Posts Tagged ‘Engine’
Thursday, April 2nd, 2015 
If you're a webhosting company hosting dozens of various websites that use MySQL with InnoDB engine as a backend you've probably already experienced the annoying problem of MySQL's ibdata1 growing too large / eating all server's disk space and triggering disk space low alerts. The ibdata1 file, taking up hundreds of gigabytes is likely to be encountered on virtually all Linux distributions which run default MySQL server <= MySQL 5.6 (with default distro shipped my.cnf). The excremental ibdata1 raise appears usually due to a application software bug on how it queries the database. In theory there are no limitation for ibdata1 except maximum file size limitation set for the filesystem (and there is no limitation option set in my.cnf) meaning it is quite possible that under certain conditions ibdata1 grow over time can happily fill up your server LVM (Storage) drive partitions.
Unfortunately there is no way to shrink the ibdata1 file and only known work around (I found) is to set innodb_file_per_table option in my.cnf to force the MySQL server create separate *.ibd files under datadir (my.cnf variable) for each freshly created InnoDB table.
1. Checking size of ibdata1 file
On Debian / Ubuntu and other deb based Linux servers datadir is /var/lib/mysql/ibdata1
server:~# du -hsc /var/lib/mysql/ibdata1
45G /var/lib/mysql/ibdata1
45G total
2. Checking info about Databases and Innodb storage Engine
server:~# mysql -u root -p
password:
mysql> SHOW DATABASES;
+——————–+
| Database |
+——————–+
| information_schema |
| bible |
| blog |
| blog-sezoni |
| blogmonastery |
| daniel |
| ezmlm |
| flash-games |
Next step is to get some understanding about how many existing InnoDB tables are present within Database server:
mysql> SELECT COUNT(1) EngineCount,engine FROM information_schema.tables WHERE table_schema NOT IN ('information_schema','performance_schema','mysql') GROUP BY engine;
+————-+——–+
| EngineCount | engine |
+————-+——–+
| 131 | InnoDB |
| 5 | MEMORY |
| 584 | MyISAM |
+————-+——–+
3 rows in set (0.02 sec)
To get some more statistics related to InnoDb variables set on the SQL server:
mysqladmin -u root -p'Your-Server-Password' var | grep innodb
Here is also how to find which tables use InnoDb Engine
mysql> SELECT table_schema, table_name
-> FROM INFORMATION_SCHEMA.TABLES
-> WHERE engine = 'innodb';
+————–+————————–+
| table_schema | table_name |
+————–+————————–+
| blog | wp_blc_filters |
| blog | wp_blc_instances |
| blog | wp_blc_links |
| blog | wp_blc_synch |
| blog | wp_likes |
| blog | wp_wpx_logs |
| blog-sezoni | wp_likes |
| icanga_web | cronk |
| icanga_web | cronk_category |
| icanga_web | cronk_category_cronk |
| icanga_web | cronk_principal_category |
| icanga_web | cronk_principal_cronk |
…
3. Check and Stop any Web / Mail / DNS service using MySQL
server:~# ps -efl |grep -E 'apache|nginx|dovecot|bind|radius|postfix'
…
Below cmd should return empty output, (e.g. Apache / Nginx / Postfix / Radius / Dovecot / DNS etc. services are properly stopped on server).
4. Create Backup dump all MySQL tables with mysqldump
Next step is to create full backup dump of all current MySQL databases (with mysqladmin):
server:~# mysqldump –opt –allow-keywords –add-drop-table –all-databases –events -u root -p > dump.sql
server:~# du -hsc /root/dump.sql
940M dump.sql
940M total
If you have free space on an external backup server or remotely mounted attached (NFS or SAN Storage) it is a good idea to make a full binary copy of MySQL data (just in case something wents wrong with above binary dump), copy respective directory depending on the Linux distro and install location of SQL binary files set (in my.cnf).
To check where are MySQL binary stored database data (check in my.cnf):
server:~# grep -i datadir /etc/mysql/my.cnf
datadir = /var/lib/mysql
If server is CentOS / RHEL Fedora RPM based substitute in above grep cmd line /etc/mysql/my.cnf with /etc/my.cnf
if you're on Debian / Ubuntu:
server:~# /etc/init.d/mysql stop
server:~# cp -rpfv /var/lib/mysql /root/mysql-data-backup
Once above copy completes, DROP all all databases except, mysql, information_schema (which store MySQL existing user / passwords and Access Grants and Host Permissions)
5. Drop All databases except mysql and information_schema
server:~# mysql -u root -p
password:
mysql> SHOW DATABASES;
…
DROP DATABASE blog;
DROP DATABASE sessions;
DROP DATABASE wordpress;
DROP DATABASE micropcfreak;
DROP DATABASE statusnet;
…
etc. etc.
ACHTUNG !!! DON'T execute! – DROP database mysql; DROP database information_schema; !!! – cause this might damage your User permissions to databases
6. Stop MySQL server and add innodb_file_per_table and few more settings to prevent ibdata1 to grow infinitely in future
server:~# /etc/init.d/mysql stop
server:~# vim /etc/mysql/my.cnf
[mysqld]
innodb_file_per_table
innodb_flush_method=O_DIRECT
innodb_log_file_size=1G
innodb_buffer_pool_size=4G
Delete files taking up too much space – ibdata1 ib_logfile0 and ib_logfile1
server:~# cd /var/lib/mysql/
server:~# rm -f ibdata1 ib_logfile0 ib_logfile1
server:~# /etc/init.d/mysql start
server:~# /etc/init.d/mysql stop
server:~# /etc/init.d/mysql start
server:~# ps ax |grep -i mysql
…
You should get no running MySQL instance (processes), so above ps command should return blank.
