![]()
I'm forced to use Windows every now and then and do some ordinary things which I do usually on Linux such as dumping the content of my Android phone SD Card SanDisk, Kingston etc. to .ISO image etc.
On Linux creating and mounting a data copy of a whole SD Card is a relatively simple thing and there are plenty of ways to do it such as using the dd ( command-line utility for Unix and Unix-like operating systems whose primary purpose is to convert and copy files as said in the command manual .- e.g. ''man dd'. ). On Microsoft Windows environment perhaps one of easiest ways is to use WinCDEmu (which is relatively free under LGPL License).
WinCDEmu is capable of doing plenty of things such as:
-
One-click mounting of ISO, CUE, NRG, MDS/MDF, CCD, IMG images.
-
Supports unlimited amount of virtual drives.
-
Runs on 32-bit and 64-bit Windows versions from XP to Windows 10.
-
Allows creating ISO images through a context menu in Explorer.
-
Small installer size – less than 2MB!
-
Have a portable version
WinCDEmu is a nice piece of software that perhaps every Win poweruser can enjoy, plus it has a nice Graphical frontend:
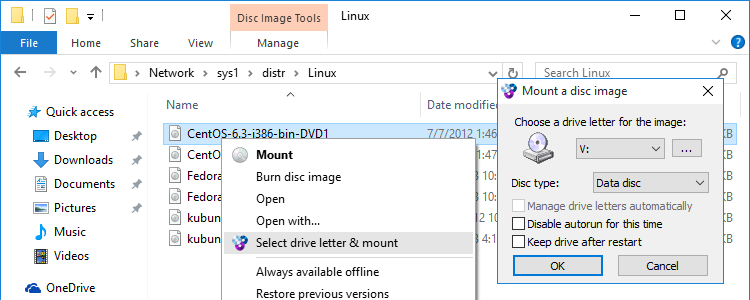
But what if you're a console geek, like me and you end up forced to be using Windows on your Work PC and you still need to create .iso dump of your Mobile SD Card or external attached Hard Drive, without the graphical mambo jumbo in the old fashioned way with dd?
Luckily Windows advanced command lined users could massively benefit from Cygwin + Mobaxterm (if you don't know or used MobaXterm and you still use things like Putty / SuperPutty or SecureCRT – perhaps you can reconsider and make your sysadmin life easier with MobaXerm gnome-terminal like SSH tabbed Windows alternative.
Once having mobaxterm + cygwin you have dd installed on the Windows host as it is part of the busybox minimal environment and you can use it in the same manner as your used in Linux environment.
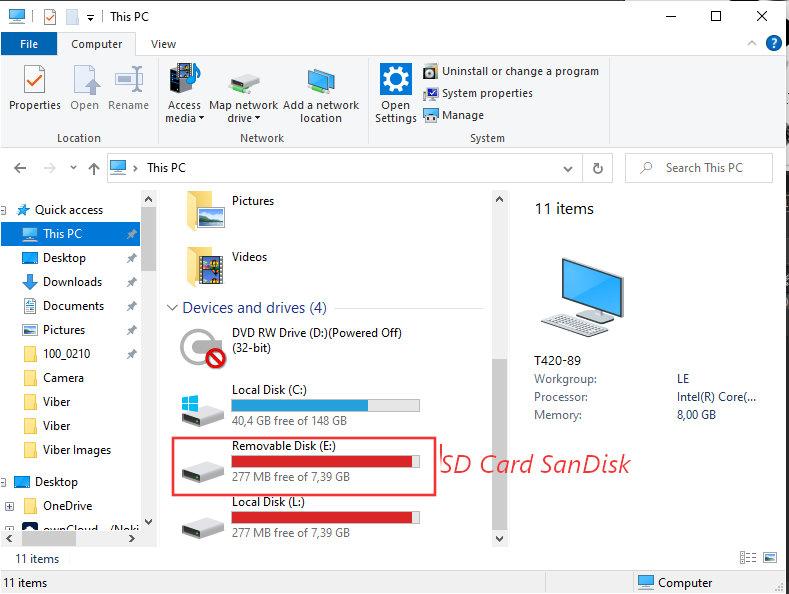
1. Using dd to copy files on Linux / UNIX OS with a dialog status bar
To use dd the usual syntax on Linux / BSD / Unix is:
dd if=/dev/dev-name_ID of=/path/to/directory/dump/location.iso bs=2048
As 2048 BS (Bytes) per second is quite a low value usually on Modern operating systems, this bytesize is usually increased to some MBs ( Megabytes).
For example if the reading from carrier is Solid State Drive Disk (SSD) supporting 100 MBs per second and the output SD Card is a 32 Bit Kingston Plus+ drive with whose write speed is up to 50 ~ 100 MBs, you can use cmd as:
dd if=/dev/dev-name_ID of=/path/to/directory/dump/location.iso bs=100M
If you need to have a progress on the dd copy (in case if you copy some large SD Card 128 GB or 256GB or a full copy of a hard drive partition that is really big lets say 8 Terabytes of data, dialog and pv comes quite handy.
