
Generally upgrading both RHEL and CentOS can be done straight with yum tool just we're pretty aware and mostly anyone could do the update, but it is good idea to do some
steps in advance to make backup of any old basic files that might help us to debug what is wrong in case if the Operating System fails to boot after the routine Machine OS restart
after the upgrade that is usually a good idea to make sure that machine is still bootable after the upgrade.
This procedure can be shortened or maybe extended depending on the needs of the custom case but the general framework should be useful anyways to someone that's why
I decided to post this.
Before you go lets prepare a small status script which we'll use to report status of sysctl installed and enabled services as well as the netstat connections state and
configured IP addresses and routing on the system.
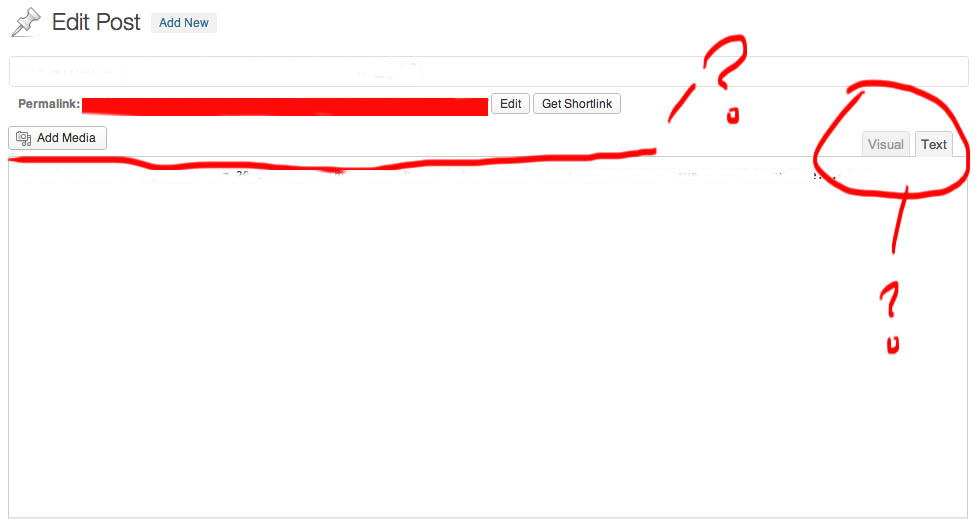
The script show_running_services_netstat_ips_route.sh to be used during our different upgrade stages:
# script status ###
echo "STARTED: $(date '+%Y-%m-%d_%H-%M-%S'):" | tee /root/logs/yumcheckupdate-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
systemctl list-unit-files –type=service | grep enabled
systemctl | grep ".service" | grep "running"
netstat -tulpn
netstat -r
ip a s
/sbin/route -n
echo "ENDED $(date '+%Y-%m-%d_%H-%M-%S'):" | tee /root/logs/yumcheckupdate-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
####
– Save the script in any file like /root/status.sh
– Make the /root/logs directoriy.
[root@redhat: ~ ]# mkdir /root/logs
[root@redhat: ~ ]# vim /root/status.sh
[root@redhat: ~ ]# chmod +x /root/status.sh
1. Get a dump of CentOS installed version release and grub-mkconfig generated os_probe
[root@redhat: ~ ]# cat /etc/redhat-release > /root/logs/redhat-release-vorher-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
[root@redhat: ~ ]# cat /etc/grub.d/30_os-prober > /root/logs/grub2-efi-vorher-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
2. Clear old versionlock marked RPM packages (if there are such)
On servers maintained by multitude of system administrators just like the case is inside a Global Corporations and generally in the corporate world , where people do access the systems via LDAP and more than a single person
has superuser privileges. It is a good prevention measure to use yum package management functionality to RPM based Linux distributions called versionlock.
versionlock for those who hear it for a first time is locking the versions of the installed RPM packages so if someone by mistake or on purpose decides to do something like :
[root@redhat: ~ ]# yum install packageversion
Having the versionlock set will prevent the updated package to be installed with a different branch package version.