7. Re-Import previously dumped SQL databases with mysql cli client
server:~# cd /root/
server:~# mysql -u root -p < dump.sql
Hopefully import should went fine, and if no errors experienced new data should be in.
Altearnatively if your database is too big and you want to import it in less time to mitigate SQL downtime, instead import the database with:
server:~# mysql -u root -p
password:
mysql> SET FOREIGN_KEY_CHECKS=0;
mysql> SOURCE /root/dump.sql;
mysql> SET FOREIGN_KEY_CHECKS=1;
…
If something goes wrong with the import for some reason, you can always copy over sql binary files from /root/mysql-data-backup/ to /var/lib/mysql/
8. Connect to mysql and check whether databases are listable and re-check ibdata file size
Once imported login with mysql cli and check whther databases are there with:
server:~# mysql -u root -p
SHOW DATABASES;
Next lets see what is currently the size of ibdata1, ib_logfile0 and ib_logfile1
server:~# du -hsc /var/lib/mysql/{ibdata1,ib_logfile0,ib_logfile1}
19M /var/lib/mysql/ibdata1
1,1G /var/lib/mysql/ib_logfile0
1,1G /var/lib/mysql/ib_logfile1
2,1G total
Now ibdata1 will grow, but only contain table metadata. Each InnoDB table will exist outside of ibdata1.
To better understand what I mean, lets say you have InnoDB table named blogdb.mytable.
If you go into /var/lib/mysql/blogdb, you will see two files
representing the table:
- mytable.frm (Storage Engine Header)
- mytable.ibd (Home of Table Data and Table Indexes for blogdb.mytable)
Now construction will be like that for each of MySQL stored databases instead of everything to go to ibdata1.
MySQL 5.6+ admins could relax as innodb_file_per_table is enabled by default in newer SQL releases.
Now to make sure your websites are working take few of the hosted websites URLs that use any of the imported databases and just browse.
In my case ibdata1 was 45GB after clearing it up I managed to save 43 GB of disk space!!!
Enjoy the disk saving! 🙂
Tags: blog, case, check, checking, cli, client, cmd line, cnf, com, company, Connect, copy, databases, Delete, disk space, Engine, Enjoy, enormous ibdata1, file, filesystem, fix, fix ibdata size, future, ibdata, ibdata1 fill disk space, init, lib, mysqladmin, net, passwords, reduce ibdata, server, size, stackoverflow, too large, var, www
Posted in Everyday Life, MySQL, System Administration, Web and CMS | 2 Comments »
Wednesday, February 26th, 2014 
Having a combination of Apache webservice Reverse Proxy to redirect invisibly traffic to a number of Tomcat server positioned in a DMZ is a classic task in big companies Corporate world.
Hence if you work for company like IBM or HP sooner or later you will need to configure Apache Webserver cluster with few running Jakarta Tomcat Application servers behind. Scenario with necessity to access a java based application via Tomcat which requires logging (authentication) relaying on establishing and keeping a session ID is probably one of the most common ones and if you do it for first time you will probably end up with Session ID issues. Session ID issues are hard to capture at first as on first glimpse application will seem to be working but users will have to re-login all the time even though the programmers might have coded for a session to expiry in 30 minutes or so.
… I mean not having configured Session ID prevention to Tomcats will cause random authentication session expiries and users using the Tomcat app will be unable to normally access below application with authenticated credentials. The solution to these is known under term "Sticky sessions"
To configure Sticky sessions you need to already have configured Apache/s with following minimum configuration:
- enabled mod_proxy, proxy_balancer_module, proxy_http_module and or mod_proxy_ajp (in Apache config)
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
LoadModule proxy_http_module modules/mod_proxy_http.so
- And configured and tested Tomcats running an Application reachable via AJP protocol
Below example assumes there is Reverse Proxy Load Balancer Apache which has to forward all traffic to 2 tomcats. The config can easily be extended for as many as necessary by adding more BalancerMembers.
In Apache webserver (apache2.conf / httpd.conf) you need to have JSESSIONID configured. These JSESSIONID is going to be appended to each client request from Reverse Proxy to each of Tomcat servers with value opened once on authentication to first Tomcat node to each of the other ones.
