If you're working in a middle or big sized IT company or corporation like IBM or HP, you're already sucked into the Outlook "mail whirlwind of corporate world" and daily flooded with tons of corporate spam emails with fuzzy business random terms like taken from Corporate Bullshit Generator
Many corporations, because probably of historic reasons still provide employees with small sized mailboxes half a gigabyte, a gigabyte or even in those with bigger user Mailboxes like in Hewlett Packard, this is usually no more than 2 Gigabytes.
This creates a lot of issues in the long term because usually mail communication in Inbox, Sent Items, Drafts Conversation History, Junk Email and Outbox grows up quickly and for a year or a year and a half, available Mail space fills up and you stop receiving email communication from customers. This is usually not too big problem if your Mailbox gets filled when you're in the Office (in office hours). However it is quite unpleasent and makes very bad impression to customers when you're in a few weeks Summar Holiday with no access to your mailbox and your Mailbox free space depletes, then you don't get any mail from the customer and all the time the customer starts receiving emails disrupting your personal or company image with bouncing messages saying the "INBOX" is full.
To prevent this worst case scenario it is always a good idea to archive old mail communication (Items) to free up space in Outlook 2010 mailbox. Old Outlook Archived mail is (Saved) exported in .PST outlook data file format. Later exported Mail Content and Contacts could be easily (attached) from those .pst file to Outlook Express, leaving you possibility to still have access to your old archived mail keeping the content on your hard drive instead on the Outlook Exchange Mailserver (freeing up space from your Inbox).
Here is how to archive your Outlook mail Calendar and contacts:
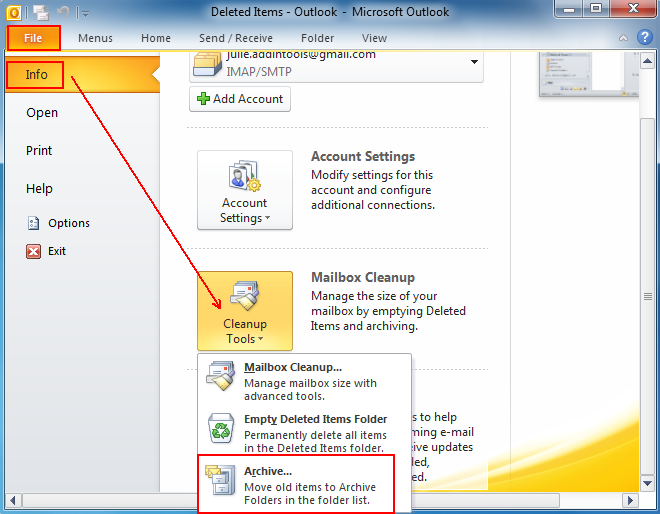
1. Click on the "File" tab on the top horizontal bar.Select "Cleanup Tools" from the options.
2. Click "Cleanup Tools" from the options.
3. Click on the "Archive this folder and all subfolders" option.
4. Select what to archive (e.g. Inbox, Drafts, Sent Items, Calendar whatever …)
5. Choose archive items older than (this is quite self-explanatory)
6.Select the location of your archive file (make sure you palce the .PST file into directory you will not forget later)
That's all now you have old mails freed up from Outlook Exchange server. Now make sure you create regular backups ot old-archived-mail.pst file you just created, it is a very good idea to upload this folder to encrypted file system onUSB stick or use something like TrueCrypt to encrypt the file and store it to external hard drive, if you already don't have a complete backup corporate solution backuping up all your Laptop content.
