If you are a system administrator of a dedicated server and you have no access to Xserver Graphical GNOME / KDE etc. environment and you wonder how you can track the bandwidth connectivity speed of remote system to the internet and you happen to have a modern Linux distribution, here is few ways to do a speedtest.
1. Use speedtest-cli command line tool to test connectivity
speedtest-cli is a tiny tool written in python, to use it hence you need to have python installed on the server.
It is available both for Redhat Linux distros and Debians / Ubuntus etc. in the list of standard installable packages.
a) Install speedtest-cli on Fedora / CentOS / RHEL
On CentOS / RHEL / Scientific Linux lower than ver 8:
$ sudo yum install python
On CentOS 8 / RHEL 8 user type the following command to install Python 3 or 2:
$sudo yum install python3
$ sudo yum install python2
On Fedora Linux version 22+
$ sudo dnf install python
$ sudo dnf install pytho3
Once python is at place download speedtest.py or in case if link is not reachable download mirrored version of speedtest.py on www.pc-freak.net here
$ wget -O speedtest-cli https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py
$ chmod +x speedtest-cli
Then it is time to run script 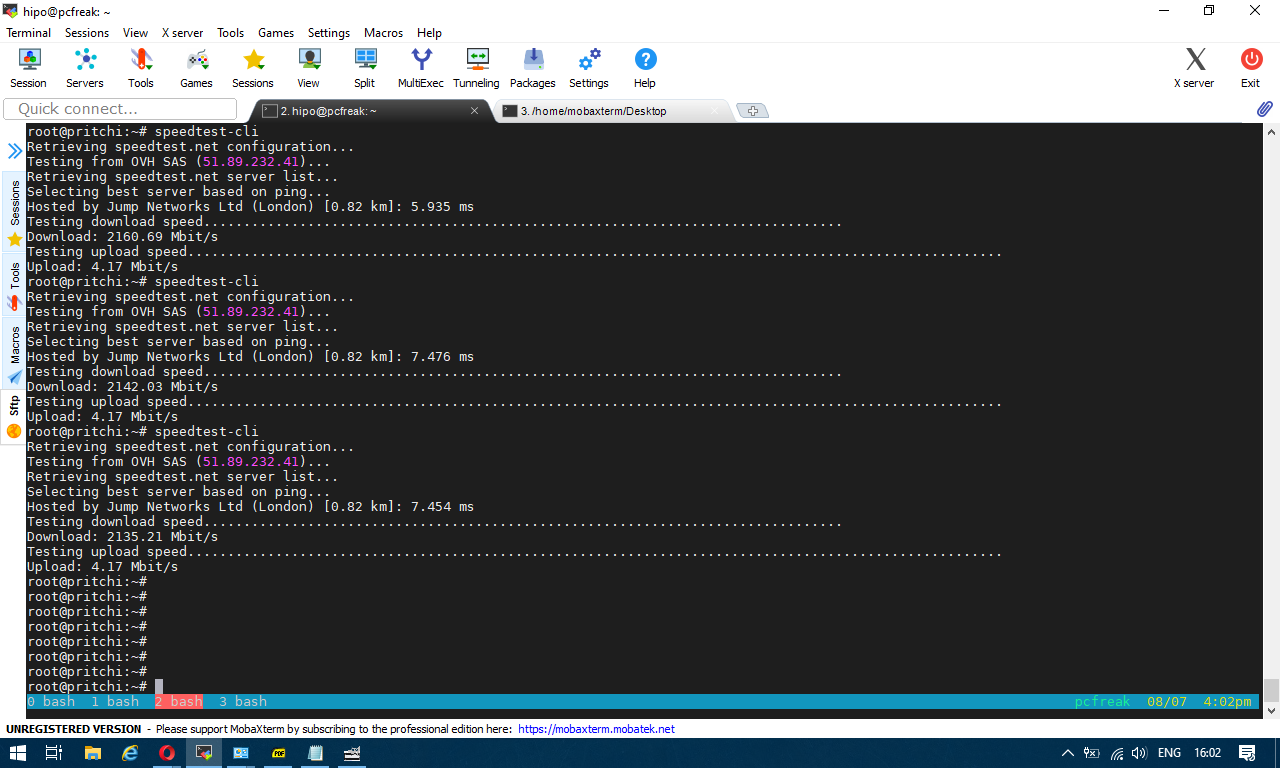
To test enabled Bandwidth on the server
$ python speedtest-cli
b) Install speedtest-cli on Debian
On Latest Debian 10 Buster speedtest is available out of the box in regular .deb repositories, so fetch it with apt
# apt install –yes speedtest-cli
…
You can give now speedtest-cli a try with –bytes arguments to get speed values in bytes instead of bits or if you want to generate an image with test results in picture just like it will appear if you use speedtest.net inside a gui browser, use the –share option
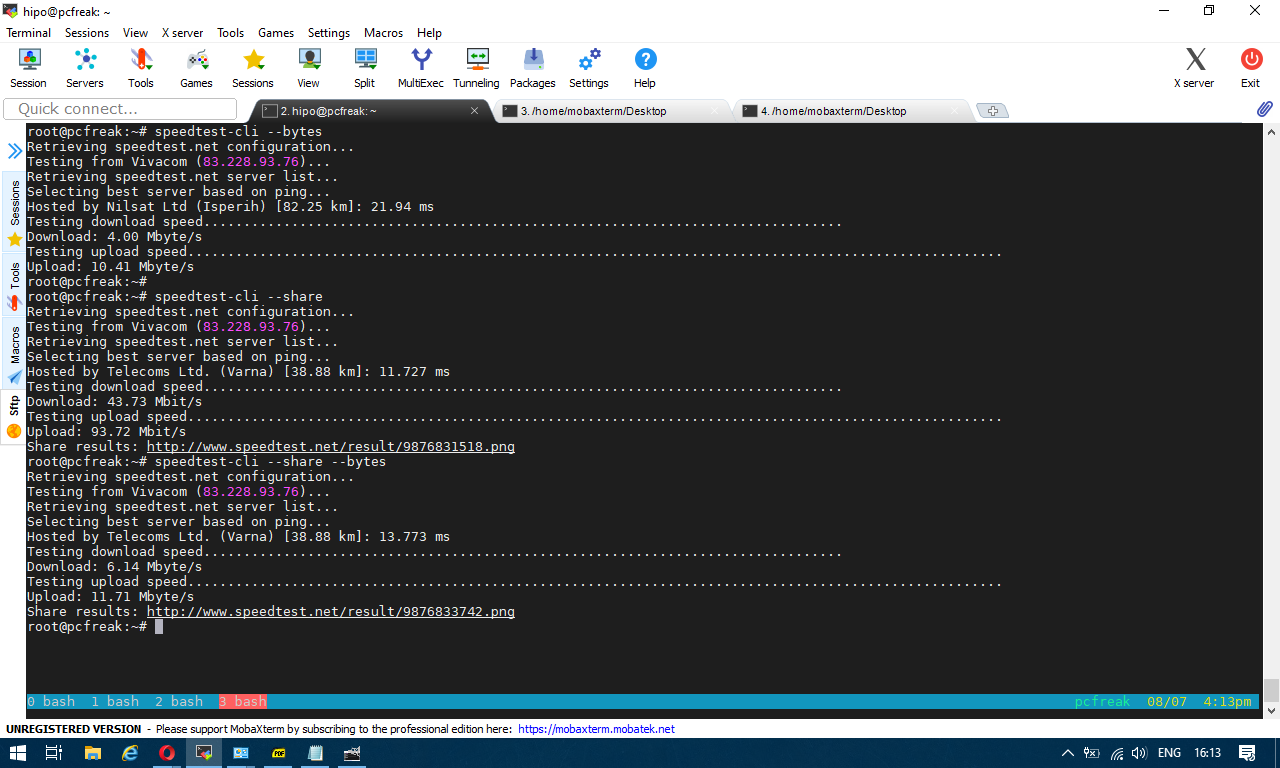
2. Getting connectivity results of all defined speedtest test City Locations
