In last post, I've talked about the problem of Search Index Crawler Robots aggressively crawling websites and how to stop them (the article is here) explaning how to raise delays between Bot URL requests to website and how to completely probhit some bots from crawling with robots.txt.
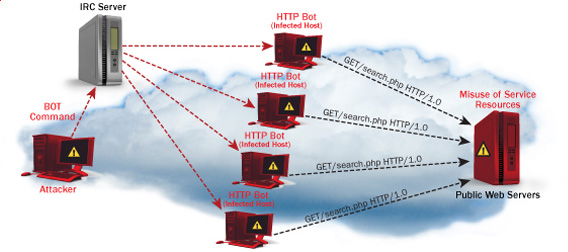
As explained in article the consequence of too many badly written or agressive behaviour Spider is the "server stoning" and therefore degraded Web Server performance as a cause or even a short time Denial of Service Attack, depending on how well was the initial Server Scaling done.
The bots we want to filter are not to be confused with the legitimate bots, that drives real traffic to your website, just for information
The 10 Most Popular WebCrawlers Bots as of time of writting are:
1. GoogleBot (The Google Crawler bots, funnily bots become less active on Saturday and Sundays :))
2. BingBot (Bing.com Crawler bots)
3. SlurpBot (also famous as Yahoo! Slurp)
4. DuckDuckBot (The dutch search engine duckduckgo.com crawler bots)
5. Baiduspider (The Chineese most famous search engine used as a substitute of Google in China)
6. YandexBot (Russian Yandex Search engine crawler bots used in Russia as a substitute for Google )
7. Sogou Spider (leading Chineese Search Engine launched in 2004)
8. Exabot (A French Search Engine, launched in 2000, crawler for ExaLead Search Engine)
9. FaceBot (Facebook External hit, this crawler is crawling a certain webpage only once the user shares or paste link with video, music, blog whatever in chat to another user)
10. Alexa Crawler (la_archiver is a web crawler for Amazon's Alexa Internet Rankings, Alexa is a great site to evaluate the approximate page popularity on the internet, Alexa SiteInfo page has historically been the Swift Army knife for anyone wanting to quickly evaluate a webpage approx. ranking while compared to other pages)
Above legitimate bots are known to follow most if not all of W3C – World Wide Web Consorium (W3.Org) standards and therefore, they respect the content commands for allowance or restrictions on a single site as given from robots.txt but unfortunately many of the so called Bad-Bots or Mirroring scripts that are burning your Web Server CPU and Memory mentioned in previous article are either not following /robots.txt prescriptions completely or partially.
Hence with the robots.txt unrespective bots, the case the only way to get rid of most of the webspiders that are just loading your bandwidth and server hardware is to filter / block them is by using Apache's mod_rewrite through
.htaccess
file
Create if not existing in the DocumentRoot of your website .htaccess file with whatever text editor, or create it your windows / mac os desktop and transfer via FTP / SecureFTP to server.
I prefer to do it directly on server with vim (text editor)
vim /var/www/sites/your-domain.com/.htaccess
RewriteEngine On
IndexIgnore .htaccess */.??* *~ *# */HEADER* */README* */_vti*
SetEnvIfNoCase User-Agent "^Black Hole” bad_bot
SetEnvIfNoCase User-Agent "^Titan bad_bot
SetEnvIfNoCase User-Agent "^WebStripper" bad_bot
SetEnvIfNoCase User-Agent "^NetMechanic" bad_bot
SetEnvIfNoCase User-Agent "^CherryPicker" bad_bot
SetEnvIfNoCase User-Agent "^EmailCollector" bad_bot
SetEnvIfNoCase User-Agent "^EmailSiphon" bad_bot
SetEnvIfNoCase User-Agent "^WebBandit" bad_bot
SetEnvIfNoCase User-Agent "^EmailWolf" bad_bot
SetEnvIfNoCase User-Agent "^ExtractorPro" bad_bot
SetEnvIfNoCase User-Agent "^CopyRightCheck" bad_bot
SetEnvIfNoCase User-Agent "^Crescent" bad_bot
SetEnvIfNoCase User-Agent "^Wget" bad_bot
SetEnvIfNoCase User-Agent "^SiteSnagger" bad_bot
SetEnvIfNoCase User-Agent "^ProWebWalker" bad_bot
SetEnvIfNoCase User-Agent "^CheeseBot" bad_bot
SetEnvIfNoCase User-Agent "^Teleport" bad_bot
SetEnvIfNoCase User-Agent "^TeleportPro" bad_bot
SetEnvIfNoCase User-Agent "^MIIxpc" bad_bot
SetEnvIfNoCase User-Agent "^Telesoft" bad_bot