Also it will prevent a playful unknowing person who just wants to upgrade the system without any deep knowledge to be able to
run
[root@redhat: ~ ]# yum upgrade
update and leave the system in unbootable state, that will be only revealed during the next system reboot.
If you haven't used versionlock before and you want to use it you can do it with:
[root@redhat: ~ ]# yum install yum-plugin-versionlock
To add all the packages for compiling C code and all the interdependend packages, you can do something like:
[root@redhat: ~ ]# yum versionlock gcc-*
If you want to clear up the versionlock, once it is in use run:
[root@redhat: ~ ]# yum versionlock clear
[root@redhat: ~ ]# yum versionlock list
3. Check RPC enabled / disabled
This step is not necessery but it is a good idea to check whether it running on the system, because sometimes after upgrade rpcbind gets automatically started after package upgrade and reboot.
If we find it running we'll need to stop and mask the service.
# check if rpc enabled
[root@redhat: ~ ]# systemctl list-unit-files|grep -i rpc
var-lib-nfs-rpc_pipefs.mount static
auth-rpcgss-module.service static
rpc-gssd.service static
rpc-rquotad.service disabled
rpc-statd-notify.service static
rpc-statd.service static
rpcbind.service disabled
rpcgssd.service static
rpcidmapd.service static
rpcbind.socket disabled
rpc_pipefs.target static
rpcbind.target static
[root@redhat: ~ ]# systemctl status rpcbind.service
● rpcbind.service – RPC bind service
Loaded: loaded (/usr/lib/systemd/system/rpcbind.service; disabled; vendor preset: enabled)
Active: inactive (dead)
[root@redhat: ~ ]# systemctl status rpcbind.socket
● rpcbind.socket – RPCbind Server Activation Socket
Loaded: loaded (/usr/lib/systemd/system/rpcbind.socket; disabled; vendor preset: enabled)
Active: inactive (dead)
Listen: /var/run/rpcbind.sock (Stream)
0.0.0.0:111 (Stream)
0.0.0.0:111 (Datagram)
[::]:111 (Stream)
[::]:111 (Datagram)
4. Check any previously existing downloaded / installed RPMs (check yum cache)
yum install package-name / yum upgrade keeps downloaded packages via its operations inside its cache directory structures in /var/cache/yum/*.
Hence it is good idea to check what were the previously installed packages and their count.
[root@redhat: ~ ]# cd /var/cache/yum/x86_64/;
[root@redhat: ~ ]# find . -iname '*.rpm'|wc -l
5. List RPM repositories set on the server
[root@redhat: ~ ]# yum repolist
Loaded plugins: fastestmirror, versionlock
Repodata is over 2 weeks old. Install yum-cron? Or run: yum makecache fast
Determining fastest mirrors
repo id repo name status
!atos-ac/7/x86_64 Atos Repository 3,128
!base/7/x86_64 CentOS-7 – Base 10,019
!cr/7/x86_64 CentOS-7 – CR 2,686
!epel/x86_64 Extra Packages for Enterprise Linux 7 – x86_64 165
!extras/7/x86_64 CentOS-7 – Extras 435
!updates/7/x86_64 CentOS-7 – Updates 2,500
This step is mandatory to make sure you're upgrading to latest packages from the right repositories for more concretics check what is inside in confs /etc/yum.repos.d/ , /etc/yum.conf
6. Clean up any old rpm yum cache packages
This step is again mandatory but a good to follow just to have some more clearness on what packages is our upgrade downloading (not to mix up the old upgrades / installs with our newest one).