To use them install them first:
# apt-get install –yes pv dialog
…
Next to have a beautiful ncurses dialog box with the status (very useful if you're shell scripting), use:
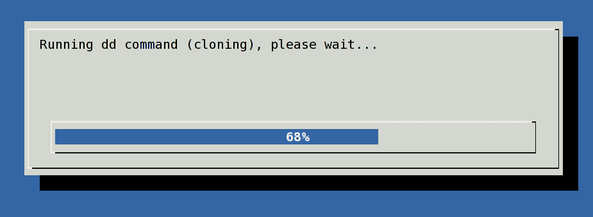
(pv -n /dev/sda | dd of=/dev/sdb bs=128M conv=notrunc,noerror) 2>&1 | dialog –gauge "Running dd command (cloning), please wait…" 10 70 0
2. Listing the avaialble copy drives /dev/sda /dev/sdb1 … etc. disk locations on Windows 7 / 10 / 11 OS
[User.T420-89] ➤ for F in /dev/s* ; do echo "$F $(cygpath -w $F)" ; done
 Check drives device naming on WIndows PC – Screenshot extract from Mobaxterm
Check drives device naming on WIndows PC – Screenshot extract from Mobaxterm
As you can see the drive location we've seen in Windows Explorer is located at drive E: above bash for loop reveals us this is located and readable from CygWin / MobaxTerm at /dev/sdb1
3. Create .iso image file on WIndows OS with dd command
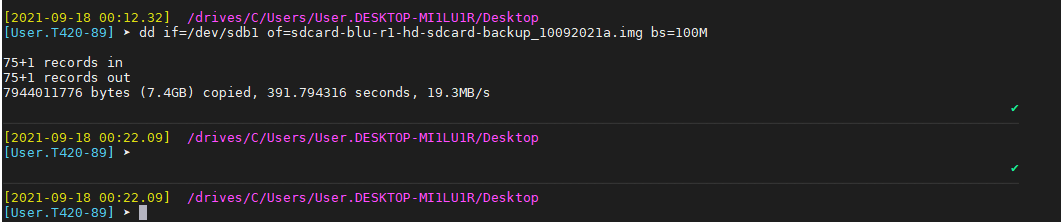
To create a full data copy dump of to .iso (image file) with dd on Windows , I had to run:
[User.T420-89] ➤ dd if=/dev/sdb1 of=sdcard-blu-r1-hd-sdcard-backup_10092021a.img bs=100M
75+1 records in
75+1 records out
7944011776 bytes (7.4GB) copied, 391.794316 seconds, 19.3MB/s…
4. Mount the newly create dd Image with imdisk
In order to test the image is properly created, you can attempt to mount it from command line on Linux, mounting it is quite easy and is up to mounting the just created .img file as a loopback (loop) device, like so:
# mount -o loop file.iso /mnt/dir
Unfortunately cygwin and mobaxterm's embedded mount command on Win OS does not support the loopback device so to have it you have to install and use some additional program such as the upmentioned WinCDEmu or if you prefer to do it fully from command line and further on automate the process of creating a dump of images of attached drives out of a multiple computers (lets say belonging to a Windows Active Directory domain). You might install and use something like:
imdisk
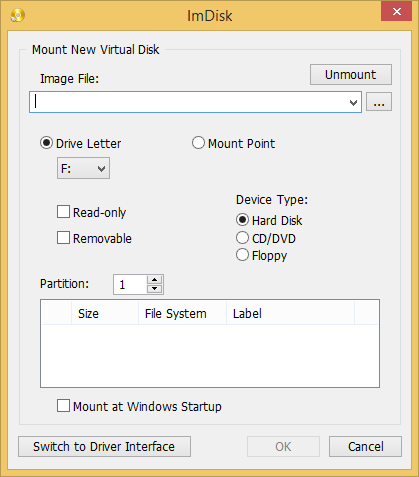
imdisk handy tool is created by Olof Lagerkvist. It is free and open-source software, which will let you mount image files of hard drive, cd-rom or floppy, and create one or several ramdisks with various parameters either from a command line or via its Graphical interface.
To use imdisk download it from its home page on sourceforge extract and install it, pretty much as any other software it has both 32 bit version as a legacy for old computers as well as 64 bit exe installer.
The general command line use of it follows a cmd syntax like:
- Mounting .iso image files from command line on WIndows host with imdisk
[User.T420-89] ➤ ImDisk.exe -a -f "sdcard-blu-r1-hd-sdcard-backup_10092021.img" -m #:
Where:
- #: – is the actual drive you would like to mount to.
- -a option stands for attach to, it will configure and attach a virtual disk with the parameters specified and attach it to the system.