Speedtest has a list of servers through which a Upload and Download speed is tested, to run speedtest-cli to test with each and every server and get a better picture on what kind of connectivity to expect from your server towards the closest region capital cities, fetch speedtest-servers.php list and use a small shell loop below is how:
root@pcfreak:~# wget http://www.speedtest.net/speedtest-servers.php
–2020-08-07 16:31:34– http://www.speedtest.net/speedtest-servers.php
Преобразувам www.speedtest.net (www.speedtest.net)… 151.101.2.219, 151.101.66.219, 151.101.130.219, …
Connecting to www.speedtest.net (www.speedtest.net)|151.101.2.219|:80… успешно свързване.
HTTP изпратено искане, чакам отговор… 301 Moved Permanently
Адрес: https://www.speedtest.net/speedtest-servers.php [следва]
–2020-08-07 16:31:34– https://www.speedtest.net/speedtest-servers.php
Connecting to www.speedtest.net (www.speedtest.net)|151.101.2.219|:443… успешно свързване.
HTTP изпратено искане, чакам отговор… 307 Temporary Redirect
Адрес: https://c.speedtest.net/speedtest-servers-static.php [следва]
–2020-08-07 16:31:35– https://c.speedtest.net/speedtest-servers-static.php
Преобразувам c.speedtest.net (c.speedtest.net)… 151.101.242.219
Connecting to c.speedtest.net (c.speedtest.net)|151.101.242.219|:443… успешно свързване.
HTTP изпратено искане, чакам отговор… 200 OK
Дължина: 211695 (207K) [text/xml]
Saving to: ‘speedtest-servers.php’ speedtest-servers.php 100%[==========================================================================>] 206,73K –.-KB/s in 0,1s
2020-08-07 16:31:35 (1,75 MB/s) – ‘speedtest-servers.php’ saved [211695/211695]
Once file is there with below loop we extract all file defined servers id="" 's
root@pcfreak:~# for i in $(cat speedtest-servers.php | egrep -Eo 'id="[0-9]{4}"' |sed -e 's#id="##' -e 's#"##g'); do speedtest-cli –server $i; done
Retrieving speedtest.net configuration…
Testing from Vivacom (83.228.93.76)…
Retrieving speedtest.net server list…
Retrieving information for the selected server…
Hosted by Telecoms Ltd. (Varna) [38.88 km]: 25.947 ms
Testing download speed……………………………………………………………………..