<Proxy balancer://mycluster>
BalancerMember ajp://10.16.166.53:11010/ route=delivery1
BalancerMember ajp://10.16.166.66:11010/ route=delivery2
</Proxy>
ProxyRequests Off
ProxyPass / balancer://mycluster/ stickysession=JSESSIONID
ProxyPassReverse / balancer://mycluster/
The two variables route=delivery1 and route=delivery2 are routed to hosts identificators that also has to be present in Tomcat server configurations
In Tomcat App server First Node (server.xml)
<Engine name="Catalina" defaultHost="localhost" jvmRoute="delivery1">
In Tomcat App server Second Node (server.xml)
<Engine name="Catalina" defaultHost="localhost" jvmRoute="delivery2">
Once Sticky Sessions are configured it is useful to be able to track they work fine this is possible through logging each of established JESSSIONIDs, to do so add in httpd.conf
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"\"%{JSESSIONID}C\"" combined
After modifications restart Apache and Tomcat to load new configs. In Apache access.log the proof should be the proof that sessions are preserved via JSESSIONID, there should be logs like:
127.0.0.1 - - [18/Sep/2013:10:02:02 +0800] "POST /examples/servlets/servlet/RequestParamExample HTTP/1.1" 200 662 "http://localhost/examples/servlets/servlet/RequestParamExample" "Mozilla/5.0 (X11; Linux x86_64; rv:17.0) Gecko/20130807 Firefox/17.0""B80557A1D9B48EC1D73CF8C7482B7D46.server2"
127.0.0.1 - - [18/Sep/2013:10:02:06 +0800] "GET /examples/servlets/servlet/RequestInfoExample HTTP/1.1" 200 693 "http://localhost/examples/servlets/" "Mozilla/5.0 (X11; Linux x86_64; rv:17.0) Gecko/20130807 Firefox/17.0""B80557A1D9B48EC1D73CF8C7482B7D46.server2"
That should solve problems with mysterious session expiries 🙂
Tags: AJP, apache webserver, apache2, application, authentication, combination, conf, configured, DMZ, Engine, First Node, hp, httpd, ID, Jakarta Tomcat Application, JESSIONID, JSESSIONID, localhost, need, number, proof, proxy, request, Reverse Proxy, Reverse Proxy Load Balancer Apache, run, Second Node, server, session, working, xml
Posted in Linux, System Administration, Various | 2 Comments »
Tuesday, March 6th, 2012 
Facebook is usually praised and very seldom criticized. I've seen already on a couple of occasions on the TV channel news on earthquake occasions or some kind of other calamities, where facebook was said to help the rescuing teams etc. We constantly hear how facebook has helped people point their location in disastrous situations or just helping people organize a protest against a harmful company activity. Whilst this might be true, the harms it does are quite big as well. A primary harm it does is to economy as we know it. As people are engaged in filling in Mark Zuckerberg and facebook investors pockets, they rarely think about how actually facebook gets their money?
Let me explain:
Basicly facebook makes money out of its constantly increased social network data content. This could have not been possible without the 800 000 000+ million of people who constantly post updates on facebook, create groups, post pictures, add likes, comment and post links to other facebook pages. If people had not all this volunteers (facebook users) to post all this bunch of mostly junky information, facebook inc. would not have a penny. Therefore what makes facebook grow is the people itself who willingly choose to be part of this money making machine. One would think with regular company the investors are the owners of the company shares. This classical business model is not facebook model, there it is rather different as the real investors in facebook are not the capital shareholders but the regular social network user base – this means (you and me)!.
For all those who still don't get what I'm talking about I will shortly explain.
Everyone who has a basic idea on how internet advertising works is aware that the primary origin for facebook todays profit is the left pane sky scraper field with ever changing advertisements.
Various advertisers pays facebook all the time big money for displaying those stupid advertisement. As many peole are viewing and clicking the advertisements, facebook makes billions out if its advertisers.
So far so good, facebook generates its profits out of peoples free time and delibarately information sharing you would say and you might argue me that facebook steals people (time / money). This would have been true if you don't put in the picture for a contrast, a regular blogger, who makes its daily living out of blogging.
What a regular blogger does is frequent blogging on various kind of topics of his interest. Various bloggers blog at various titles, but most of them has a few major topics which they're following.
The more articles a blogger collects and the higher the uniqueness of this information is the bigger the probability this blog to have a good users base and the more interesting content it will have for search engine robots like Google Bot Crawlers or Yahoo Bot etc. etc.
With all priod said, the higher the probability this blog to have more traffic drawn from web searches to the blog. As the blogger content increases with time when it gets 10000 or more unique articles (pages), consequently it can be used as an advertising place. A 10000 pages blog could earn a person a few hundred of euros (200, 300 EUR) per month.
Well the business scheme behind facebook is exactly the same, except they store and physically own the data of the facebook registered persons. The user posts content on his facebook wall, makes pages or does various activities which generate pages, the content gets indexed in Google and with time the overall facebook website content grows. As new users joins facebook with the increased popularity of website. The website is growing exponentially like in a atoms chain reaction.
Because of this steady content growth, it becomes an interesting place not only for advertisers but for all kind of people that use the internet.
And there you have the monetarization facebook makes billions of dollars every second because of you. This is the shocking truth, they get their money because people click or view advertisement on each others profile, so there you're YOU make the little people who develop facebook and the original investors richer and richer with every day, where you make yourself poorer and poorer by investing your personal time in facebook instead of using it to work on something that will potentially generate you some dividents in short or long future.
Actually social network is nothing more than just a multiple blogging platform, but some marketing person come with this marketing hype work "social network".
The social network buzz word is in my view just another big marketing "white lie"!. Correct me if i'm wrong but what in fact is a "Social network?". I don't see facebook neither as social, network as network. I don't know about you but I have never made a long lasting friend or relationship using facebook so far. I think the poor Facebook creator Zuckerberg made facebook with a viral mindset. He intended it to be like a social virus and so far he succeed pretty much. I just wait and eager to see who will start the anti-virus for Zuckerberg's (facebook) – people time eating virus.