For documentation purposes all deleted packages list if such is to be kept under /root/logs/yumclean-install*.out file
[root@redhat: ~ ]# yum clean all |tee /root/logs/yumcleanall-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
7. List the upgradeable packages's latest repository provided versions
[root@redhat: ~ ]# yum check-update |tee /root/logs/yumcheckupdate-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
Then to be aware how many packages we'll be updating:
[root@redhat: ~ ]# yum check-update | wc -l
8. Apply the actual uplisted RPM packages to be upgraded
[root@redhat: ~ ]# yum update |tee /root/logs/yumupdate-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
Again output is logged to /root/logs/yumcheckupate-*.out
9. Monitor downloaded packages count real time
To make sure yum upgrade is not in some hanging state and just get some general idea in which state of the upgrade is it e.g. Download / Pre-Update / Install / Upgrade/ Post-Update etc.
in mean time when yum upgrade is running to monitor, how many packages has the yum upgrade downloaded from remote RPM set repositories:
[root@redhat: ~ ]# watch "ls -al /var/cache/yum/x86_64/7Server/…OS-repository…/packages/|wc -l"
10. Run status script to get the status again
[root@redhat: ~ ]# sh /root/status.sh |tee /root/logs/status-before-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
11. Add back versionlock for all RPM packs
Set all RPM packages installed on the RHEL / CentOS versionlock for all packages.
#==if needed
# yum versionlock \*
12. Get whether old software configuration is not messed up during the Package upgrade (Lookup the logs for .rpmsave and .rpmnew)
During the upgrade old RPM configuration is probably changed and yum did automatically save .rpmsave / .rpmnew saves of it thus it is a good idea to grep the prepared logs for any matches of this 2 strings :
[root@redhat: ~ ]# grep -i ".rpm" /root/logs/yumupdate-server-host-2020-01-20_14-30-41.out
[root@redhat: ~ ]# grep -i ".rpmsave" /root/logs/yumupdate-server-host-2020-01-20_14-30-41.out
[root@redhat: ~ ]# grep -i ".rpmnew" /root/logs/yumupdate-server-host-2020-01-20_14-30-41.out
If above commands returns output usually it is fine if there is is .rpmnew output but, if you get grep output of .rpmsave it is a good idea to review the files compare with the original files that were .rpmsaved with the
substituted config file and atune the differences with the changes manually made for some program functionality.
What are the .rpmsave / .rpmnew files ?
This files are coded files that got triggered by the RPM install / upgrade due to prewritten procedures on time of RPM build.
If a file was installed as part of a rpm, it is a config file (i.e. marked with the %config tag), you've edited the file afterwards and you now update the rpm then the new config file (from the newer rpm) will replace your old config file (i.e. become the active file).
The latter will be renamed with the .rpmsave suffix.
If a file was installed as part of a rpm, it is a noreplace-config file (i.e. marked with the %config(noreplace) tag), you've edited the file afterwards and you now update the rpm then your old config file will stay in place (i.e. stay active) and the new config file (from the newer rpm) will be copied to disk with the .rpmnew suffix.
See e.g. this table for all the details.
In both cases you or some program has edited the config file(s) and that's why you see the .rpmsave / .rpmnew files after the upgrade because rpm will upgrade config files silently and without backup files if the local file is untouched.
After a system upgrade it is a good idea to scan your filesystem for these files and make sure that correct config files are active and maybe merge the new contents from the .rpmnew files into the production files. You can remove the .rpmsave and .rpmnew files when you're done.
If you need to get a list of all .rpmnew .rpmsave files on the server do:
[root@redhat: ~ ]# find / -print | egrep "rpmnew$|rpmsave$
13. Reboot the system
To check whether on next hang up or power outage the system will boot normally after the upgrade, reboot to test it.
you can :
[root@redhat: ~ ]# reboot
either
[root@redhat: ~ ]# shutdown -r now
or if on newer Linux with systemd in ues below systemctl reboot.target.
[root@redhat: ~ ]# systemctl start reboot.target
14. Get again the system status with our status script after reboot
[root@redhat: ~ ]# sh /root/status.sh |tee /root/logs/status-after-$(hostname)-$(date '+%Y-%m-%d_%H-%M-%S').out
15. Clean up any versionlocks if earlier set
[root@redhat: ~ ]# yum versionlock clear
[root@redhat: ~ ]# yum versionlock list
16. Check services and logs for problems
After the reboot Check closely all running services on system make sure every process / listening ports and services on the system are running fine, just like before the upgrade.