Download: 57.71 Mbit/s
Testing upload speed…………………………………………………………………………………………
Upload: 93.85 Mbit/s
Retrieving speedtest.net configuration…
Testing from Vivacom (83.228.93.76)…
Retrieving speedtest.net server list…
Retrieving information for the selected server…
Hosted by GMB Computers (Constanta) [94.03 km]: 80.247 ms
Testing download speed……………………………………………………………………..
Download: 35.86 Mbit/s
Testing upload speed…………………………………………………………………………………………
Upload: 80.15 Mbit/s
Retrieving speedtest.net configuration…
Testing from Vivacom (83.228.93.76)…
…..
…
etc.
For better readability you might want to add the ouput to a file or even put it to run periodically on a cron if you have some suspcion that your server Internet dedicated lines dies out to some general locations sometimes.
3. Testing UPlink speed with Download some big file from source location
In the past a classical way to test the bandwidth connectivity of your Internet Service Provider was to fetch some big file, Linux guys should remember it was almost a standard to roll a download of Linux kernel source .tar file with some test browser as elinks / lynx / w3c.
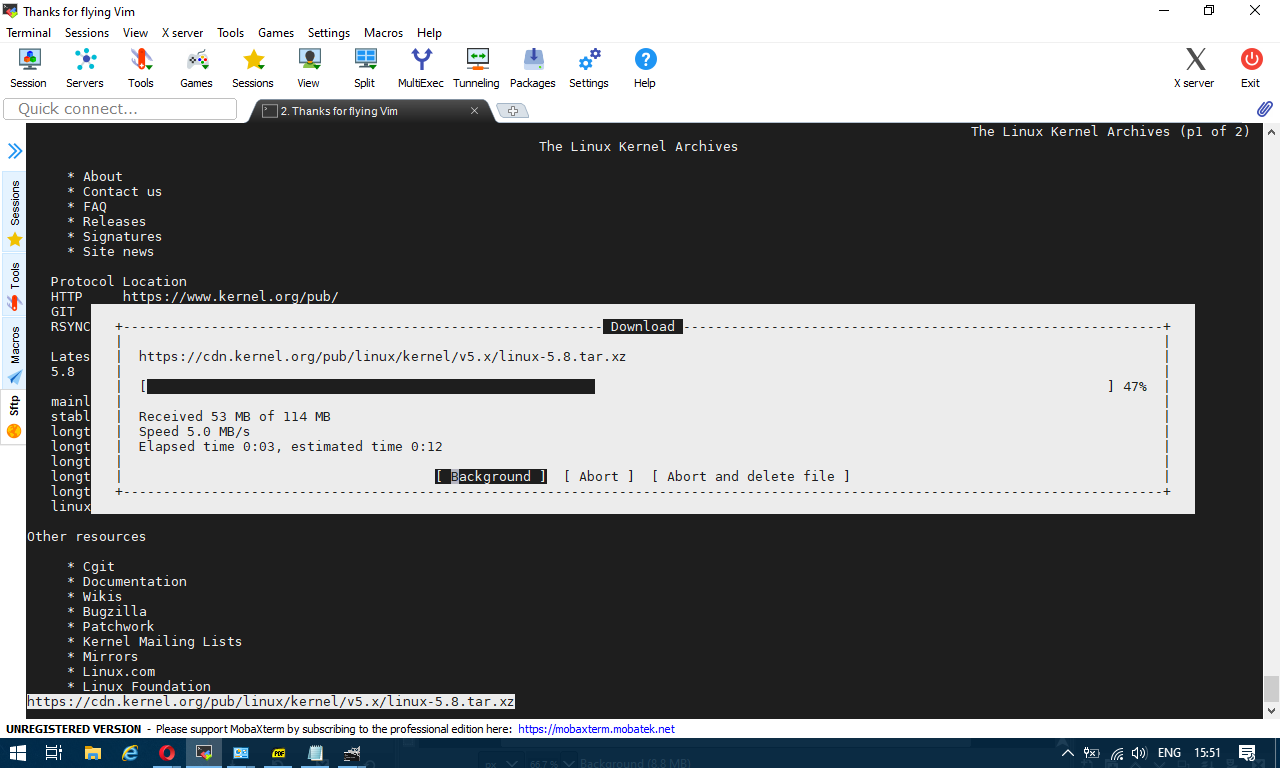
or if those are not at hand test connectivity on remote free shell servers whatever file downloader as wget or curl was used.
Analogical method is still possible, for example to use wget to get an idea about bandwidtch connectivity, let it roll below 500 mb from speedtest.wdc01.softlayer.com to /dev/null few times:
$ wget –output-document=/dev/null http://speedtest.wdc01.softlayer.com/downloads/test500.zip
$ wget –output-document=/dev/null http://speedtest.wdc01.softlayer.com/downloads/test500.zip
$ wget –output-document=/dev/null http://speedtest.wdc01.softlayer.com/downloads/test500.zip
# wget -O /dev/null –progress=dot:mega http://cachefly.cachefly.net/10mb.test ; date
–2020-08-07 13:56:49– http://cachefly.cachefly.net/10mb.test
Resolving cachefly.cachefly.net (cachefly.cachefly.net)… 205.234.175.175
Connecting to cachefly.cachefly.net (cachefly.cachefly.net)|205.234.175.175|:80… connected.