Tags: advertisements, advertisers, advertising works, Auto, billions, blogger, business model, calamities, capital, channel news, company shares, content, contrast, data content, disastrous situations, Draft, earthquake, economy, Engine, everyone, facebook, information, interest, internet advertising, junky, left pane, location, machine, mark zuckerberg, network content, occasions, peole, person, picture, place, pockets, profits, Search, shareholders, sky, sky scraper, time, tv channel, volunteers
Posted in Business Management, Entertainment, Everyday Life, Various | No Comments »
Sunday, February 12th, 2012 
Lately I've been researching on ntpd and wrote a two articles on how to install ntpd on CentOS, Fedora and how to install ntpd on FreeBSD and during my research on ntpd, I've come across OpenNTPD and decided to give it a go on my FreeBSD home router.
OpenBSD project is well known for it is high security standards and historically has passed the test of time for being a extraordinary secure UNIX like free operating system.
OpenBSD is developed in parallel with FreeBSD, however the development model of the two free operating systems are way different.
As a part of the OpenBSD to be independant in its basis of software from other free operating systems like GNU / Linux and FreeBSD. They develop the all around free software realm known OpenSSH. Along with OpenSSH, one interesting project developed for the main purpose of OpenBSD is OpenNTPD.
Here is how openntpd.org describes OpenNTPD:
"a FREE, easy to use implementation of the Network Time Protocol. It provides the ability to sync the local clock to remote NTP servers and can act as NTP server itself, redistributing the local clock."
OpenNTPD's accent just like OpenBSD's accent is security and hence for FreeBSD installs which targets security openntpd might be a good choice. Besides that the so popular classical ntpd has been well known for being historically "insecure", remote exploits for it has been released already at numerous times.
Another reason for someone to choose run openntpd instead of ntpd is its great simplicity. openntpd configuration is super simple.
Here are the steps I followed to have openntpd time server synchronize clock on my system using other public accessible openntpd servers on the internet.
1. Install openntpd through pkg_add -vr openntpd or via ports tree
a) For binar install with pkg_add issue:
freebsd# pkg_add -vr openntpd
...
b) if you prefer to compile it from source
freebsd# cd /usr/ports/net/openntpd
freebsd# make install clean
...
2. Enable OpenNTPD to start on system boot:
freebsd# echo 'openntpd_enable="YES"' >> /etc/rc.conf
3. Create openntpd ntpd.conf configuration file
There is a default sample ntpd.conf configuration which can be straight use as a conf basis:
freebsd# cp -rpf /usr/local/share/examples/openntpd/ntpd.conf /usr/local/etc/ntpd.conf
Default ntpd.conf works just fine without any modifications, if however there is a requirement the openntpd server to listen and accept time synchronization requests from only certain hosts add to conf something like:
listen on 192.168.1.2
listen on 192.168.1.3
listen on 2607:f0d0:3001:0009:0000:0000:0000:0001
listen on 127.0.0.1
This configuration will enable only 192.168.1.2 and 192.168.1.3 IPv4 addresses as well as the IPv6 2607:f0d0:3001:0009:0000:0000:0000:0001 IP to communicate with openntpd.
4. Start OpenNTPD service
freebsd# /usr/local/etc/rc.d/openntpd
5. Verify if openntpd is up and running
freebsd# ps axuww|grep -i ntp
root 31695 0.0 0.1 3188 1060 ?? Ss 11:26PM 0:00.00 ntpd: [priv] (ntpd)
_ntp 31696 0.0 0.1 3188 1140 ?? S 11:26PM 0:00.00 ntpd: ntp engine (ntpd)
_ntp 31697 0.0 0.1 3188 1088 ?? S 11:26PM 0:00.00 ntpd: dns engine (ntpd)
root 31700 0.0 0.1 3336 1192 p2 S+ 11:26PM 0:00.00 grep -i ntp
Its also good idea to check if openntpd has succesfully established connection with its peer remote openntpd time servers. This is necessery to make sure pf / ipfw firewall rules are not preventing connection to remote 123 UDP port:
freebsd# sockstat -4 -p 123
USER COMMAND PID FD PROTO LOCAL ADDRESS FOREIGN ADDRESS
_ntp ntpd 31696 4 udp4 83.228.93.76:54555 212.70.148.15:123
_ntp ntpd 31696 6 udp4 83.228.93.76:56666 195.69.120.36:123
_ntp ntpd 31696 8 udp4 83.228.93.76:49976 217.75.140.188:123
By default openntpd is also listening to IPv6 if IPv6 support is enabled in freebsd kernel.
