Whether you have to administer Apache, Nginx or Lighttpd, or whatever other kind of daemon which interactively logs user requests or errors you probably already know well of tail command (tail -f /var/log/apache2/access.log) is something Webserver Linux admin can't live without. Sometimes however you have number of Virtualhost (domains) each configured to log site activity in separate log file. One solution to the problem is to use GNU Screen (screen – terminal emulator) to launch multiple screen session and launch separate tail -f /var/log/apache2/domain1/access.log , tail -f /var/log/apache2/domain2/access.log etc. This however is a bit of hack and except configuring screen to show multiple windows on one Virtual Terminal (tty or vty in gnome), you can't really see output simultaneously in one separated window.
Here is where multitail comes handy. MultiTail is tool to visualize in real time log records output of multiple logs (tails) in one shared terminal Window. MultiTail is written to use ncurses library used by a bunch of other useful tools like Midnight Command so output is colorful and very nice looking.
Here is MultiTail package description on Debian Linux:
linux:~# apt-cache show multitail|grep -i description -A 1
Description-en: view multiple logfiles windowed on console
multitail lets you view one or multiple files like the original tail
—
Description-md5: 5e2f688efb214b063bdc418a705860a1
Tag: interface::text-mode, role::program, scope::utility, uitoolkit::ncurses,