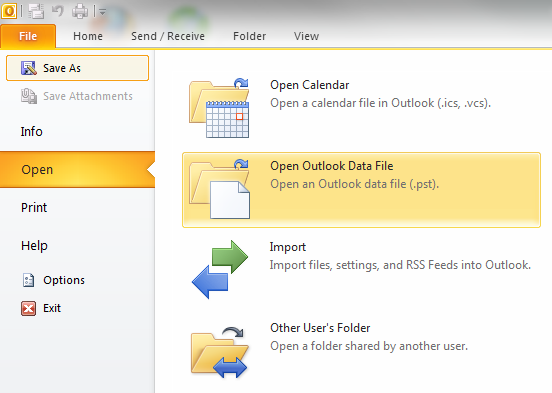
Later Attaching or detaching exported .PST file in Outlook is done from:
File -> Open -> Open Outlook Data File
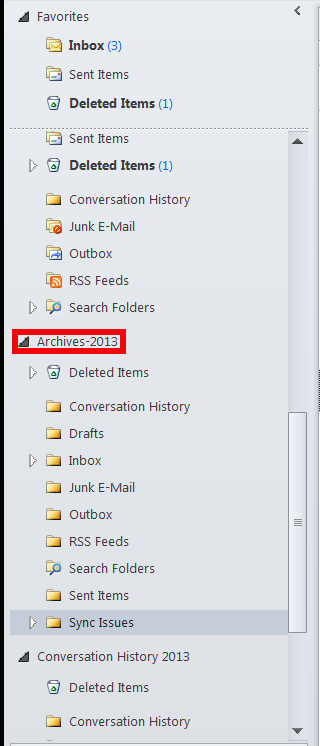
Once .PST file is opened and attached in Left Inbox pane you will have the Archived old mail folder appear.
You can change Archived name (like I did to some meaningful name) like I've change it to Archives-2013 by right clicking on it (Data File properties -> Advanced)
I'm filling up a TOP (Turn to Production) form for a project where my part as Web and Middleware Engineer included install of Tomcat 7 and Java 1.7 on Windows server 2008 R2 standard. TOP is required Excel sheet standard document used by many large companies to fill in together with Project Manager before the server is to be launched into Production mode.
Therefore I needed to find out previously installed Tomcat and Java version, here is how:
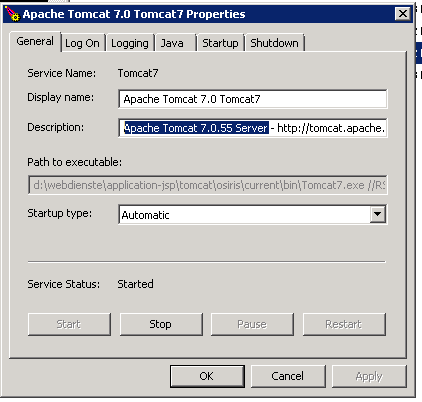
1. Go to Tomcat install directory and (click twice) run twice Tomcat7w
As tomcat is installed in Custom location in D:webdienste in this case I had to run:
I run it using command line (cmd.exe), however you can run it via Windows Explorer, if you're lazy typing. You will get a window pop up like on below screenshot:
In this case Installed Tomcat version was 7.0.55
If you need to check the version on older Tomcat application server install you can run instead Tomcat6w – whether its Tomcat version 6 or Tomcat5w – for Tomcat ver. 5
In order to Check the java version the quickest way is via command line, again run cmd.exefrom
Start -> Run -> cmd.exe
Then cd to whenever is Java VM installed the usual location where it gets installed for Java 1.7 on Windows is:
C:Program FilesJavajre7bin
Java 8 common location is:
C:Program FilesJavajre8bin
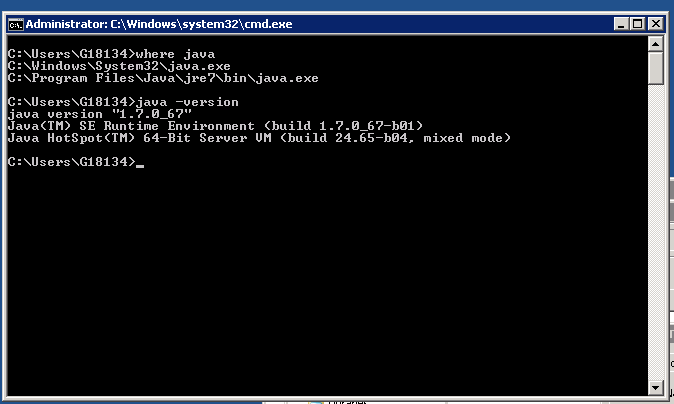
Java would automatically add PATH to Windows default PATH definitions during install, hence to find out exactly where java is installed on Windows server, type in cmd:
where java
Then to check the exact installed Java version on Win host is by invoking java (jre) cli with -version parameter:
java -version
If you're lazy to type in commands, you can also check Java version in Windows from GUI by using:
Have you ever been in need to execute some commands scheduled via a crontab, every let’s say 5 seconds?, naturally this is not possible with crontab, however adding a small shell script to loop and execute a command or commands every 5 seconds and setting it up to execute once in a minute through crontab makes this possible. Here is an example shell script that does execute commands every 5 seconds:
#!/bin/bash command1_to_exec='/bin/ls';
command2_to_exec='/bin/pwd';
for i in $(echo 1 2 3 4 5 6 7 8 9 10 11); do
sleep 5;
$command1_to_exec; $command2_to_exec;
done
This script will issue a sleep every 5 seconds and execute the two commands defined as $command1_to_exec and $command2_to_exec
The script can easily be modified to execute on any seconds interval delay, the record to put on cron to use with this script should look something like:
Where of course /path/to/exec_every_5_secs_cmds.sh needs to be modified to a proper script name and path location.