6. Resolve openntpd firewall filtering issues
If there is a pf firewall blocking UDP requests to in/out port 123 within /etc/pf.conf rule like:
block in log on $EXT_NIC proto udp all
Before the blocking rule you will have to add pf rules:
# Ipv4 Open outgoing port TCP 123 (NTP)
pass out on $EXT_NIC proto tcp to any port ntp
# Ipv6 Open outgoing port TCP 123 (NTP)
pass out on $EXT_NIC inet6 proto tcp to any port ntp
# Ipv4 Open outgoing port UDP 123 (NTP)
pass out on $EXT_NIC proto udp to any port ntp
# Ipv6 Open outgoing port UDP 123 (NTP)
pass out on $EXT_NIC inet6 proto udp to any port ntp
where $EXT_NIC is defined to be equal to the external lan NIC interface, for example:
EXT_NIC="ml0"
Afterwards to load the new pf.conf rules firewall has to be flushed and reloaded:
freebsd# /sbin/pfctl -f /etc/pf.conf -d
...
freebsd# /sbin/pfctl -f /etc/pf.conf -e
...
In conclusion openntpd should be more secure than regular ntpd and in many cases is probably a better choice.
Anyhow bear in mind on FreeBSD openntpd is not part of the freebsd world and therefore security updates will not be issued directly by the freebsd dev team, but you will have to regularly update with the latest version provided from the bsd ports to make sure openntpd is 100% secure.
For anyone looking for more precise system clock synchronization and not so focused on security ntpd might be still a better choice. The OpenNTPD's official page states it is designed to reach reasonable time accuracy, but is not after the last microseconds.
Tags: Auto, basis, better security, CentOS, connection, development model, Draft, Engine, exploits, fedora, Free, free operating system, free operating systems, freebsd, GNU, gnu linux, high security, Linux, network time protocol, ntp server, ntp servers, ntpd, Open, OpenBSD, OpenNTPD, pkg, ports, project, Protocol, quot, realm, reason, root, secure unix, security standards, simplicity, software, system, system clock, test, test of time, time, time server
Posted in FreeBSD, System Administration | No Comments »
Monday, January 30th, 2012 Kraptor is another Raptor Shadow of Death free software, open source clone arcade game for GNU/Linux, DOS and Windows (98, XP etc.).

The game is not under active development anymore since 2004. Kraptor features a powerful engine for creating quickly 2D shooter games, so the game should be a good learning curve for people interested into creation of arcade game shooter games.
The game just like Rafkill is built upon DUMB sound engine.
The game intro is quite entertaining 😉 The intro plays one by one the text:
Near Future:
Blobalization
Imperalizm
Corporations
Megalomaniacs
Money and Power. Slaves of the New Millenium!

After years of oppression, the slaved people of the world have raised against their masters. You, has a mercenary pilot, has been
contacted by the popular rebellion to fight against the forces of oppression.
In the morning, you jump into your cockpit and start up the engines. It's time to get airborne and start the attack. Get ready to
scramble the scum hired by the masters. Murder for freedom is the only way, you're on a mission, don't defraud us...
Like Rafkill, Kraptor is one man masterpiece created by a free software Argentinean geek known under the Kronoman artistic pseudonim. The game is really incredible for a one man work … a true masterpiece.
The game is licensed under MIT License.
Even though Kraptor is older game than Rafkill, the design is more resembling the original Raptor game. The game music is high quality stereo. Besides that music and fx sound effects are quite awesome. After each level you have a Raptor like weapons "blackmarket", where you can buy new weapons, recharge ship energy, upgrade ship etc.
The blackmarket implementation part of the game is probably the worst moment in the game along with the game menus (in my view).
Talking about graphics Kraptor supports really high number of resolutions ranging from 320×240 to 1280×1024! 640×480 is the standard resolution in which the game is running.

Something I really like in the game is the number of multiple weapons your ship uses during play. Even if played in Easy mode it is taught.
There are game Saves after each level, so thanksfully you don't have to start again from zero once death.
At the end of each level there is a huge bad BOSS you have to destroy ;).

Installing Kraptor on Debian / Ubuntu and deb derivatives is with:
debian:~# apt-get install kraptor
On most rpm based Linux distributions, you can install the game by converting the deb package to rpm with alien or by building from source from Kraptor's sourceforge page
Its interesting the game name e.g. Kraptor is also a death / grind metal band name, (Maybe Kronoman is metalhead big fan of Kraptor and that's how he came up with the playful name. For all the old school game addicts there is the joystick support. I've tested it with my Genius analogous joystick and it works fine.
The game is lacking .desktop gnome definition and after once installed it only appears through Debian (section) GNOME menus and not in Applications -> Games :
Applications -> Debian -> Games -&act; Action -&t; Kraptor
Just like Rafkill on Debian the game exacutable binary is located in /usr/games/kraptor . Also like with the Rafkill case when launched the game has troubles with choppy sound and music caused by the stupid buggy! pulseaudio
Analogously like with Rafkill's case, the work around to the problematic music en sound is to use a little bash shell script like:
#!/bin/bash
pulseaudio -k;
/usr/games/kraptor
pulseaudio --start;
You can dowload Kraptor fix sound issues wrapper here
To install it on your Debian / Ubuntu and hence make the game sound play good issue with root:
debian:~# cd /usr/bin
debian:/usr/bin# wget https://www.pc-freak.net/bshscr/kraptor.wrapper.sh
...
debian:/usr/bin:# chmod +x kraptor.wrapper.sh
debian:/usr/bin:# mv kraptor.wrapper.sh kraptor
Tags: active development, arcade game, Argentinean, Auto, clone, Corporations, curve, Draft, Engine, freedom, game menus, game music, geek, gnu linux, joystick, Kronoman, learning curve, level, Linux, linux dos, man work, Megalomaniacs, money and power, new millenium, number, oppression, plays one, power, pseudonim, pulseaudio, quality stereo, quot, raptor game, raptor shadow, rpm, scum, shadow, shadow of death, shooter, shooter games, software, software open source, text, time, true masterpiece, Ubuntu, work, wrapper
Posted in Games Linux, Linux, Linux and FreeBSD Desktop | No Comments »
Saturday, January 28th, 2012 I've earlier blogged on playing Apogee's Raptor Shadows of Death arcade on GNU / Linux with dosbox
All the old school raptor addicts will be interested to hear Kazzmir (Jon Rafkind) a free software devotee developer has created a small game resembling many aspects of the original Raptor arcade game.