root@noah:/home/hipo# apt-cache show multitail|grep -i description -A 1
Description-en: view multiple logfiles windowed on console
multitail lets you view one or multiple files like the original tail
—
Description-md5: 5e2f688efb214b063bdc418a705860a1
Tag: interface::text-mode, role::program, scope::utility, uitoolkit::ncurses,
Multiple Tail is available across most Linux distributions to install on Debian / Ubuntu / Mint etc. Linux:
debian:~# apt-get install --yes multitail
...
On recent Fedora / RHEL / CentOS etc. RPM based Linuces to install:
[root@centos ~]# yum -y install multitail
...
On FreeBSD multitail is available to install from ports:
freebsd# cd /usr/ports/sysutils/multitail
freebsd# make install clean
...
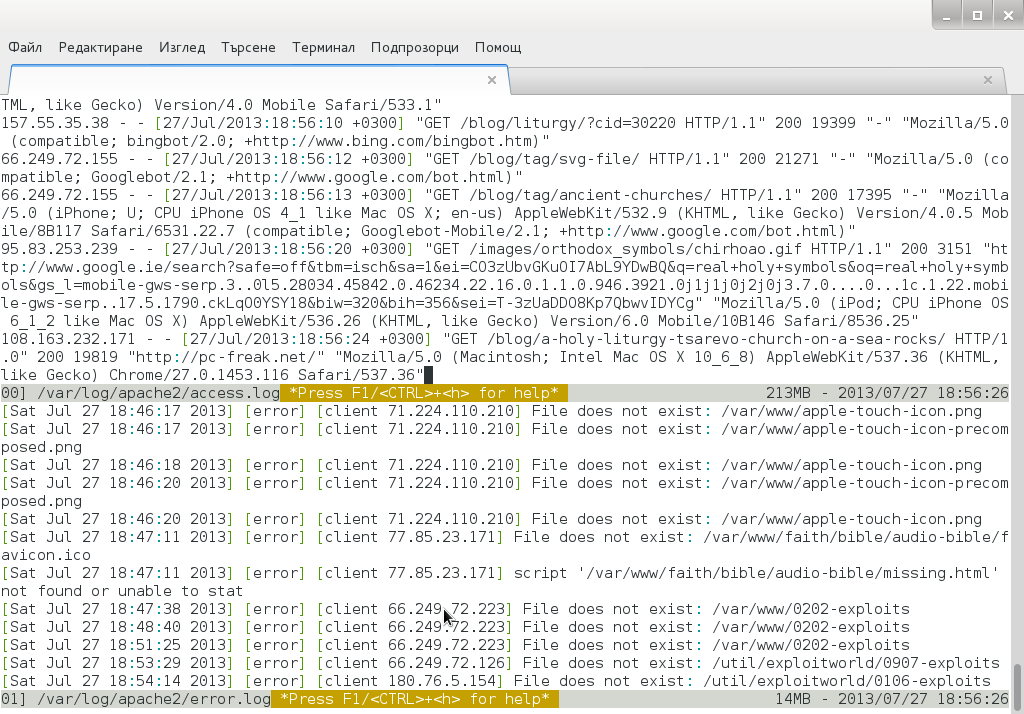
Once installed to display records in multiple files lets say Apache domain name access.log and error.log
debian:~# multitail -f /var/log/apache2/access.log /var/log/apache2/error.log
…
It has very extensive help invoked by simply pressing h while running
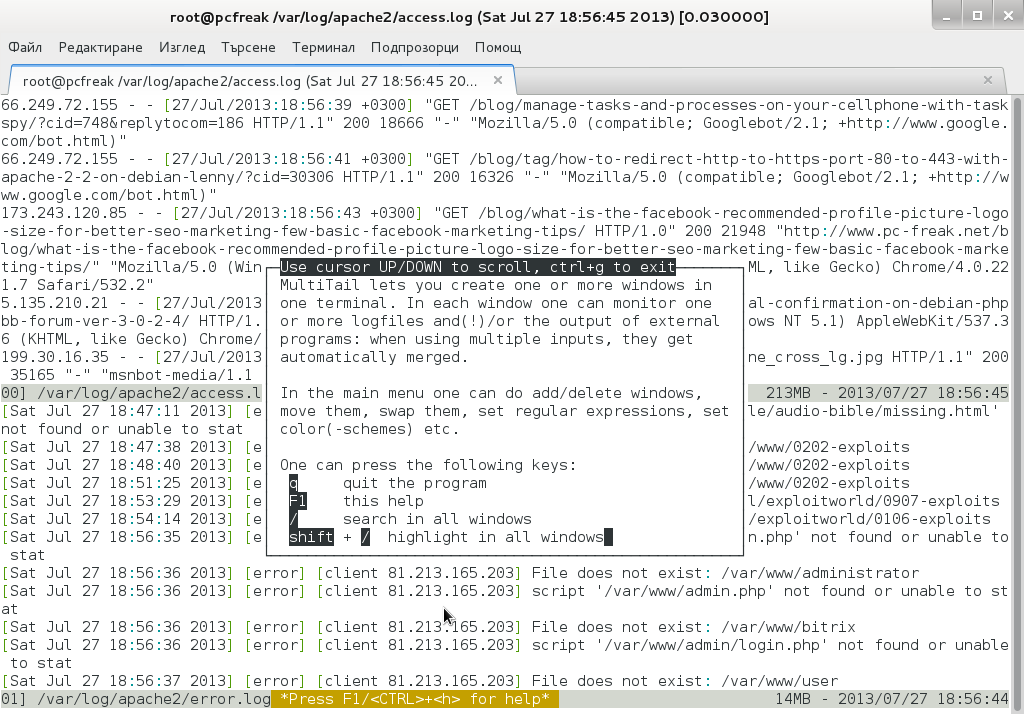
Even better multitail is written to already have integrated color schemes for most popular Linux services log files
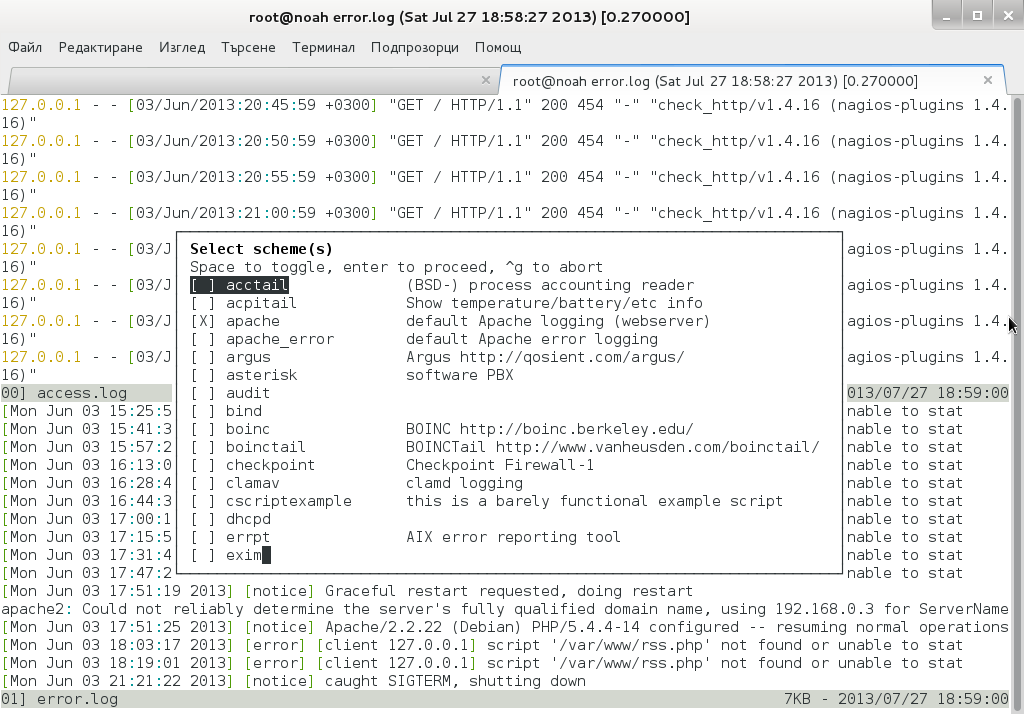
List of supported MulLog Color schemes as of time of writting article is:
acctail, acpitail, apache, apache_error, argus, asterisk, audit, bind, boinc, boinctail ,checkpoint, clamav, cscriptexample, dhcpd, errrpt, exim, httping, ii, inn, kerberos, lambamoo, liniptfw, log4j, mailscanner, motion, mpstat, mysql, nagtail, netscapeldap, netstat, nttpcache, ntpd, oracle, p0f, portsentry, postfix, pptpd, procmail, qmt-clamd, qmt-send, qmt-smtpd, qmt-sophie, qmt-spamassassin, rsstail, samba, sendmail, smartd, snort spamassassin, squid, ssh, strace, syslog, tcpdump, vmstat, vnetbr, websphere, wtmptail
To tell it what kind of log Color scheme to use from cmd line use:
debian:~# multitail -Csapache /var/log/apache2/access.log /var/log/apache2/error.log
Useful feature is to run command display in separate Windows while still following log output, i.e.:
[root@centos:~]# multitail /var/log/httpd.log -l "netstat -nat"
...
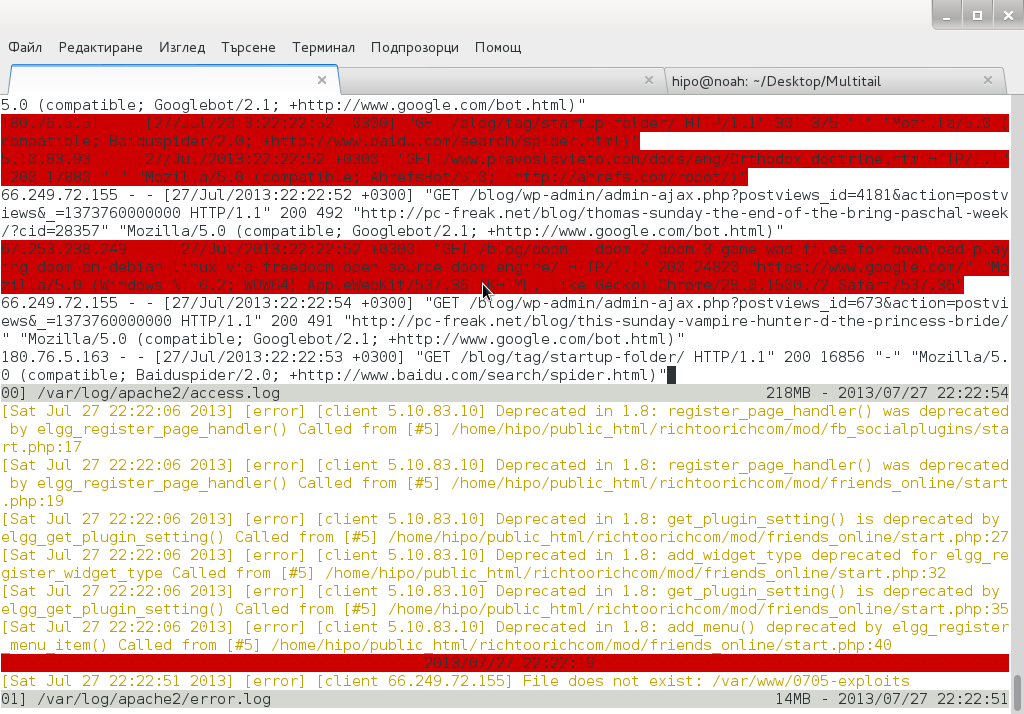
Multitail can also merge output from files in one Window, while in second window some other log or command output is displayed. To merge output from Apache access.log and error.log:
debian:~# multitail /var/log/apache2/access.log -I /var/log/apache2/error.log
When merging two log files output to show in one Window it is useful to display each file output in different color for the sake of readability
For example:
debian:~# multitail -ci green /var/log/apache/access.log -ci red -I /var/log/apache/error.log
To display output from 3 log files in 3 separate shared Windows in console use:
linux:~# multitail -s 2 /var/log/syslog /var/log/apache2/access.log /var/log/apache2/error.log
For some more useful examples, check out MultiTail's official page examples
There is plenty of other useful things to do with multitail, for more RTFM 🙂