Another way to do the on a number of seconds program / command schedule without using cron at all is setting up an endless loop to run/refresh via /etc/inittab with a number of predefined commands inside. An example endless loop script to run via inittab would look something like:
while [ 1 ]; do
/bin/ls
sleep 5;
done
To run the above sample never ending script using inittab, one needs to add to the end of inittab, some line like:
mine:234:respawn:/path/to/script_name.sh
A quick way to add the line from consone would be with echo:
Then to load up the newly added inittab line, inittab needs to be reloaded with cmd:
# init q
I've also red, some other methods suggested to run programs on a periodic seconds basis using just cron, what I found in stackoverflow.com's as a thread proposed as a solution is:
so question arises what is which / whereis command Linux commands Windows equivalent?
In older Windows Home / Server editions – e.g. – Windows XP, 2000, 2003 – there is no standard installed tool to show you location of windows %PATH% defined executables. However it is possible to add the WHERE command binary by installing Resource Kit tools for administrative tasks.
In Windows Vista / 7 / 8 (and presumably in future Windows releases),WHERE command is (will be) available by default
Watching videos in youtube today and already for about 2 years is the de-facto hype. There is almost none a day passed without almost each one of us has watched a dozen videos in Youtube.
Watching videos in youtube has become even more addictive for many than the early days of Internet Relay Chats (IRC)
As youtube is very accessible for people and it’s a comparativily easy way people share more and more with the day. There is no question that the business idea of youtube is great and youtube generates millions of dollars for Google day by day, however I have a serious objection here! All is good the only pitfall is that you don’t own the youtube videos you watch!
The good thing here is that we’re not still completely dependant on youtube and there is still way to retrieve your favourite youtube video and store it for later watching or distribution.
Probably the most famous browser plugin that allows files retrieval from youtube, as most people know is DownloadHelper .
However using download helper is browser dependant, you need to use the browser to save the plugin and I don’t find it to be the best way to download a youtube video.
Since the old days I have started using Linux, I’ve been quite addicted to as many things on my linux as possible from the command line (terminal / console)(CLI) .
In that manner of thoughts it was a real delight for me to find out that a group of free software developer guys has come up with a command line tool that allows downloads of youtube videos straight from terminal, the great software is called youtube-dl and at the moment of this post writting it’s to be found on the URL address:
http://rg3.github.com/youtube-dl/
Youtube-dl is written in python so, it requires the Python interpreter, version 2.5 in order to properly run on Unix, Mac OS X or even on Windows!
The fact that it’s written in python has made the little shiny tool quite a multi-platform one. To start using immediately the tool on a Debian or Ubuntu Linux you will have to install python (even though in most cases you must have it already installed):
1. To make sure you have python interpreter installed issue the cmd:
debian:~# apt-get install python
Building dependency tree
Reading state information... Done
python is already the newest version.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
As you can see from above apt-get’s output I do have it installed so nothing gets installed.