The game is called Rafkill and is aimed to be a sort of Raptor like fork/clone.
Originally the game was also named Raptor like the DOS game, however in year 2006 it was changed to current Rafkill in order to avoid legal issues with Apogee's Raptor.
The game is not anymore in active development, the latest Rafkill release is from January 2007, anyhow even for the 2012 it is pretty entertaining. The sound and music are on a good level for a Linux / BSD shoot'em'up free software game . The graphics are not of a top quality and are too childish, but this is normal, since the game is just one man masterpiece.

Rafkill is developed in C/C++ programming language, the game music engine it uses is called DUMB (Dynamic Universal Bibliotheque). By the way DUMB library is used for music engine in many Linux arcade games. DUMB allows the Linux game developer to develop his game and play a music files within different game levels in "tracked" formats like mod, s3m, xm etc.
The game is available in compiled form for almost all existent GNU/Linux distributions, as well as one can easily port it as it is open source.
To install Rafkill on Debian, Ubuntu, Xubuntu and Linux Mint en other Debian based distros
root@debian:~# apt-get install rafkill
Installing on Fedora and other rpm based is with yum
debian:~# apt-get install rafkill
...
Once rafkill is installed, in order to start it on Debian the only way is using the rafkill (/usr/bin/rafkill) command. It appears the deb package maintainer did not wrote a gnome launcher file like for example /usr/share/applications/rafkill.desktop
Just to explain for all the GNOME noobs, the .desktop files are a description file GNOME reads in order to understand where exactly to place certain application in the (Gnome Applications, Places, System …) menu panel.
Even though it miss the .desktop, it is launchable via Applications menu under the Debian section e.g. to open it from the GNOME menus you will have to navigate to:
Applications -> Debian -> Games -> Action -> Rafkill
This "shortcut" to launch the game is quite long and hard to remember thus it is handy to directly launch it via xterm:
hipo@debian:~$ rafkill

or by pressing ALT+F2 and typing rafkill :

Starting the game I got some really ugly choppy music / sound issues.
My guess was the fizzling sounds were caused by some bug with the sound portions streamed through pulseaudio sound system.
To test if my presume is correct, stopped pulseaudio and launched rafkill once again:
hipo@debian:~$ pulseaudio -k
hipo@debian:~$ rafkill
This way the game was counting on ALSA to process sound en the sound was playing perfectly fine.
I solved this problem through small wrapper shell script. The script did kill pulseaudio before launching rafkill and that way solve gchoppy sound issues, once the game execution is over the script starts pulseaudio again in order to prevent all other applications working with pulseaudio.
Finally, I've placed the executable script in /usr/bin/rafkill :
Here is the script:
#!/bin/bash
pulseaudio --kill
/usr/games/rafkill
pulseaudio --start
You can download rafkill.wrapper.sh here
Or write in root terminal:
debian:~# cd /usr/bin
debian:/usr/bin:# wget https://www.pc-freak.net/bshscr/rafkill.wrapper.sh
debian:/usr/bin:# mv https://www.pc-freak.net/bshscr/rafkill.wrapper.sh rafkill
debian:/usr/bin:# chmod +x rafkill
Interesting in Ubuntu Linux, rafkill music is okay and I suppose the bug is also solved in newer Linux distributions based on Ubuntu. Probably the Debian Squeeze pulseaudio (0.9.21-4) package version has a bug or smth..
After the change the game music will be playing fine and the game experience is cooler. The game is hard to play. Its really nice the game has game Saves, so once you die you don't have to start from level 1.
I've seen rafkill rolling around on freebsd.org ftps under the ubuntu packages pool, which means rafkill could probably be played easily on FreeBSD and other BSDs.
Enjoy the cool game 😉
Tags: active development, arcade game, arcade games, Auto, BSD, c c programming language, c programming language, clone, deb package, Desktop, desktop files, different game, dos game, Draft, Engine, file, form, Free, game developer, game levels, game music, Gnome, hipo, level, Linux, linux distributions, linux game, menu, mod, music engine, Open, open source clone, package, package maintainer, pulseaudio, quot, script, shadows of death, share applications, small game, software, software game, software open source, Ubuntu, Universal, wrapper, year
Posted in Games Linux, Linux, Linux and FreeBSD Desktop | 1 Comment »
Tuesday, December 13th, 2011 
Facebook and Youtube has become for just a few years a defacto standard service for 80% of computer users in our age.
This is true and it seems there is growing tendency for people to adopt new easy to use services and a boom in the social networks.
