![]()
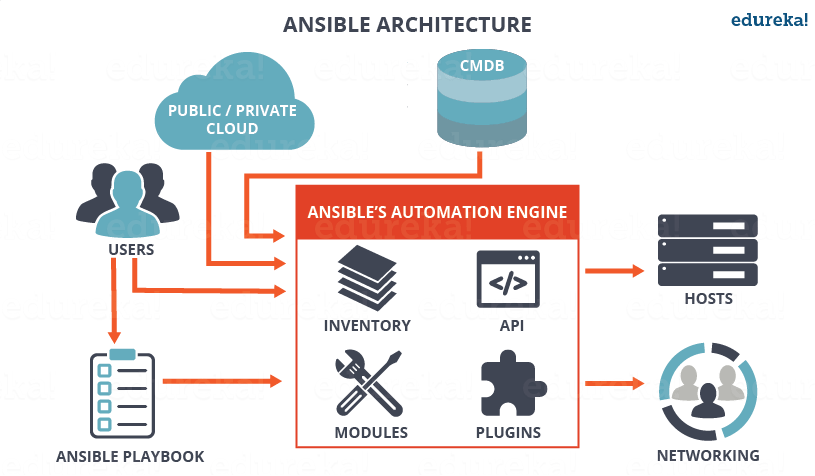
Ansible is widely used (Configuration management, deployment, and task execution system) nowadays for mass service depoyments on multiple servers and Clustered environments like, Kubernetes clusters (with multiple pods replicas) virtual swarms running XEN / IPKVM virtualization hosting multiple nodes etc. .
Ansible can be used to configure or deploy GNU / Linux tools and services such as Apache / Squid / Nginx / MySQL / PostgreSQL. etc. It is pretty much like Puppet (server / services lifecycle management) tool , except its less-complecated to start with makes it often a choose as a tool for mass deployment (devops) automation.
Ansible is used for multi-node deployments and remote-task execution on group of servers, the big pro of it it does all its stuff over simple SSH on the remote nodes (servers) and does not require extra services or listening daemons like with Puppet. It combined with Docker containerization is used very much for later deploying later on inside Cloud environments such as Amazon AWS / Google Cloud Platform / SAP HANA / OpenStack etc.
0. Instaling ansible on Debian / Ubuntu Linux
Ansible is a python script and because of that depends heavily on python so to make it running, you will need to have a working python installed on local and remote servers.
Ansible is as easy to install as running the apt cmd:
# apt-get install –yes ansible
The following additional packages will be installed:
ieee-data python-jinja2 python-kerberos python-markupsafe python-netaddr python-paramiko python-selinux python-xmltodict python-yaml
Suggested packages:
sshpass python-jinja2-doc ipython python-netaddr-docs python-gssapi
Recommended packages:
python-winrm
The following NEW packages will be installed:
ansible ieee-data python-jinja2 python-kerberos python-markupsafe python-netaddr python-paramiko python-selinux python-xmltodict python-yaml
0 upgraded, 10 newly installed, 0 to remove and 1 not upgraded.
Need to get 3,413 kB of archives.
After this operation, 22.8 MB of additional disk space will be used.apt-get install –yes sshpass
…
Installing Ansible on Fedora Linux is done with:
# dnf install ansible –yes sshpass
On CentOS to install:
# yum install ansible –yes sshpass
sshpass needs to be installed only if you plan to use ssh password prompt authentication with ansible.
Ansible is also installable via python-pip tool, if you need to install a specific version of ansible you have to use it instead, the package is available as an installable package on most linux distros.
Ansible has a lot of pros and cons and there are multiple articles already written on people for and against it in favour of Chef or Puppet As I recently started learning Ansible. The most important thing to know about Ansible is though many of the things can be done directly using a simple command line, the tool is planned for remote installing of server services using a specially prepared .yaml format configuration files. The power of Ansible comes of the use of Ansible Playbooks which are yaml scripts that tells ansible how to do its activities step by step on remote server. In this article, I'm giving a quick cheat sheet to start quickly with it.
1. Remote commands execution with Ansible
First thing to do to start with it is to add the desired hostnames ansible will operate with it can be done either globally (if you have a number of remote nodes) to deploy stuff periodically by using /etc/ansible/hosts or use a custom host script for each and every ansible custom scripts developed.