2. As a next step I used links to download the youtube-dl python script, like so:
debian:~# links https://github.com/rg3/youtube-dl/raw/2011.03.29/youtube-dl >> youtube-dl Use the links interface to save youtube-dl and use gzip to ungzip it
debian:~# gzip -d youtube-dl.gz
debian:~# chmod +x youtube-dl
Now to make it system wide accessible I have copied the youtube-dl to /usr/local/bin , whether I selected /usr/local/bin as a location as this location is predetermined to contain mostly files which does not belong to a regular deb package.
3. Move youtube-dl to /usr/local/bin
debian:~# mv youtube-dl /usr/local/bin
4. Test the newly installed youtube-dl command line youtube retrieval tool:
debian:~# ./youtube-dl https://www.youtube.com/watch?v=g7tvI6JCXD0
[youtube] Setting language
[youtube] g7tvI6JCXD0: Downloading video webpage
[youtube] g7tvI6JCXD0: Downloading video info webpage
[youtube] g7tvI6JCXD0: Extracting video information
[download] Destination: g7tvI6JCXD0.flv
[download] 53.3% of 22.62M at 33.23k/s ETA 05:25
[download] 100.0% of 22.62M at 31.91k/s ETA 00:00 [u
As you might have noticed from the above youtube-dl command output the newly retrieved youtube file will be saved under a name g7tvI6JCXD0.flv
The line I passed to youtube-dl is directly taken from my browser and pasted to console, the file downloading from youtube took me about 10 minutes but this is mostly because of some kind of youtube server speed restrictions …
In general at least I have this video for later, watching, so after a while I can watch it once again without loosing a lot of time trying to remember what was the video headline name
5. To use youtube-dl in a bit advanced way you can for instance invoke the command with options like:
debian:~# ./youtube-dl -l -w -c https://www.youtube.com/watch?v=g7tvI6JCXD0
[youtube] Setting language
[youtube] g7tvI6JCXD0: Downloading video webpage
[youtube] g7tvI6JCXD0: Downloading video info webpage
[youtube] g7tvI6JCXD0: Extracting video information
[download] Destination: BSD is Dying, Jason Dixon, NYCBSDCon 2007-g7tvI6JCXD0.flv
[download] 4.4% of 22.62M at 1.43M/s ETA 00:15
As you can see now youtube-dl was even able to detect the downloaded video file name and store it on the computer with a correct name 😉
I would recommend you also to check out the youtube-dl help page, to do use command: youtube-dl –help
It is a public secret that Mobile Phones which does us very good and generally makes our daily lifes way easier are also a big enemy to our natural ihnibited freedom. Life has become such that it is almost inevitable to do any business or do a daily simple jobs without using Mobile Phone. There is almost none practically today that has wilfully rejected to use the mobile phone on any basis, almost anyone except some strangers like Richard Stallman and probably few others security freaks.
I've been shocked to find out the Father of Free Software (Richard Mathew Stallman), well known in the hacker dome as RMS does not own and didn't use any mobiles. The concerns he pointed are very much logical and rightful. Owning a mobile is a great security hole in personal privacy (mobile phones can be easily sniffed by Mobile Operators) as well as anyone wearing a mobile can be tracked up to 5 to 2 meters to the exact location where he is based on the mobile phone cells to which the mobile is connected.
Many people are not aware actually of the severeness of the issue of constant tracking of people everywhere through this call "goodies". Many mobile operators are already running a software which is building place behaviour patterns of every user of their mobile network. In other words, as we're used to bring and use the mobile everywhere in automated program is creating a map for each number assigned in some of the mobile operators. The gathered data about our location going habits can then be easily used as a indicator for predicting our future behaviour, bying habits (how many times we go to super-market), how many times we go to cinema, what kind of interests we hold etc. etc. This combined with Google, account monitoring could possibly create a system similar to the old movies Big Brother, where all people goods and even attitudes or desires is monitored, influenced and controlled ….
The severeness of the future implications of this constant "personal surveillance and tracking device" as Stallman use to call it is very dangerous for our freedoms.
I tried to live without a mobile phone, just like Stallman for about months, and to tell you the truth the world around seems completely different when you decide not to use 'em. The time I lived wihtout a mobile, clearly show me we have come to the point we cannot any more live without GSM. We fall the trap of dependanding the little "talk box" communication for absolutely everything, obviously sacrificing privacy and freedom for convenience. Mobiles are just one side of the coin, as the non-free software which is ruling the software market and the use of computers puts another treat and takes away many foundamential freedoms we used to have in the less technological world.