We’ve seen that with the fast adoption of the anti-human freedom program Skype , the own privacy breaching FaceBook as well as the people interests tracking service YouTube.
We’ve seen similar high adoption rates in earlier times as well with the already dying (if not dead MySpace), with the early yahoo mail boom etc and in even earlier times with the AltaVista search engine use.
However this time it appears Youtube and FaceBook are here to stay with us and become standard online services for longer times …
Many people who work in office all day staring in a computer screen as well as growing teenagers and practically anyone in the developed and the development world is using those services heavily for (in between 5 to 10 hours a day or more). The Software as a Service users spends approximately half of their time spend on the internet in Youtube or and Facebook.
Its true Youtube can be massively educative with this global database of videos on all kind of topics and in some cases facebook can be considered helpful in keeping in touch people or keeping a catalog of pictures easily accessible from everywhere, however when few services becomes more used and influential than other provided services on the internet this makes these services harmful to the communities and destroyes cultures. The concentration of most of the human popuplation who uses high technologies around few online services creates a big electronic monopoly. In other words the tendency, we see of amalgamation of businesses in real world (building of big malls and destroyment of small and middle sized shops is being observed in the Internet space.
Besides that Facebook and Youtube and Twitter are highly contrary to the true hacker spirit and creates a big harm for intellectuals and other kind of tight and technical community culture by creating one imaginative casual disco culture without any deepness of thought or spirit.
Its observable that most of the people that are heavily using those services are turning into (if not exaggerate) a brainless consumer zombies, a crowd of pathless people who watch videos and pictures and write meaningless commentaries all day long.
You have as a result a “unified dumbness” (dumbness which unifies people).
Even if we can accept the grown and fully formed character people are aware of the threats of using Youtube or Facebook, this is definitely not the case with the growing people which are still in a process of building personality and personal likings.
The harmful resuls that the so called Social networks create can be seen almost everywhere, most of the cafeterias I visit the bar tender uses facebook or youtube all da long, most of random people I see outside in a coffee or university or any public institution where internet access is available they are again in Youtube and Facebook. The result is people almost did not use the Net but just hang around in those few services wasting network bandwidth and loading networks and computer equipment and spending energy for nothing. The wasteful computer and Internet deepens the ecologic problems as energy is spend on nonsense and not goal oriented tasks but on “empty” false entertainment.
Hence the whole original idea of internet for many is changed and comes to few words ( Skype, Youtube, Facebook etc.
Besides that youngsters instead of reading some classical valuable books, are staring in the computer screen most of their cognitive time at only this few “services” and are learned to become more a consumers than self opinion thinkers and inventors.
I have not lately met any growing real thinking man. I’ve seen already by own experience the IQ level of younger generations than mine (I’m 28) is getting downer and downer. Where I see as a main cause the constant interaction with technology built in a way to restrict, a consumers technology so to say.
Facebook and Youtube puts in young and growing man’s mind, the wrong idea that they should be limited choice people always praising what is newest and brightest (without taking in consideration any sight effects). These services lead people to the idea that one should always be with the crowds and never have a solid own opinion or solid state on lifely matters. As said own opionion is highly mitigated especially in facebook where all young people try to look not what they really are but copy / paste some trendy buzz words, modern style or just copying the today’s hearoes of the day. This as one can imagine prevents a person of getting a strong unique self identity and preference on things.
Many of the older people or computer illiterates can hardly recognize the severe problems, as they’re not aware on the technical side of things and does not realize how much security compromising as well as binding the constant exposure to those online hives are.
The purpose of this small post is hence just a small attempt to try to raise up some awareness of the potential problems, we as society might face very soon if we continue to follow the latest buzz trends instead of stop for a moment have a profound think on what is the moral consequences of giving so much power on Internet medias like Facebook and Youtube? …
Tags: adoption rates, age, AltaVista, altavista search engine, amalgamation, computer screen, computer users, consumer, Culture, defacto, disco, downer, earlier times, Engine, facebook, freak, freedom, freedom program, global database, half, human freedom, impact, internet space, mail boom, malls, middle, monopoly, Myspace, negative impact, opinion, popuplation, quot, screen, Search, service users, Skype, social networks, software, technology, tendency, time, tru, yahoo mail, youtube
Posted in Everyday Life, Various | 7 Comments »
Tuesday, June 28th, 2011 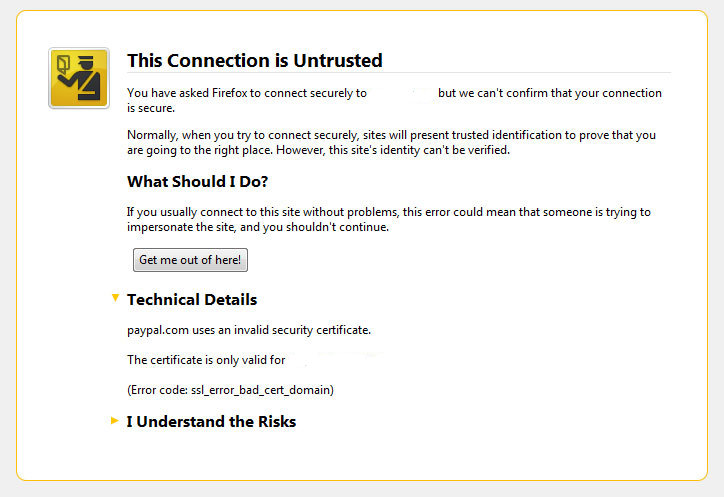
I’ve been issuing new wildcard multiple SSL certificate to renew an expiring ones. After I completed the new certificate setup manually on the server (a CentOS 5.5 Final running SoluSVM Pro – Virtual Private Manager), I launched Firefox to give a try if the certificate is properly configured.