a. Ansible main config files
A common ansible /etc/ansible/hosts definition looks something like that:
# cat /etc/ansible/hosts
[mysqldb]
10.69.2.185
10.69.2.186
[master]
10.69.2.181
[slave]
10.69.2.187
[db-servers]
10.69.2.181
10.69.2.187
[squid]
10.69.2.184
Host to execute on can be also provided via a shell variable $ANSIBLE_HOSTS
b) is remote hosts reachable / execute commands on all remote host
To test whether hour hosts are properly configure from /etc/ansible/hosts you can ping all defined hosts with:
ansible all -m ping
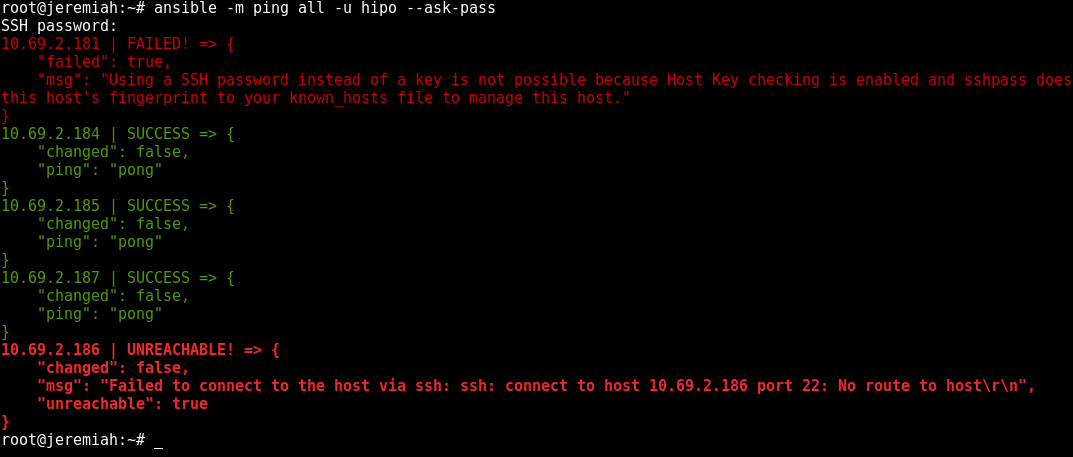
This makes ansible try to remote to remote hosts (if you have properly configured SSH public key authorization) the command should return success statuses on every host.
ansible all -a "ifconfig -a"
If you don't have SSH keys configured you can also authenticate with an argument (assuming) all hosts are configured with same password with:
ansible all –ask-pass -a "ip all show" -u hipo –ask-pass
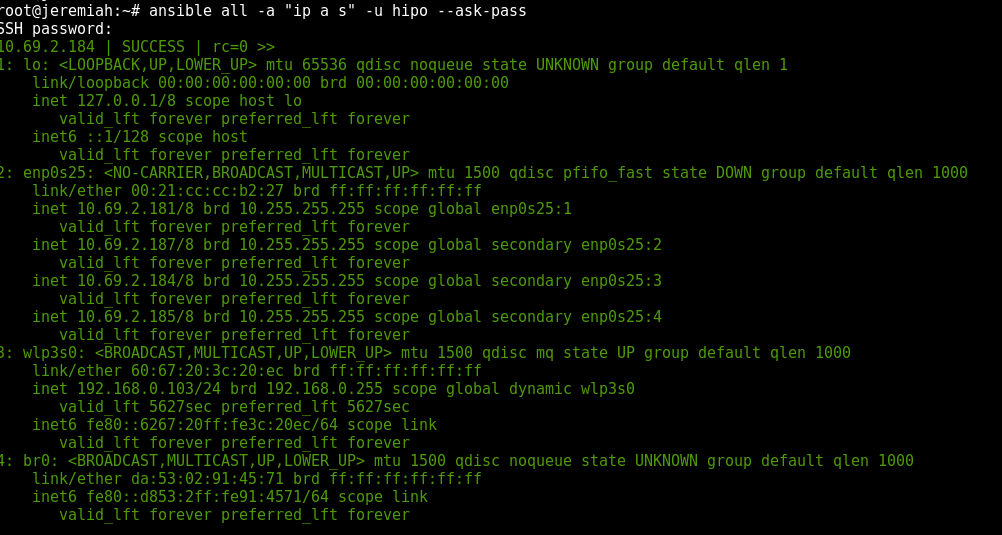
If you have configured group of hosts via hosts file you can also run certain commands on just a certain host group, like so:
ansible <host-group>
-a <command>
It is a good idea to always check /etc/ansible/ansible.cfg which is the system global (main red ansible config file).
c) List defined host groups
ansible localhost -m debug -a 'var=groups.keys()'
ansible localhost -m debug -a 'var=groups'
d) Searching remote server variables
# Search remote server variables
ansible localhost -m setup -a 'filter=*ipv4*'
ansible localhost -m setup -a 'filter=ansible_domain'
ansible all -m setup -a 'filter=ansible_domain'
# uninstall package on RPM based distros
ansible centos -s -m yum -a "name=telnet state=absent"
# uninstall package on APT distro
ansible localhost -s -m apt -a "name=telnet state=absent"
2. Debugging – Listing information about remote hosts (facts) and state of a host
# All facts for one host
ansible-m setup
# Only ansible fact for one host
ansible-m setup -a 'filter=ansible_eth*'
# Only facter facts but for all hosts
ansible all -m setup -a 'filter=facter_*'
To Save outputted information per-host in separate files in lets say ~/ansible/host_facts
ansible all -m setup –tree ~/ansible/host_facts
3. Playing with Playbooks deployment scripts
a) Syntax Check of a playbook yaml
ansible-playbook –syntax-check
b) Run General Infos about a playbook such as get what a playbook would do on remote hosts (tasks to run) and list-hosts defined for a playbook (like above pinging).
ansible-playbook
–list-hosts
ansible-playbook–list-tasks
To get the idea about what an yaml playbook looks like, here is example from official ansible docs, that deploys on remote defined hosts a simple Apache webserver.