Apple as a vendor of software and hardware also denies and breaks our freedom very badly, as the company tracks everyone who owns anything created by apple connected to the internet. Besides that non-free software producers, could change the user software with a press of a button giving them the opportunity to decide what is good and bad for us, leaving us at a state of a helpless dependable users.
The topic of technological little-by-little enslavement, we're going through nowdays and the denying freedoms, we experience while being convinced by companies that we became more free by each next mambo-jambo gadget or by owning the latest smart-phone is very huge and complex but unfortunately underseen in society. I don't understand why, is it due to the low technical skills of mass users is it due to a "not-care what will happen in future" attitude, but obviously people openly discussing or protesting the technologization taking away our freedom is almost zero ….
Here is the video I found in youtube in which Stallman is asked few, questions on Ipads (IBADS) and Mobile Phone use. I believe his short explanation synthesizes the problem quite well ;;;;
I just wonder after you check the video, Would you still accept an Ipad as a birthday gift ? 🙂 Do you still think cell-phones are "good" freedom safe and reliable ?
Before I explain how netstat and whois commands can be used to check information about a remote skype user – e.g. (skype msg is send or receved) in Skype. I will say in a a few words ( abstract level ), how skype P2P protocol is designed. Many hard core hackers, certainly know how skype operates, so if this is the case just skip the boring few lines of explanation on how skype proto works.
In short skype transfers its message data as most people know in Peer-to-Peer "mode" (P2P) – p2p is unique with this that it doesn't require a a server to transfer data from one peer to another. Most classical use of p2p networks in the free software realm are the bittorrents.
Skype way of connecting to peer client to other peer client is done via a so called "transport points". To make a P-to-P connection skype wents through a number of middle point destinations. This transport points (peers) are actually other users logged in Skype and the data between point A and point B is transferred via this other logged users in encrypted form. If a skype messages has to be transferred from Peer A (point A) to Peer B (Point B) or (the other way around), the data flows in a way similar to:
A -> D -> F -> B
or
B -> F -> D -> A
(where D and F are simply other people running skype on their PCs). The communication from a person A to person B chat in Skype hence, always passes by at least few other IP addresses which are owned by some skype users who happen to be located in the middle geographically between the real geographic location of A (the skype peer sender) and B (The skype peer receiver)..
The exact way skypes communicate is way more complex, this basics however should be enough to grasp the basic skype proto concept for most ppl …
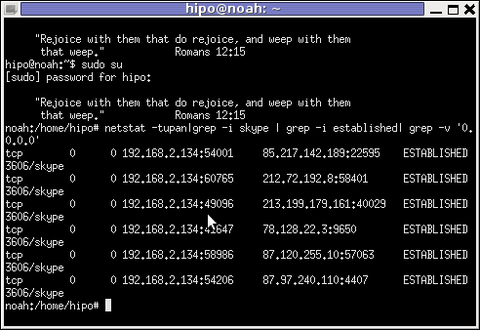
In order to find the IP address to a certain skype contact – one needs to check all ESTABLISHED connections of type skype protocol with netsat within the kernel network stack (connection) queue.
netstat displays few IPs, when skype proto established connections are grepped:
Now, as few IPs are displayed, one needs to find out which exactly from the list of the ESTABLISHED IPs is the the Skype Contact from whom are received or to whom are sent the messages in question.
The blue colored IP address:port is the local IP address of my host running the Skype client. The red one is the IP address of the remote skype host (Skype Name) to which messages are transferred (in the the exact time the netstat command was ran.
The easiest way to find exactly which, from all the listed IP is the IP address of the remote person is to send multiple messages in a low time interval (let's say 10 secs / 10 messages to the remote Skype contact).
It is a hard task to write 10 msgs for 10 seconds and run 10 times a netstat in separate terminal (simultaneously). Therefore it is a good practice instead of trying your reflex, to run a tiny loop to delay 1 sec its execution and run the prior netstat cmd.