HTTP request sent, awaiting response… 200 OK
Length: 10485760 (10M) [application/octet-stream]
Saving to: ‘/dev/null’
0K …….. …….. …….. …….. …….. …….. 30% 142M 0s
3072K …….. …….. …….. …….. …….. …….. 60% 179M 0s
6144K …….. …….. …….. …….. …….. …….. 90% 204M 0s
9216K …….. …….. 100% 197M=0.06s
2020-08-07 13:56:50 (173 MB/s) – ‘/dev/null’ saved [10485760/10485760]Fri 07 Aug 2020 01:56:50 PM UTC
To be sure you have a real picture on remote machine Internet speed it is always a good idea to run download of random big files on a certain locations that are well known to have a very stable Internet bandwidth to the Internet backbone routers.
4. Using Simple shell script to test Internet speed
Fetch and use speedtest.sh
wget https://raw.github.com/blackdotsh/curl-speedtest/master/speedtest.sh && chmod u+x speedtest.sh && bash speedtest.sh
5. Using iperf to test connectivity between two servers
iperf is another good tool worthy to mention that can be used to test the speed between client and server.
To use iperf install it with apt and do on the server machine to which bandwidth will be tested:
# iperf -s
On the client machine do:
# iperf -c 192.168.1.1
where 192.168.1.1 is the IP of the server where iperf was spawned to listen.