SetEnvIfNoCase User-Agent "^Website Quester" bad_bot
SetEnvIfNoCase User-Agent "^WebZip" bad_bot
SetEnvIfNoCase User-Agent "^moget/2.1" bad_bot
SetEnvIfNoCase User-Agent "^WebZip/4.0" bad_bot
SetEnvIfNoCase User-Agent "^WebSauger" bad_bot
SetEnvIfNoCase User-Agent "^WebCopier" bad_bot
SetEnvIfNoCase User-Agent "^NetAnts" bad_bot
SetEnvIfNoCase User-Agent "^Mister PiX" bad_bot
SetEnvIfNoCase User-Agent "^WebAuto" bad_bot
SetEnvIfNoCase User-Agent "^TheNomad" bad_bot
SetEnvIfNoCase User-Agent "^WWW-Collector-E" bad_bot
SetEnvIfNoCase User-Agent "^RMA" bad_bot
SetEnvIfNoCase User-Agent "^libWeb/clsHTTP" bad_bot
SetEnvIfNoCase User-Agent "^asterias" bad_bot
SetEnvIfNoCase User-Agent "^httplib" bad_bot
SetEnvIfNoCase User-Agent "^turingos" bad_bot
SetEnvIfNoCase User-Agent "^spanner" bad_bot
SetEnvIfNoCase User-Agent "^InfoNaviRobot" bad_bot
SetEnvIfNoCase User-Agent "^Harvest/1.5" bad_bot
SetEnvIfNoCase User-Agent "Bullseye/1.0" bad_bot
SetEnvIfNoCase User-Agent "^Mozilla/4.0 (compatible; BullsEye; Windows 95)" bad_bot
SetEnvIfNoCase User-Agent "^Crescent Internet ToolPak HTTP OLE Control v.1.0" bad_bot
SetEnvIfNoCase User-Agent "^CherryPickerSE/1.0" bad_bot
SetEnvIfNoCase User-Agent "^CherryPicker /1.0" bad_bot
SetEnvIfNoCase User-Agent "^WebBandit/3.50" bad_bot
SetEnvIfNoCase User-Agent "^NICErsPRO" bad_bot
SetEnvIfNoCase User-Agent "^Microsoft URL Control – 5.01.4511" bad_bot
SetEnvIfNoCase User-Agent "^DittoSpyder" bad_bot
SetEnvIfNoCase User-Agent "^Foobot" bad_bot
SetEnvIfNoCase User-Agent "^WebmasterWorldForumBot" bad_bot
SetEnvIfNoCase User-Agent "^SpankBot" bad_bot
SetEnvIfNoCase User-Agent "^BotALot" bad_bot
SetEnvIfNoCase User-Agent "^lwp-trivial/1.34" bad_bot
SetEnvIfNoCase User-Agent "^lwp-trivial" bad_bot
SetEnvIfNoCase User-Agent "^Wget/1.6" bad_bot
SetEnvIfNoCase User-Agent "^BunnySlippers" bad_bot
SetEnvIfNoCase User-Agent "^Microsoft URL Control – 6.00.8169" bad_bot
SetEnvIfNoCase User-Agent "^URLy Warning" bad_bot
SetEnvIfNoCase User-Agent "^Wget/1.5.3" bad_bot
SetEnvIfNoCase User-Agent "^LinkWalker" bad_bot
SetEnvIfNoCase User-Agent "^cosmos" bad_bot
SetEnvIfNoCase User-Agent "^moget" bad_bot
SetEnvIfNoCase User-Agent "^hloader" bad_bot
SetEnvIfNoCase User-Agent "^humanlinks" bad_bot
SetEnvIfNoCase User-Agent "^LinkextractorPro" bad_bot
SetEnvIfNoCase User-Agent "^Offline Explorer" bad_bot
SetEnvIfNoCase User-Agent "^Mata Hari" bad_bot
SetEnvIfNoCase User-Agent "^LexiBot" bad_bot
SetEnvIfNoCase User-Agent "^Web Image Collector" bad_bot
SetEnvIfNoCase User-Agent "^The Intraformant" bad_bot
SetEnvIfNoCase User-Agent "^True_Robot/1.0" bad_bot
SetEnvIfNoCase User-Agent "^True_Robot" bad_bot
SetEnvIfNoCase User-Agent "^BlowFish/1.0" bad_bot
SetEnvIfNoCase User-Agent "^JennyBot" bad_bot
SetEnvIfNoCase User-Agent "^MIIxpc/4.2" bad_bot
SetEnvIfNoCase User-Agent "^BuiltBotTough" bad_bot
SetEnvIfNoCase User-Agent "^ProPowerBot/2.14" bad_bot
SetEnvIfNoCase User-Agent "^BackDoorBot/1.0" bad_bot
SetEnvIfNoCase User-Agent "^toCrawl/UrlDispatcher" bad_bot
SetEnvIfNoCase User-Agent "^WebEnhancer" bad_bot
SetEnvIfNoCase User-Agent "^TightTwatBot" bad_bot
SetEnvIfNoCase User-Agent "^suzuran" bad_bot
SetEnvIfNoCase User-Agent "^VCI WebViewer VCI WebViewer Win32" bad_bot
SetEnvIfNoCase User-Agent "^VCI" bad_bot
SetEnvIfNoCase User-Agent "^Szukacz/1.4" bad_bot
SetEnvIfNoCase User-Agent "^QueryN Metasearch" bad_bot
SetEnvIfNoCase User-Agent "^Openfind data gathere" bad_bot
SetEnvIfNoCase User-Agent "^Openfind" bad_bot
SetEnvIfNoCase User-Agent "^Xenu’s Link Sleuth 1.1c" bad_bot
SetEnvIfNoCase User-Agent "^Xenu’s" bad_bot
SetEnvIfNoCase User-Agent "^Zeus" bad_bot
SetEnvIfNoCase User-Agent "^RepoMonkey Bait & Tackle/v1.01" bad_bot
SetEnvIfNoCase User-Agent "^RepoMonkey" bad_bot
SetEnvIfNoCase User-Agent "^Zeus 32297 Webster Pro V2.9 Win32" bad_bot
SetEnvIfNoCase User-Agent "^Webster Pro" bad_bot
SetEnvIfNoCase User-Agent "^EroCrawler" bad_bot
SetEnvIfNoCase User-Agent "^LinkScan/8.1a Unix" bad_bot