If the sytem had firewall, check whether firewall rules are not broken, e.g. some NAT is not missing or anything earlier configured to automatically start via /etc/rc.local or some other
custom scripts were run and have done what was expected.
Go through all the logs in /var/log that are most essential /var/log/boot.log , /var/log/messages … yum.log etc. that could reveal any issues after the boot. In case if running some application server or mail server check /var/log/mail.log or whenever it is configured to log.
If the system runs apache closely check the logs /var/log/httpd/error.log or php_errors.log for any strange errors that occured due to some issues caused by the newer installed packages.
Usually most of the cases all this should be flawless but a multiple check over your work is a stake for good results.



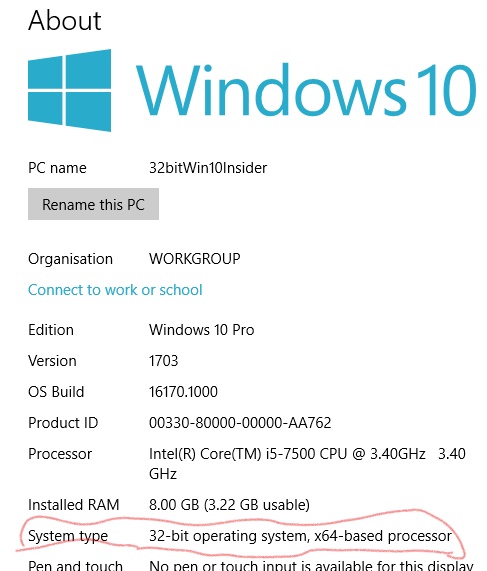
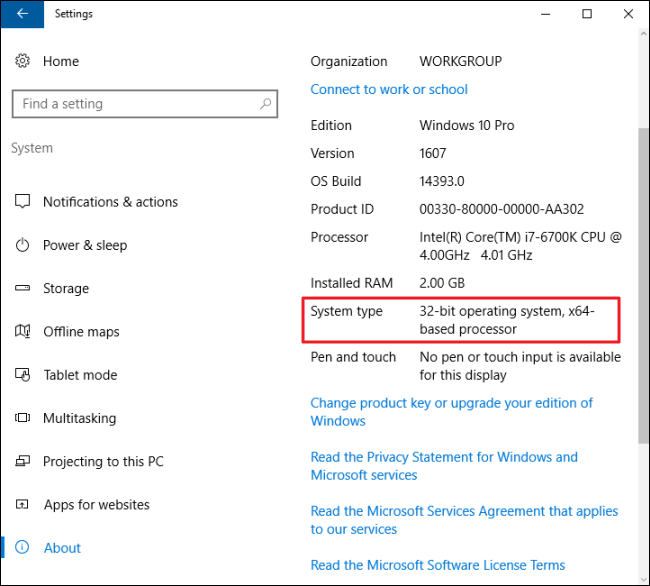
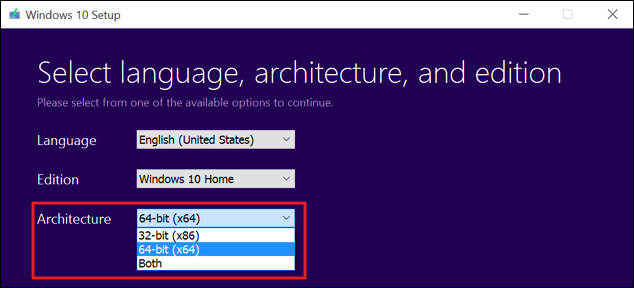



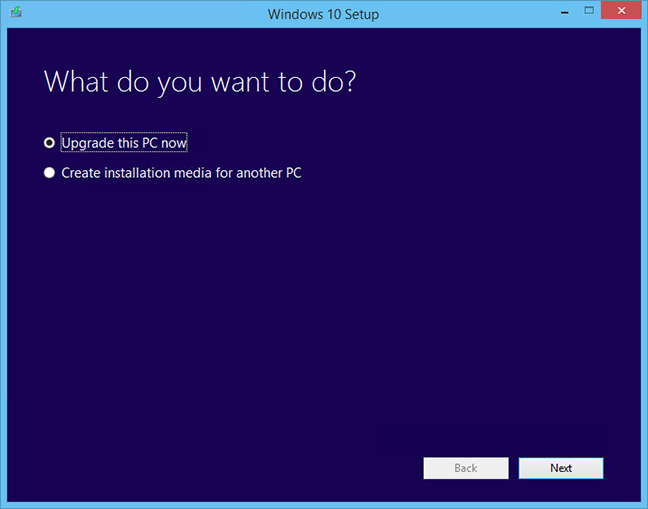
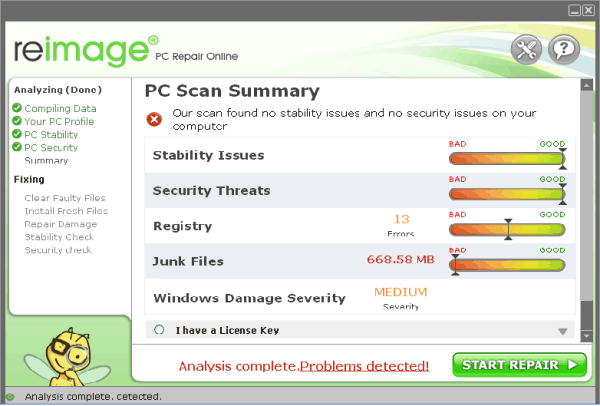
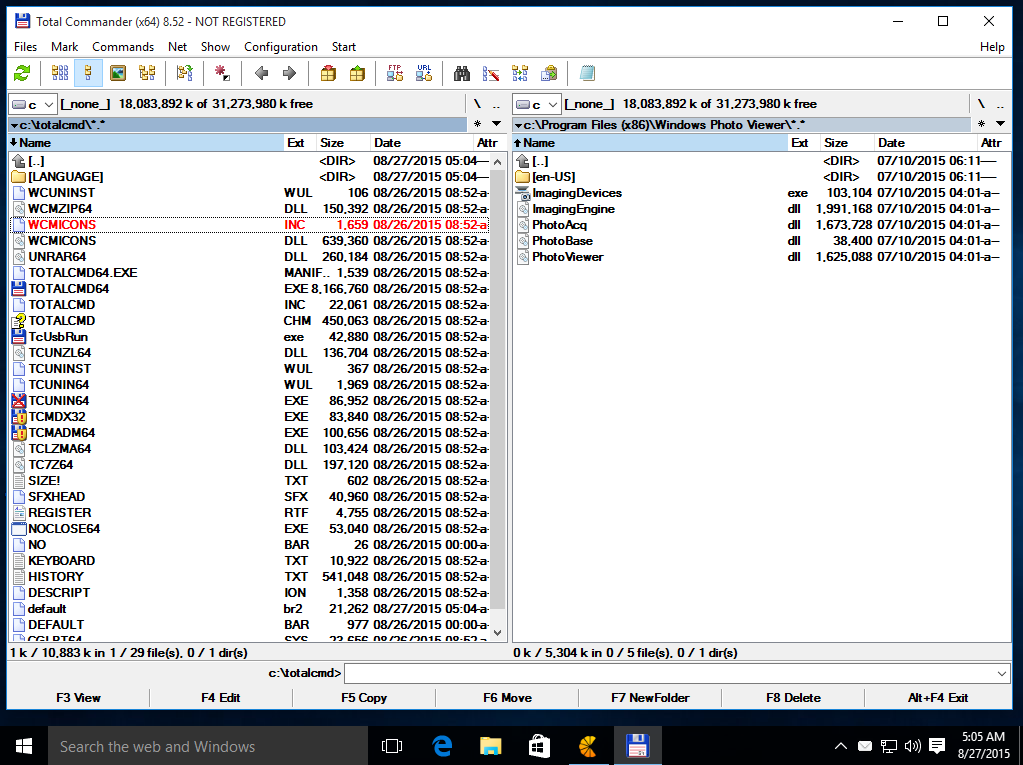
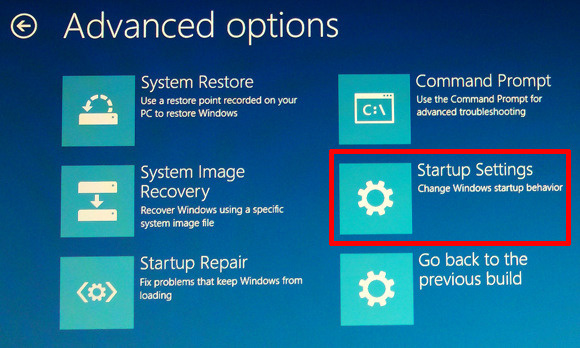
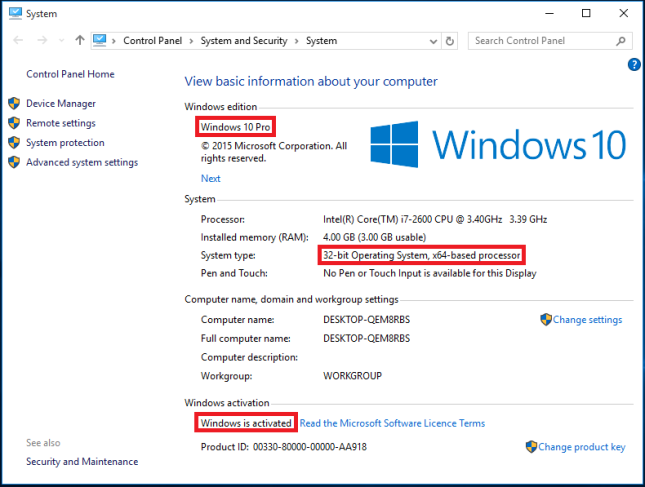







 etc.) and waiting some 30 minutes or so for the upgrade to complete.<br /> <br /> <img alt="windows-7-to-10-windows-setup-upgrade-this-pc-prompt" src="https://www.pc-freak.net/images/windows-7-to-10-windows-setup-upgrade-this-pc-prompt.png" style="width: 500px; height: 393px;" /></strong><br /> <br /> <strong>Then it was up to downloading some other updates on a few times and restarting the computer, each time the upgrades were made and all the computer was ready. I've installed Avira (AntiVirus) as I usually do on new PCs and downloaded a bunch of anti-malware (<em>MalwareBytes / Rfkill / Zemanta</em>) to make sure that the old upgraded WIndows was not already infected before the upgrade and I've found a bunch of malware, that got quickly cleared up.