6. Using Netflix fast to determine Internet connection speed on host
Fast
fast is a service provided by Netflix. Its web interface is located at Fast.com and it has a command-line interface available through npm (npm is a package manager for nodejs) so if you don't have it you will have to install it first with:
# apt install –yes npm
Note that if you run on Debian this will install you some 249 new nodejs packages which you might not want to have on the system, so this is useful only for machines that has already use of nodejs.
$ fast
82 Mbps ↓
The command returns your Internet download speed. To get your upload speed, use the -u flag:
$ fast -u
⠧ 80 Mbps ↓ / 8.2 Mbps ↑
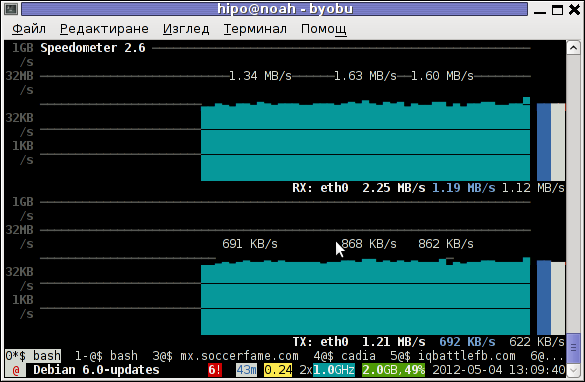
7. Use speedometer / iftop to measure incoming and outgoing traffic on interface
If you're measuring connectivity on a live production server system, then you might consider that the measurement output might not be exactly correct especially if you're measuring the Uplink / Downlink on a Heavy loaded webserver / Mail Server / Samba or DNS server.
