, if you know any other good easy command or GUI tools or hints for drive disk space profilactics please share.