</strong><br /> <br /> Anyways I've tried also another tool called <a href="http://www.reimageplus.com"><strong>ReimagePlus - Online Computer Repair</strong> </a>in <strong>order to check whether there are no some broken WIndows system files after the upgrade </strong><br /> <br /> <img alt="Reimage_Repair-Windows-fix-windows-failing-services-and-broken-windows-installations-clear-up-malware" src="https://www.pc-freak.net/images/Reimage_Repair-Windows-fix-windows-failing-services-and-broken-windows-installations-clear-up-malware.png" style="width: 600px; height: 406px;" /><br /> (here I have to say I've done that besides <em>running in an Administrator command prompt</em> (<strong>cmd.exe</strong>) and running<br /> </p> <blockquote> <strong>sfc /scannow </strong> </blockquote> <p> <br /> <strong>command to check base system files integrity, which luckily showed no problems with the Win base system files.</strong><br /> <br /> <strong>ReimagePlus </strong>however showed some failed services and some failed programs that were previously installed from Windows 7 before the upgrade and even it showed indication for Trojan present on computer but since ReImagePlus is a payed software and I didn't have the money to spend on it, I just proceeded to clean up what was found manually.<br /> <br /> After that the computer ran fine, with the only strange thing that some data was from hard drive was red a bit too frequently, after a short call with a close friend (<strong>Nomen</strong>) - thx man, he suggested that the frequenty hdd usage might be related to <em><strong>Windows Search Indexing service database rebuilt</strong></em> and he adviced me to disable it which I did following <a href="https://www.howtogeek.com/howto/windows-vista/speed-up-or-disable-windows-search-indexing-in-vista/">this article How to speed up Windows by disabling Search Index Service.