If this is the case a very useful tools to consider to extract the already taken traffic used on your Incoming and Outgoing ( TX / RX ) Network interfaces are speedometer and iftop, they're present and installable depending on the OS via yum / apt or the respective package manager.
To install on Debian server:
# apt install –yes iftop speedometer
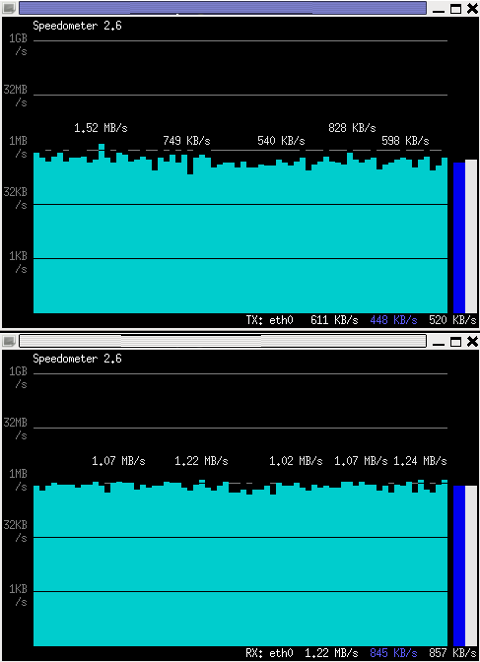
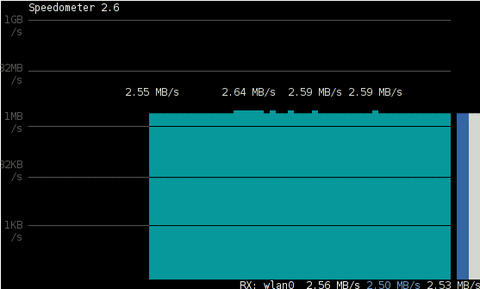
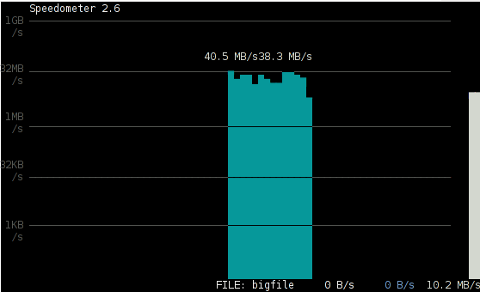
The most basic use to check the live received traffic in a nice Ncurses like text graphic is with:
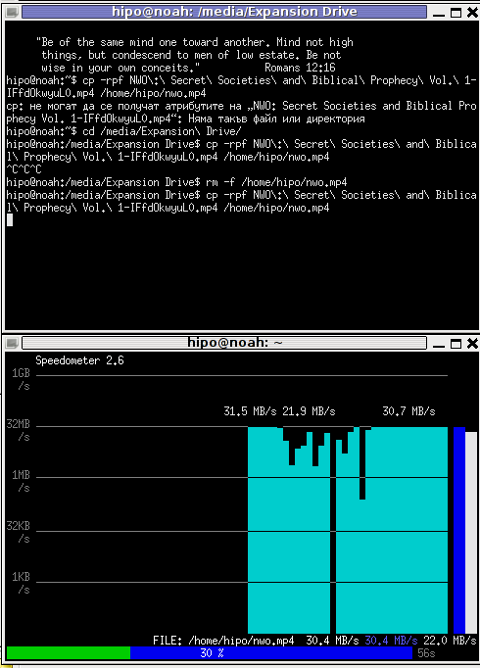
# speedometer -r
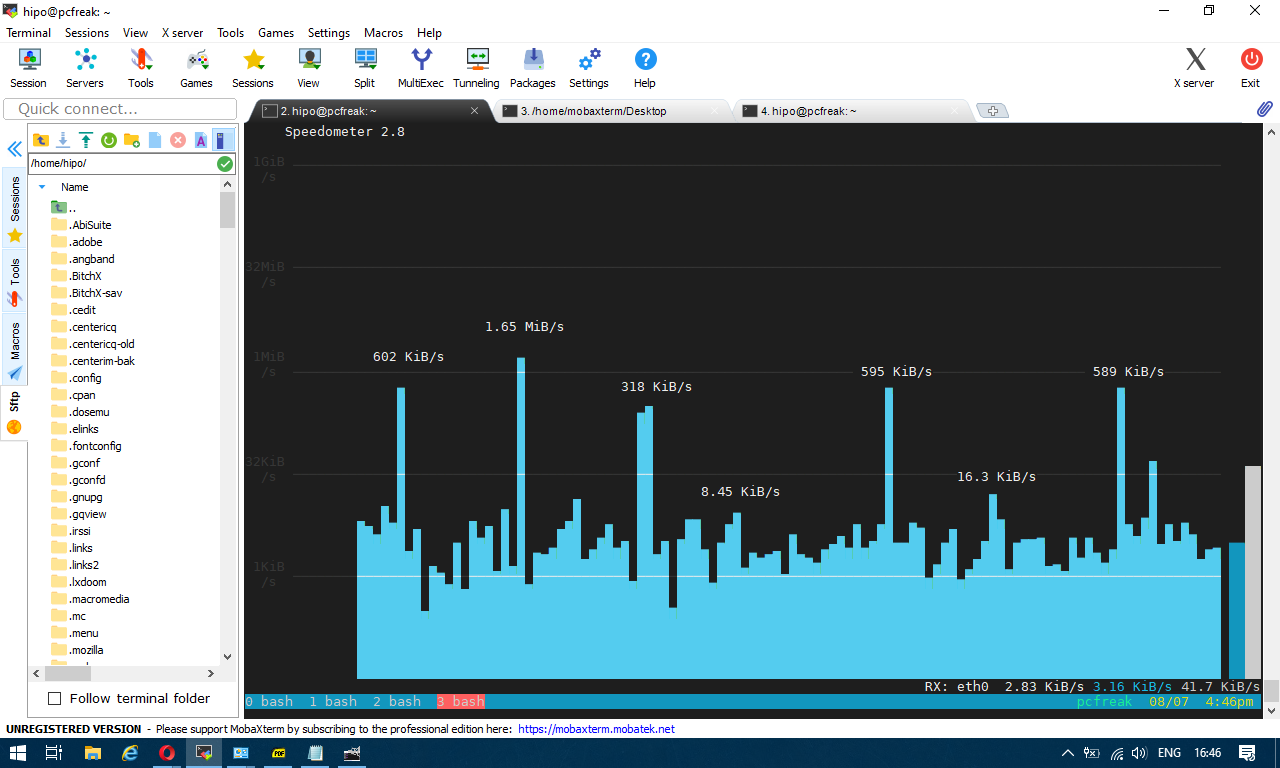
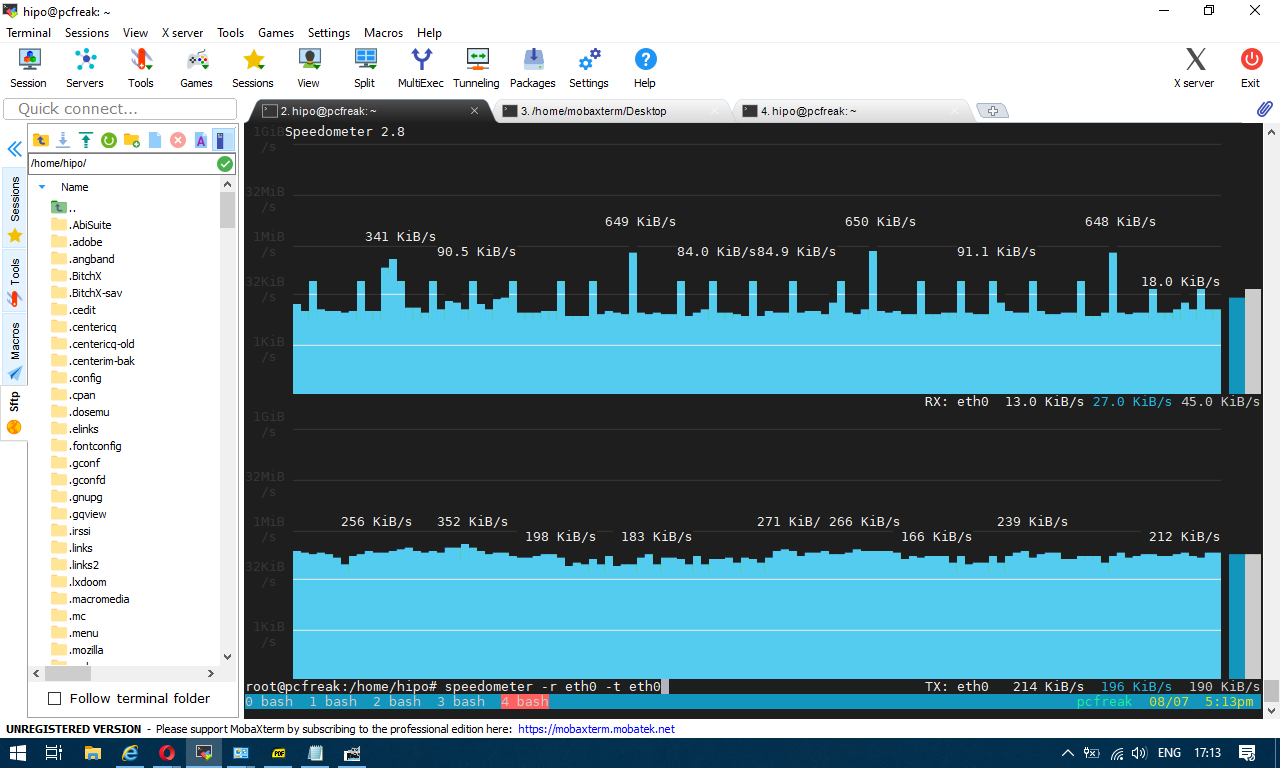
To generate real time ASCII art graph on RX / TX traffic do:
# speedometer -r eth0 -t eth0
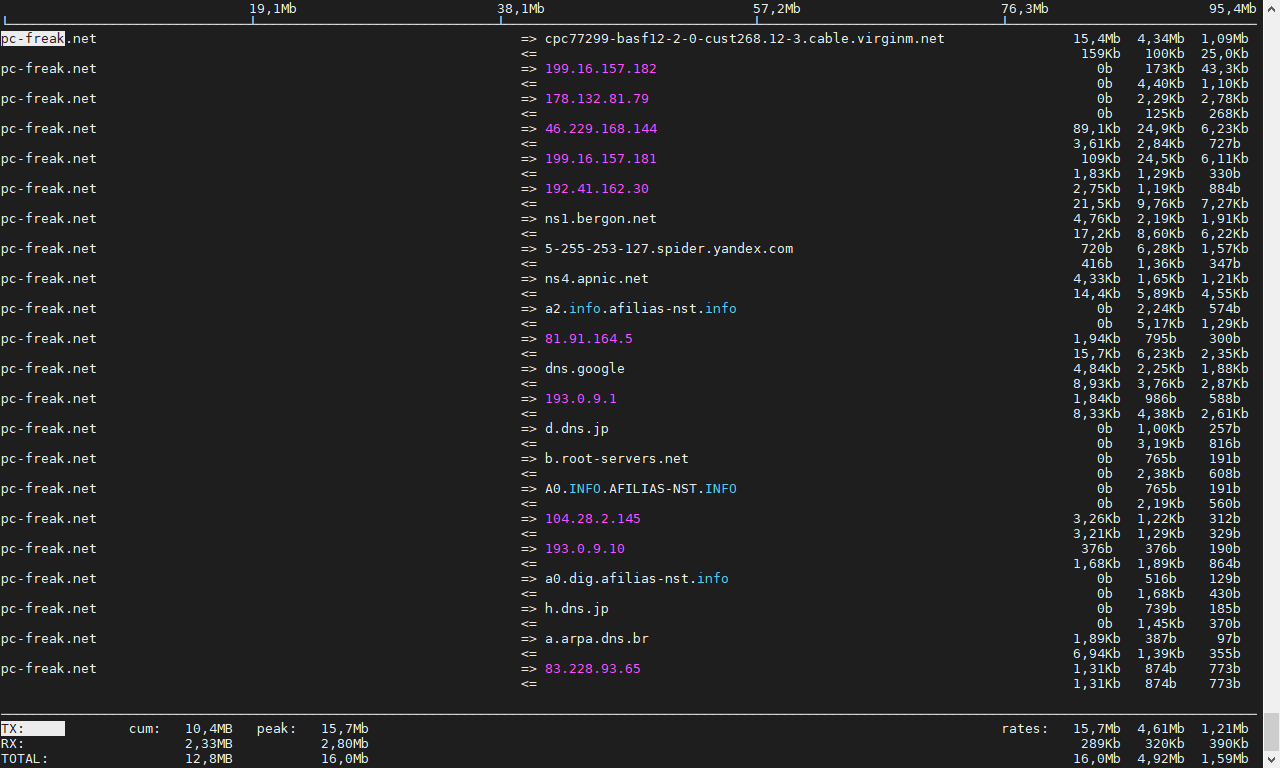
# iftop -P -i eth0








Baby boomers and Generation X, Y, Z – Generational Marketing and 4 Common personality stereotype traits of people born over the last 60 years
Saturday, August 18th, 2018Those who are employed in the realm of Social or Internet Marketing definitely have to know the existence of at least 4 different conditional stereotypes, these are Baby Boomers and Generation X, Generation Y and Generation Z (Millenials).