- -f – is self explanatory, provides the iso image file naming
If you want to attach the newly created image to lets say L:\ windows new mapped drive
ImDisk.exe -a -f "sdcard-blu-r1-hd-sdcard-backup_10092021.img" -m l:
- Unmount mounted .img image with imdisk from cmd line
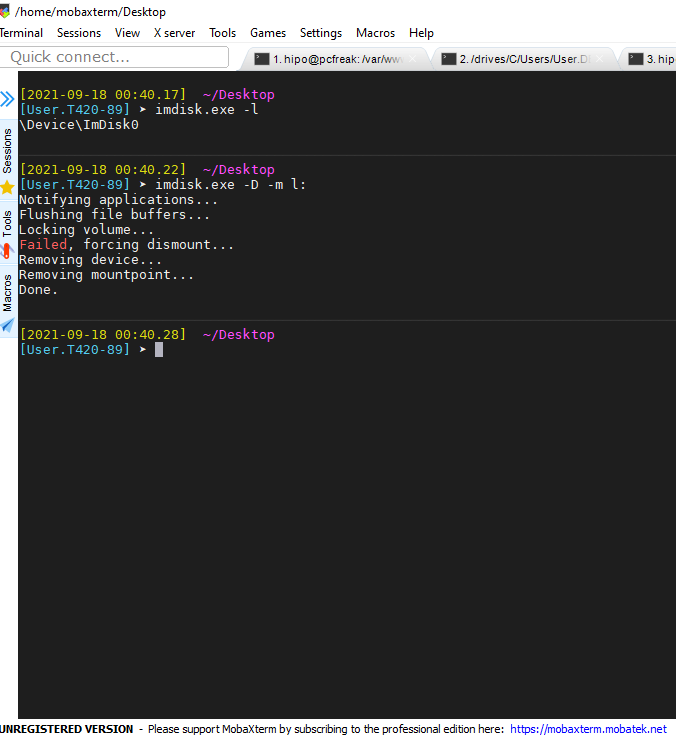
[User.T420-89] ➤ imdisk.exe -l
\Device\ImDisk0
✘[User.T420-89] ➤ imdisk.exe -D -m l:
Notifying applications…
Flushing file buffers…
Locking volume…
Failed, forcing dismount…
Removing device…
Removing mountpoint…
Done.
What we learned ?
What we have learned in this article is how to use Mobaxterm embedded dd Data Convert and Copy command to prepare full image backups of SD card or external drives on Windows OS. Also few alternative ways were entions such as using WinCDEmu free open source alternative to DaemonTools program to create / mount or convert the image for the GUI lovers. Also for hard core sysadmins as me was shown how to list drives devices attached to the Win PC {/dev/sda,/dev/sdb} etc. and how to copy partition data with dd just like one would do on Linux OS. Finally to test the created image, I've shown you how to use the imdisk free software tool to attach and detach image to a mapped local Windows drive.
Hope this article learned you something new.








How rescue unbootable Windows PC, Windows files through files Network copy to remote server shared Folder using Hirens Boot CD
Saturday, November 12th, 2011I'm rescuing some files from one unbootable Windows XP using a livecd with Hirens Boot CD 13
In order to rescue the three NTFS Windows partitions files, I mounted them after booting a Mini Linux from Hirens Boot CD.
Mounting NTFS using Hirens BootCD went quite smoothly to mount the 3 partitions I used cmds:
# mount /dev/sda1 /mnt/sda1# mount /dev/sda2 /mnt/sda2
# mount /dev/sdb1 /mnt/sdb1
After the three NTFS file partitions are mounted I used smbclient to list all the available Network Shares on the remote Network Samba Shares Server which by the way possessed the NETBIOS name of SERVER 😉
# smbclient -L //SERVER/Enter root's password:
Domain=[SERVER] OS=[Windows 7 Ultimate 7600] Server=[Windows 7 Ultimate 6.1]
Sharename Type Comment
——— —- ——-
!!!MUSIC Disk
ADMIN$ Disk Remote Admin
C$ Disk Default share
Canon Inkjet S9000 (Copy 2) Printer Canon Inkjet S9000 (Copy 2)
D$ Disk Default share
Domain=[SERVER] OS=[Windows 7 Ultimate 7600] Server=[Windows 7 Ultimate 6.1]
Server Comment
——— ——-
Workgroup Master
——— ——-
Further on to mount the //SERVER/D network samba drive – (the location where I wanted to transfer the files from the above 3 mounted partitions):
# mkdir /mnt/D# mount //192.168.0.100/D /mnt/D
#
Where the IP 192.168.0.100 is actually the local network IP address of the //SERVER win smb machine.
Afterwards I used mc to copy all the files I needed to rescue from all the 3 above mentioned win partitions to the mounted //SERVER/D
Tags: admin, admin c, boot cd, bootcd, Canon, canon inkjet, cd 13, Comment, copy, default, default share, Disk, domain, domain server, drive, hirens boot cd, ip, livecd, local network, location, machine, Master, Mini, mini linux, mnt, mount dev, music disk, nbsp, netbios, netbios name, network ip address, network shares, NTFS, os windows, partitions, password, printer canon, Printer Canon Inkjet S9000 Copy, Remote, remote admin, remote server, rescue, root, samba shares, sda, sdb, Server Comment, server os, server windows, Sharename, unbootable, Windows, windows files, windows pc
Posted in Everyday Life, Linux, System Administration, Windows | 1 Comment »