SetEnvIfNoCase User-Agent "^Keyword Density/0.9" bad_bot
SetEnvIfNoCase User-Agent "^Kenjin Spider" bad_bot
SetEnvIfNoCase User-Agent "^Cegbfeieh" bad_bot
<Limit GET POST>
order allow,deny
allow from all
Deny from env=bad_bot
</Limit>
Above rules are Bad bots prohibition rules have RewriteEngine On directive included however for many websites this directive is enabled directly into VirtualHost section for domain/s, if that is your case you might also remove RewriteEngine on from .htaccess and still the prohibition rules of bad bots should continue to work
Above rules are also perfectly suitable wordpress based websites / blogs in case you need to filter out obstructive spiders even though the rules would work on any website domain with mod_rewrite enabled.
Once you have implemented above rules, you will not need to restart Apache, as .htaccess will be read dynamically by each client request to Webserver
2. Testing .htaccess Bad Bots Filtering Works as Expected
In order to test the new Bad Bot filtering configuration is working properly, you have a manual and more complicated way with lynx (text browser), assuming you have shell access to a Linux / BSD / *Nix computer, or you have your own *NIX server / desktop computer running
Here is how:
lynx -useragent="Mozilla/5.0 (compatible; MegaIndex.ru/2.0; +http://megaindex.com/crawler)" -head -dump http://www.your-website-filtering-bad-bots.com/
Note that lynx will provide a warning such as:
Warning: User-Agent string does not contain "Lynx" or "L_y_n_x"!
Just ignore it and press enter to continue.
Two other use cases with lynx, that I historically used heavily is to pretent with Lynx, you're GoogleBot in order to see how does Google actually see your website?
- Pretend with Lynx You're GoogleBot
lynx -useragent="Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" -head -dump http://www.your-domain.com/
- How to Pretend with Lynx Browser You are GoogleBot-Mobile
lynx -useragent="Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_1 like Mac OS X; en-us) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8B117 Safari/6531.22.7 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)" -head -dump http://www.your-domain.com/
Or for the lazy ones that doesn't have Linux / *Nix at disposal you can use WannaBrowser website
Wannabrowser – is a web based browser emulator which gives you the ability to change the User-Agent on each website req1uest, so just set your UserAgent to any bot browser that we just filtered for example set User-Agent to CheeseBot
The .htaccess rule earier added once detecting your browser client is coming in with the prohibit browser agent will immediately filter out and you'll be unable to access the website with a message like:
HTTP/1.1 403 Forbidden
Just as I've talked a lot about Index Bots, I think it is worthy to also mention three great websites that can give you a lot of Up to Date information on exact Spiders returned user-agent, common known Bot traits as well as a a current updated list with the Bad Bots etc.
Bot and Browser Resources information user-agents, bad-bots and odd Crawlers and Bots specifics
1. botreports.com
2. user-agents.org
3. useragentapi.com
An updated list with robots user-agents (crawler-user-agents) is also available in github here regularly updated by Caia Almeido
There are also a third party plugin (modules) available for Website Platforms like WordPress / Joomla / Typo3 etc.
Besides the listed on these websites as well as the known Bad and Good Bots, there are perhaps a hundred of others that might end up crawling your webdsite that might or might not need to be filtered, therefore before proceeding with any filtering steps, it is generally a good idea to monitor your HTTPD access.log / error.log, as if you happen to somehow mistakenly filter the wrong bot this might be a reason for Website Indexing Problems.
Hope this article give you some valueable information. Enjoy ! 🙂