According to Socielogist Karl Mannheim (who is among the founding fathers of classical socielogy) – "All members of a generation share a similar collective experience" or in other words people are categorized in generations depending on when they were born.
As stereotypes they're generalization of people born in different periods of time and sharing same or similar traits.
Because of the age and the conditions they grew up and as they share those general spirit of time and age, they tend to be more or less behaving in a similar ways in how they think save / spend money or share some common approach to life choices and attitude towards life and worldview.
But before proceeding to the 4 main cohert provisional stereotypes, its worthy to mention how these four common trait generations came to existence with a little bit of pre-history.
The pre WW I and WW II world situation and the First and Second World War played a pivotal role in forming the social conditions necessery for the development of the baby boomers.
* The depression Era people
Born in period: 1912 – 1921 who came at full maturity around 1930-1939 right in the beginning of WW I (all of whom are already deceased) as of 2018 as a cause of the war uncertainty and the havoc and the war conditions were very conservative, compulsive savers, tried their best to maintain a low debt. They had the mindset (responsibility) to leave some kind of legacy to their children. They were very patriotic, oriented towards work before pleasure, had a great respect for authority and had a strong sense of moral obligation. For all this character traits of this people undoubtfully a key role played the strong belief in God mostly all people had at the time.
The next in line conditional stereotype of people that came to earth are the:
* The World War II Generation
Born in year period: 1922 to 1927 who came to a mature age exactly at the terrible years of Second World War.
People of that time were either fighters for or against the Axis Powers or the Central Powers with the common shared goal to fight against the enemy (of course there are multiple of people who were just trying to survive and not taking a side in this meaningless war).
The current amount of people living are estimated to few million of deathbed elders worldwide.
As above conditional generations types mentioned are of importance for historical reasons and most of the people belonging to those depression pre WWI and WW II era are dead or just a few millions an overall in un less-consuming age (excluding the medicine consumption which is higher compared to youngsters).
I'll further proceed further with the Baby Boomers, GEN X, Y, Zs who are de-facto the still active members participating to society and economy more or less.
So what are these 4 Stereotypes of Generations that and why are so important for the modern marketers or business manager?
1. BABY BOOMERS also called for a short (Boomers)
These are people who have been defined by a birth year range (period) from early to mid 1940s until 1960 and 1964.
In Europe and North America, boomers are widely identified with privilege, as many grew up in a time of widespread government subsidies in post-war housing and education, and increasing affluence.
As a group, baby boomers were considered the wealthiest, most active, and most physically fit generation up to the era in which they arrived, and were amongst the first to grow up genuinely expecting the world to improve with time. They were also the generation that received peak levels of income; they could therefore reap the benefits of abundant levels of food, apparel, retirement programs, and sometimes even "midlife crisis" products. The increased consumerism for this generation has been regularly criticized as excessive (and that's for a good reason).
One feature of the boomers was that they have tended to think of themselves as a special generation, very different from those that had come before or that has come afterward. In the 1960s, as the relatively large numbers of young people became teenagers and young adults, they, and those around them, created a very specific rhetoric around their cohort, and the changes they were bringing about. This rhetoric had an important impact in the self perceptions of the boomers, as well as their tendency to define the world in terms of generations, which was a relatively new phenomenon. The baby boom has been described variously as a "shockwave" and with a methapors such as as "the pig in the python".
2. Generation X / GEN X
Generation X is considered the people born in the following birth year period 1960 forward in time until 1980s. A specific feature in the 60s-80s period was the shifting societal values, perhaps the spring of this generation was also connected to the increasing role and spread of communism in the world.
Sometimes this generation was referred as the "latchkey generation".
The term generation X itself was popularized largely by Douglas Coupland in his novel 1991 novel Generation X Tales for an Accelerated Culture
A very common trait for Generation X was the reduced adult supervision over kids when compared to previous generations a result of increasing divorce rates and the increased role of one parent children upbringing (in most cases that was the mother) which had to be actively involved as a workforce and lacked physically the time to spend enough time with its children and the increased use of childcare options in one parent families.
They were dubbed the "MTV" (Music Television) generation – that was a hit and most popular music TV in the early 1990s.
The kids representing generation X were described as slackers, cynical and disaffected.
The cultural influences dominating the tastes and feelings of the teen masses of that generation was musical genres such as punk music, heavy metal music, grunge and hip-hop and indie films (independent films) produced outside of the major film studio system.
According to many researches in midtime those generation are described as active, happy and achieving a work-life balance kind of lifestyle.