—
– hosts: webservers
vars:
http_port: 80
max_clients: 200
remote_user: root
tasks:
– name: ensure apache is at the latest version
yum:
name: httpd
state: latest
– name: write the apache config file
template:
src: /srv/httpd.j2
dest: /etc/httpd.conf
notify:
– restart apache
– name: ensure apache is running
service:
name: httpd
state: started
handlers:
– name: restart apache
service:
name: httpd
state: restarted
To give it a quick try save the file as webserver.yml and give it a run via ansible-playbook command
ansible-playbook -s playbooks/webserver.yml
The -s option instructs ansible to run play on remote server with super user (root) privileges.
The power of ansible is its modules, which are constantly growing over time a complete set of Ansible supported modules is in its official documenation.
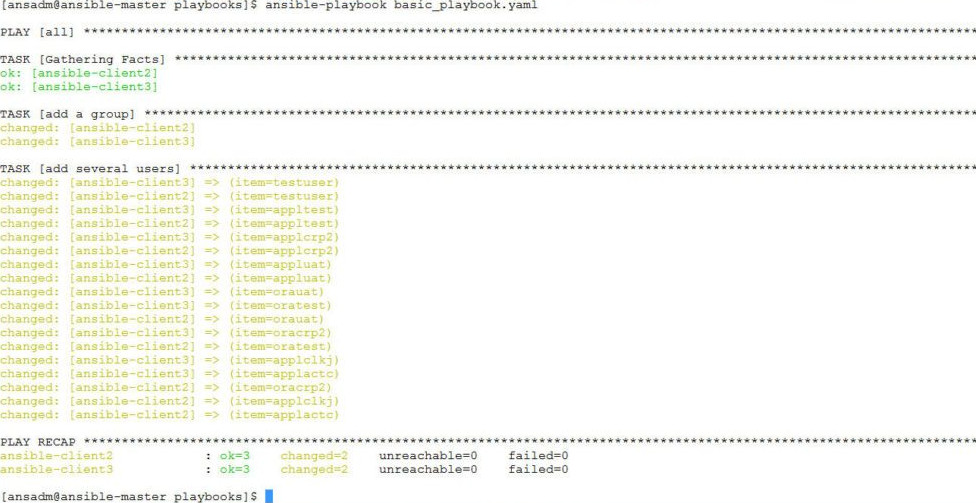
There is a lot of things to say about playbooks, just to give the brief they have there own language like a templates, tasks, handlers, a playbook could have one or multiple plays inside (for instance instructions for deployment of one or more services).
The downsides of playbooks are they're so hard to write from scratch and edit, because yaml syntaxing is much more stricter than a normal oldschool sysadmin configuration file.
I've stucked with problems with modifying and writting .yaml files and I should say the community in #ansible in irc.freenode.net was very helpful to help me debug the obscure errors.
yamllint (The YAML Linter tool) comes handy at times, when facing yaml syntax errors, to use it install via apt:
# apt-get install –yes yamllint
a) Running ansible in "dry mode" just show what ansible might do but not change anything
ansible-playbook playbooks/PLAYBOOK_NAME.yml –check
b) Running playbook with different users and separate SSH keys
ansible-playbook playbooks/your_playbook.yml –user ansible-user
ansible -m ping hosts –private-key=~/.ssh/keys/custom_id_rsa -u centos
c) Running ansible playbook only for certain hostnames part of a bigger host group
ansible-playbook playbooks/PLAYBOOK_NAME.yml –limit "host1,host2,host3"
d) Run Ansible on remote hosts in parallel
To run in raw of 10 hosts in parallel
# Run 10 hosts parallel
ansible-playbook <File.yaml> -f 10
e) Passing variables to .yaml scripts using commandline
Ansible has ability to pre-define variables from .yml playbooks. This variables later can be passed from shell cli, here is an example:
# Example of variable substitution pass from command line the var in varsubsts.yaml if present is defined / replaced ansible-playbook playbooks/varsubst.yaml –extra-vars "myhosts=localhost gather=yes pkg=telnet"
4. Ansible Galaxy (A Docker Hub) like large repository with playbook (script) files
Ansible Galaxy has about 10000 active users which are contributing ansible automation playbooks in fields such as Development / Networking / Cloud / Monitoring / Database / Web / Security etc.
To install from ansible galaxy use ansible-galaxy
# install from galaxy the geerlingguy mysql playbook
ansible-galaxy install geerlingguy.mysql
The available packages you can use as a template for your purpose are not so much as with Puppet as Ansible is younger and not corporate supported like Puppet, anyhow they are a lot and does cover most basic sysadmin needs for mass deployments, besides there are plenty of other unofficial yaml ansible scripts in various github repos.