Instead of my expectations that the browser would just accept the certificate without spitting any error messages and all will be fine, insetad I got error with the just installed certificate and thus the browser failed to report the SSL cert is properly authenticated.
The company used to issue the SSL certificate is GlobeSSL – http://globessl.com , it was quite “hassle”, with the tech support as the first certficate generated by globessl was generation based on SSL key file with 4096 key encryption.
As the first issued Authenticated certificate generated by GlobeSSL was not good further on about a week time was necessery to completethe required certificate reissuing ….
It wasn’t just GlobeSSL’s failure, as there were some spam filters on my side that was preventing some of GlobeSSL emails to enter normally, however what was partially their fault as they haven’t made their notification and confirmation emails to pass by a mid-level strong anti-spam filter…
Anyways my overall experience with GlobeSSL certificate reissue and especially their technical support is terrible.
To make a parallel, issuing certificates with GoDaddy is a way more easier and straight forward.
Now let me come back to the main certificate error I got in Firefox …
A bit of further investigation with the cert failure, has led me to the error message which tracked back to the newly installed SSL certificate issues.
In order to find the exact cause of the SSL certificate failure in Firefox I followed to the menus:
Tools -> Page Info -> Security -> View Certificate
Doing so in the General browser tab, there was the following error:
Could not verify this certificate for unknown reasons
The information on Could not verify this certificate for unknown reasons on the internet was very mixed and many people online suggested many possible causes of the issue, so I was about to loose myself.
Everything with the certificate seemed to be configured just fine in lighttpd, all the GlobeSSL issued .cer and .key file as well as the ca bundle were configured to be read used in lighttpd in it’s configuration file:
/etc/lighttpd/lighttpd.conf
Here is a section taken from lighttpd.conf file which did the SSL certificate cert and key file configuration:
$SERVER["socket"] == "0.0.0.0:443" {
ssl.engine = "enable"
ssl.pemfile = "/etc/lighttpd/ssl/wildcard.mydomain.bundle"
}
The file /etc/lighttpd/ssl/wildcard.mydomain.bundle was containing the content of both the .key (generated on my server with openssl) and the .cer file (issued by GlobeSSL) as well as the CA bundle (by GlobeSSL).
Even though all seemed to be configured well the SSL error Could not verify this certificate for unknown reasons was still present in the browser.
GlobeSSL tech support suggested that I try their Web key matcher interface – https://confirm.globessl.com/key-matcher.html to verify that everything is fine with my certificate and the cert key. Thanks to this interface I figured out all seemed to be fine with the issued certificate itself and something else should be causing the SSL oddities.
I was further referred by GlobeSSL tech support for another web interface to debug errors with newly installed SSL certificates.
These interface is called Verify and Validate Installed SSL Certificate and is found here
Even though this SSL domain installation error report and debug tool did some helpful suggestions, it wasn’t it that helped me solve the issues.
What helped was First the suggestion made by one of the many tech support guy in GlobeSSL who suggested something is wrong with the CA Bundle and on a first place the documentation on SolusVM’s wiki – http://wiki.solusvm.com/index.php/Installing_an_SSL_Certificate .
Cccording to SolusVM’s documentation lighttpd.conf‘s file had to have one extra line pointing to a seperate file containing the issued CA bundle (which is a combined version of the issued SSL authority company SSL key and certificate).
The line I was missing in lighttpd.conf (described in dox), looked like so:
ssl.ca-file = “/usr/local/solusvm/ssl/gd_bundle.crt”
Thus to include the directive I changed my previous lighttpd.conf to look like so:
$SERVER["socket"] == "0.0.0.0:443" {
ssl.engine = "enable"
ssl.pemfile = "/etc/lighttpd/ssl/wildcard.mydomain.bundle"
ssl.ca-file = "/etc/lighttpd/ssl/server.bundle.crt"
}
Where server.bundle.crt contains an exact paste from the certificate (CA Bundle) mailed by GlobeSSL.
There was a couple of other ports on which an SSL was configured so I had to include these configuration directive everywhere in my conf I had anything related to SSL.
Finally to make the new settings take place I did a lighttpd server restart.
[root@centos ssl]# /etc/init.d/lighttpd restart
Stopping lighttpd: [ OK ]
Starting lighttpd: [ OK ]
After lighttpd reinitiated the error was gone! Cheers ! 😉
Tags: anti spam filter, bundle, CentOS, cert, certficate, certificate, certificate error, Certificates, completethe, confirmation, confirmation emails, directive, encryption, Engine, error message, error messages, everything, exact cause, failure, file, Firefox, generation, godaddy, hassle, key file, menus, mid level, necessery, pemfile, place, private manager, Socket, something, spam filters, ssl certificate, support, tech support, time, Virtual
Posted in System Administration, Web and CMS | No Comments »