People belonging to Generation X are described as people with Enterpreneural tendencies.
Just to name a few of the celebrities and successful people who belong to this generation, that's Google's founder Sergey Brinn & Larry Page (born in 1973), Richard Stallman (founder of Free Software movement) as well movie and film producer celebrities such as Georgi Clooney, Lenny Kravitz, Quantin Tarantino, Kevin Smith, David Fincher etc.
According to United Kingdom survey study of 2500+ workers conducted by Workfront, GEN X are found to be among the hardest working employees in today's workforce. They are also ranked high by fellow workers for having a strong work ethics (about 59.5%), being helpful (55.4%) and very skilled (54.5%) of respondents as well marked as the best troubleshooters / problem solvers (41.6%) claimed so.
According to research conducted by Viacom, gen x they have a high desire for flexibility and fulfillment at work.
3. Generation Y (Millenials) – GEN Y
Following Generation X came on earth Genreation Y the birth period dated for this kids were years are stretchy year period that this generation is described are years 1980s – 1990s to yearly 2000s where birth period range of those ppl ends.
This kids are descendants of the GEN X and second wave Baby Boomers.
In the public this generation is referred as "echo boomers".
The Millenials characteristics are different based on the region of birth, they're famous for the increased familiarity with communication, media and digital technologies.
There upbringing was marked by increase in liberal approach to politics.
The Great recession crisis of the 2000s played a major impact on this generation because it has caused historical high levels of un-employment among youngsters and led to a possible long term economic and social damage to this generation.
Gen Y according are less brand loyal and the speed of the Internet has led the cohort to be similarly flexible and changing in its fashion, style consciousness and where
and how it is communicated with.
As I am born in 1983 me and my generation belongs to Generation Y and even though Bulgaria before 1991 was a Communist regime country, I should agree that I and many of my friends share a very similar behavior and way of thinking to the GEN Y stereotype described, but as I was born in a times of transition and Bulgaria as a Soviet Union Satellite at the time has been lacking behind in fashion and international culture due to the communist regime, me and my generation seem to be sharing a lot of common stereotype characteristics with Generation X such as the punk-rock, metal, hip-hop culture MTV culture and partly because of the GEN X like overall view on life.
Among most famous representative successful people of the Millenials generation are Mark Zuckerberg (Facebook founder), Prince William (the second in line to the British throne), Kim Jong Un (the leader dictator of North Korea) etc.
4. Generation Z ( GEN Z) / iGeneration / Generation Sensible (Post Millenials)
Following Millenials generation is GEN Z, demographers and researchers typically set as a starting birth date period of those generation 1990s and mid 2000s. As of time of writting there is still no clear consensus regarding ending birth years.
This is the so called Internet Generation because this generation used the internet and Smart Mobile Phone technology since a very young age, they are very confortable with technology (kinda of wired) and addicted to social media such as Facebook / Twitter / Instagram etc. Because of the level of digital communication, many people of this generation are more introvert oriented and often have problems expressing themselves freely in groups. Also they tend to lack the physical communication and more digitally community oriented, even though this depends much also on the specific personality and in some cases it is exactly the opposite.
* Summary
As a Marketer, Human Resources hiring personal specialist, a CEO or some kind of project / business manager it is a good idea to be aware of these 4 common stereotypes. However as this are stereotypes (and a theory) as everything theoritized the data is slighly biased and untrue. The marketer practice shows that whoever conducts a marketing and bases his sales on this theoritizing should consider this to be just one aspect of the marketing campaign those who are trying to sell, stuff ideas or ideology to any of those generation should be careful not to count 100% on the common traits found among the above 4 major groups and consider the individuality of person everyone has and just experiment a little bit to see what works and what doesn't.
Also it should be mentioned these diversification of stereotypes are mostly valid for the US citizens and Westerners but doesn't fully fit to ex-communist countries or countries of the Soviet union, those countries have a slightly different personality traits of person born in any of the year periods defined, same is more or less true for the poor parts of Africa and India, Vietnam, China and mostly all of the coomunist countries ex and current. It should be said that countries who belonged to the Soviet Union many of which are current Russian Federation Republics have a personality traits that are often mixture of the 4 stereotypes and even have a lot of the traits that were typical for the WW I and WW II generations, which makes dealing with this people a very weird experience.
Nomatter the standard error that should always considered when basing a marketing research hypothesis on Generational Marketing (using generational segmentation in marketing best potential customer targets), having a general insight and taking in consideration those stereotypes could seriously help in both marketing as well as HR specific fields like Change Management.
If you're a marketer, I recommend you take a quick look also on following very educative article Generational Makarketing and how to target each of the GEN X, Y, Z and Baby Boomers and what works best for each of them.
Nomatter what just like all Theories, the theory of Boomers and the Generation segmantation is not completely true, but it gives a good soil for reasoning as well definitely helps for people involved in sociology and business.
Comments and feedback on the article are mostly welcome as the topic is very broad and there is much more to be said …
Hope the article was interesting to you ….
What was your Generation like?
Tags: about, Achieving, africa, against, age, ALL, amount, birth, Comments, common, generations, key role, last, MTV, periods, personality, python, time, times, years
Posted in Business Management, Curious Facts, Economy, Educational, Politics, Psychology | No Comments »