To do so open a new terminal window and type:
noah:~# for i in $(seq 1 10); do \
sleep 1; echo '-------'; \
netstat -tupan|grep -i skype | grep -i established| grep -v '0.0.0.0'; \
done
-------
tcp 0 0 192.168.2.134:55119 87.126.71.94:26309 ESTABLISHED 3606/skype
-------
tcp 0 0 192.168.2.134:49096 213.199.179.161:40029 ESTABLISHED 3606/skype
tcp 0 0 192.168.2.134:55119 87.126.71.94:26309 ESTABLISHED 3606/skype
-------
tcp 0 0 192.168.2.134:49096 213.199.179.161:40029 ESTABLISHED 3606/skype
tcp 0 0 192.168.2.134:55119 87.126.71.94:26309 ESTABLISHED 3606/skype
...
You see on the first netstat (sequence) exec, there is only 1 IP address to which a skype connection is established, once I sent some new messages to my remote skype friend, another IP immediatelly appeared. This other IP is actually the IP of the person to whom, I'm sending the "probe" skype messages. Hence, its most likely the skype chat at hand is with a person who has an IP address of the newly appeared 213.199.179.161
Later to get exact information on who owns 213.199.179.161 and administrative contact info as well as address of the ISP or person owning the IP, do a RIPE whois
noah:~# whois 213.199.179.161
% This is the RIPE Database query service.
% The objects are in RPSL format.
%
% The RIPE Database is subject to Terms and Conditions.
% See http://www.ripe.net/db/support/db-terms-conditions.pdf
% Note: this output has been filtered.
% To receive output for a database update, use the "-B" flag.
% Information related to '87.126.0.0 - 87.126.127.255'
inetnum: 87.126.0.0 - 87.126.127.255
netname: BTC-BROADBAND-NET-2
descr: BTC Broadband Service
country: BG
admin-c: LG700-RIPE
tech-c: LG700-RIPE
tech-c: SS4127-RIPE
status: ASSIGNED PA
mnt-by: BT95-ADM
mnt-domains: BT95-ADM
mnt-lower: BT95-ADM
source: RIPE # Filteredperson: Lyubomir Georgiev
.....
Note that this method of finding out the remote Skype Name IP to whom a skype chat is running is not always precise.
If for instance you tend to chat to many people simultaneously in skype, finding the exact IPs of each of the multiple Skype contacts will be a very hard not to say impossible task. Often also by using netstat to capture a Skype Name you're in chat with, there might be plenty of "false positive" IPs.. For instance, Skype might show a remote Skype contact IP correct but still this might not be the IP from which the remote skype user is chatting, as the remote skype side might not have a unique assigned internet IP address but might use his NET connection over a NAT or DMZ.
The remote skype user might be hard or impossible to track also if skype client is run over skype tor proxy for the sake of anonymity Though it can't be taken as granted that the IP address obtained would be 100% correct with the netstat + whois method, in most cases it is enough to give (at least approximate) info on a Country and City origin of the person you're skyping with.
Facebook is usually praised and very seldom criticized. I've seen already on a couple of occasions on the TV channel news on earthquake occasions or some kind of other calamities, where facebook was said to help the rescuing teams etc. We constantly hear how facebook has helped people point their location in disastrous situations or just helping people organize a protest against a harmful company activity. Whilst this might be true, the harms it does are quite big as well. A primary harm it does is to economy as we know it. As people are engaged in filling in Mark Zuckerberg and facebook investors pockets, they rarely think about how actually facebook gets their money?
Let me explain:
Basicly facebook makes money out of its constantly increased social network data content. This could have not been possible without the 800 000 000+ million of people who constantly post updates on facebook, create groups, post pictures, add likes, comment and post links to other facebook pages. If people had not all this volunteers (facebook users) to post all this bunch of mostly junky information, facebook inc. would not have a penny. Therefore what makes facebook grow is the people itself who willingly choose to be part of this money making machine. One would think with regular company the investors are the owners of the company shares. This classical business model is not facebook model, there it is rather different as the real investors in facebook are not the capital shareholders but the regular social network user base – this means (you and me)!.