</a><br /> <br /> <br /> One issue worthy to mention <strong>stumbled upon after the upgrade was problems with Windows Explorer which was frequently crashing and "restarting the Desktop"</strong>, but once, I've enabled all <strong>upgrades from Microsoft and Applied them after some update failures and restarts</strong>, once all was up2date to all latest from Microsoft, Explorer started working normally. </p> <p> In the mean time while Windows Explorer was crashing in order to browse my file system I used the <a href="https://www.winnc.com/download/">good old Win Total Command or Norton Commander for Windows - WinNC (with its most cool bizzarre own File Explorer tool)</a>.<br /> <br /> <img alt="Windows-Total-commander-tool-running-on-MS-Windows-10" src="https://www.pc-freak.net/images/Windows-Total-commander-tool-running-on-MS-Windows-10.png" style="width: 500px; height: 374px;" /><br /> <br /> As I wanted to run a MalwareBytes scan and Antivirus under Windows Safe-Mode, I tried entering it by restarting the Computer and <strong>pressing F8 a number of times before the Windows boot screen but this didn't work </strong>as Safe-Mode boot was changed in Windows 10 to be callable in another way because of <strong>some extra Windows Boot speed up optimizations</strong>, in short<span style="font-size:16px;"><strong> the easiest way I found to enter Windows 10 Safe Mode was to Hit Start Button -> Choose Restart PC and keep pressed SHIFT button simultaneously</strong></span><br /> that calls a menu that gives you some restore options, along with safe mode options for those who want to read more on <a href="http://www.digitalcitizen.life/4-ways-boot-safe-mode-windows-10">How to Enter Safe mode (Command Prompt) on Windows 10 - please read this article.