For all those who still don't get what I'm talking about I will shortly explain. Everyone who has a basic idea on how internet advertising works is aware that the primary origin for facebook todays profit is the left pane sky scraper field with ever changing advertisements.
Various advertisers pays facebook all the time big money for displaying those stupid advertisement. As many peole are viewing and clicking the advertisements, facebook makes billions out if its advertisers.
So far so good, facebook generates its profits out of peoples free time and delibarately information sharing you would say and you might argue me that facebook steals people (time / money). This would have been true if you don't put in the picture for a contrast, a regular blogger, who makes its daily living out of blogging. What a regular blogger does is frequent blogging on various kind of topics of his interest. Various bloggers blog at various titles, but most of them has a few major topics which they're following.
The more articles a blogger collects and the higher the uniqueness of this information is the bigger the probability this blog to have a good users base and the more interesting content it will have for search engine robots like Google Bot Crawlers or Yahoo Bot etc. etc. With all priod said, the higher the probability this blog to have more traffic drawn from web searches to the blog. As the blogger content increases with time when it gets 10000 or more unique articles (pages), consequently it can be used as an advertising place. A 10000 pages blog could earn a person a few hundred of euros (200, 300 EUR) per month.
Well the business scheme behind facebook is exactly the same, except they store and physically own the data of the facebook registered persons. The user posts content on his facebook wall, makes pages or does various activities which generate pages, the content gets indexed in Google and with time the overall facebook website content grows. As new users joins facebook with the increased popularity of website. The website is growing exponentially like in a atoms chain reaction.
Because of this steady content growth, it becomes an interesting place not only for advertisers but for all kind of people that use the internet. And there you have the monetarization facebook makes billions of dollars every second because of you. This is the shocking truth, they get their money because people click or view advertisement on each others profile, so there you're YOU make the little people who develop facebook and the original investors richer and richer with every day, where you make yourself poorer and poorer by investing your personal time in facebook instead of using it to work on something that will potentially generate you some dividents in short or long future.
Actually social network is nothing more than just a multiple blogging platform, but some marketing person come with this marketing hype work "social network". The social network buzz word is in my view just another big marketing "white lie"!. Correct me if i'm wrong but what in fact is a "Social network?". I don't see facebook neither as social, network as network. I don't know about you but I have never made a long lasting friend or relationship using facebook so far. I think the poor Facebook creator Zuckerberg made facebook with a viral mindset. He intended it to be like a social virus and so far he succeed pretty much. I just wait and eager to see who will start the anti-virus for Zuckerberg's (facebook) – people time eating virus.
Substitute the /var/www/yourwebsite with your correct website location in between the opening and closing Directory apache directive place something similar to the following lines:
AllowOverride All AuthName “Add your login message here.” AuthType Basic AuthUserFile /etc/apache2/.htpasswd AuthGroupFile /dev/null require user name-of-user
Eventually your Directory directive in your let’s say /etc/apache2/apache2.conf should look something like the example in below
<Directory /var/www/yourwebsite>
AllowOverride All
AuthName "Add your login message here."
AuthType Basic
AuthUserFile /etc/apache2/.htpasswd
AuthGroupFile /dev/null
require user name-of-user
</Directory>
Of course in this example you need to set the name-of-user to an actual user name let’s say you want your login user to be admin, then substitute the name-of-user with admin
Of course set the desirable location for your .htpasswd in the AuthUserFile. Just in case if you decide to keep the same location as in my example you will further need to create the /etc/apache2/.htpasswd file.
Note here that in the above exapmle the AllowOverride All could also be substituted for AllowOverride AuthConfig , you might need to put this one if you don’t want that all .htaccess directives are recognized by Apache.
To create the .htpasswd issue the command:
debian~:# htpasswd -c /etc/apache2/.htpasswd admin
New password:
Re-type new password:
In the passwords prompts just type in your password of choice. Now we’re almost ready to have the website apache authentication working, only thing left is to reastart Apache. I’m using Debian so restarting my apache is done via:
debian:~# /etc/init.d/apache2 restart
In other Linux distributions exec the respective script for Apache restart.
Now access your website and the password protection dialog asking for your credentials to login should popup.