</a><br /> <br /> <br /> <br /> <img alt="Windows-10-enable-Safe-Mode-options-screen" src="https://www.pc-freak.net/images/Windows-10-enable-Safe-Mode-options-screen.jpg" style="width: 500px; height: 300px;" /> </p> <p> Once the upgrade was over and all below done unfortunately I've realized her previously installed <em>WIndows 7 is x86 (32 bit) version</em> and the <strong>Acer notebook 5736Z where it is being installed is actually X64 (64 bit), hence I've decided to upgrade my dear sis computer to a 64 Bit Windows 10 and researched online whether, there is some tool that is capable to upgrade WIndows 10 from 32 bit to Windows 10 64 bit just to find out the only option is to either use some program to creaty a backup of files on the PC or to manually copy files to external hard drive and reinstall with a Windows 10 64 bit bootable USB Flash or CD / DVD image, so I took my USB flash and used again Windows Media Creation Tool to burn Windows and re-install with the 64 bit iso.<br /> <br /> If you're wonder about why I choose to re-install finally<em> Win 10 32 bit with Win 64 bit</em>, because you might think performance difference might be not really so dramatic, then I have to say the Acer notebook is equipped with 4 Gigabytes of RAM Memory and Windows 10 32bit (Pro) could recognize a maximum of 3 Gigabytes (2.9 GB if I have to be precise) and 1 Gigabyte of memory stayes totally unusued with <em>Winblows 10 32 bit</em>.<br /> <br /> <em>Well that's all folks, the rest I did was to just boot from the USB drive just burned and re-install WIndows and copy my files from User profile / Downloads / Pictures / Music etc. to the same locations on the new installed Windows 10 professional 64 bit and enjoy the better performance.</em></strong> </p>){kind=link}