In previous article I've wrote on how to install postgresql on Debian Linux using the deb repository this was necessery to import some PostGres DBs, however this was not enough to run the posgresql php based website aimed as connection from Apache / PHP module to PostGre was failing after a bit of investigation and a check in phpinfo(); I've realized the module PHP module for postgres pgsql.so was missing, here is what I did in order to install it:
debian:~# apt-get install php5-pgsql phppgadmin libapache2-mod-auth-pgsql
PHP sessions enable configuration
As it is common a common problem with PHP applications written to use PostGres is to loose sessions and by default PHP does not have configured sessions.save_path it is a very good practice to directly enable it in /etc/php5/apache2/php.ini open the file in text editor:
debian:~# vim /etc/php5/apache2/php.ini
Find the commented directive line:
;session.save_path = “/tmp”
and uncomment it, i.e.:
session.save_path = “/tmp”
Quit saving vim with the usual :wq!
The 3 modules provides pgsql.so for PHP and mod_auth_pgsql.so for Apache2, the 3rd packae phpgadmin provides a Web administration interface for installed PostgreSQL servers Databases, for those experienced with MySQL Database its the same as PHPMyAdmin.
Here is quick configuration for use of PostgreAdmin interface:
By default PHPPGADMIN installation process configure the Apache2 server' /etc/phppgadmin/apache.conf to use /etc/apache2/conf.d/phppgadmin
Here is the default my server package instaleld file content:
Alias /phppgadmin /usr/share/phppgadmin
<Directory /usr/share/phppgadmin>
DirectoryIndex index.php
AllowOverride Noneorder deny,allow
deny from all
allow from 127.0.0.0/255.0.0.0 ::1/128
# allow from all<IfModule mod_php5.c>
php_flag magic_quotes_gpc Off
php_flag track_vars On
#php_value include_path .
</IfModule>
<IfModule !mod_php5.c>
<IfModule mod_actions.c>
<IfModule mod_cgi.c>
AddType application/x-httpd-php .php
Action application/x-httpd-php /cgi-bin/php
</IfModule>
<IfModule mod_cgid.c>
AddType application/x-httpd-php .php
Action application/x-httpd-php /cgi-bin/php
</IfModule>
</IfModule>
</IfModule></Directory>
It is generally a good practice to change the default Alias location of phppgadmin, so edit the file and change it to something like:
Alias /phppostgresgadmin /usr/share/phppgadmin
-
Then phpPgAdmin is available at http://servername.com/phppostgresadmin (only from localhost, however in my case I wanted to be able to access it also from other hosts so allowed PostgresGadmin from every hosts, to do so, I've commented in above config
# allow from 127.0.0.0/255.0.0.0 ::1/128
and uncommented #allow from all line, e.g.:
allow from all
Also another thing here is in your VirtualHost whenever you plan to access the PHPPGADMIN is to include in config ( in my case this is the file /etc/apache2/sites-enabled/000-default before (</VirtualHost> end line) following Alias:
Alias /phpposgreadmin /usr/share/phppgadmin
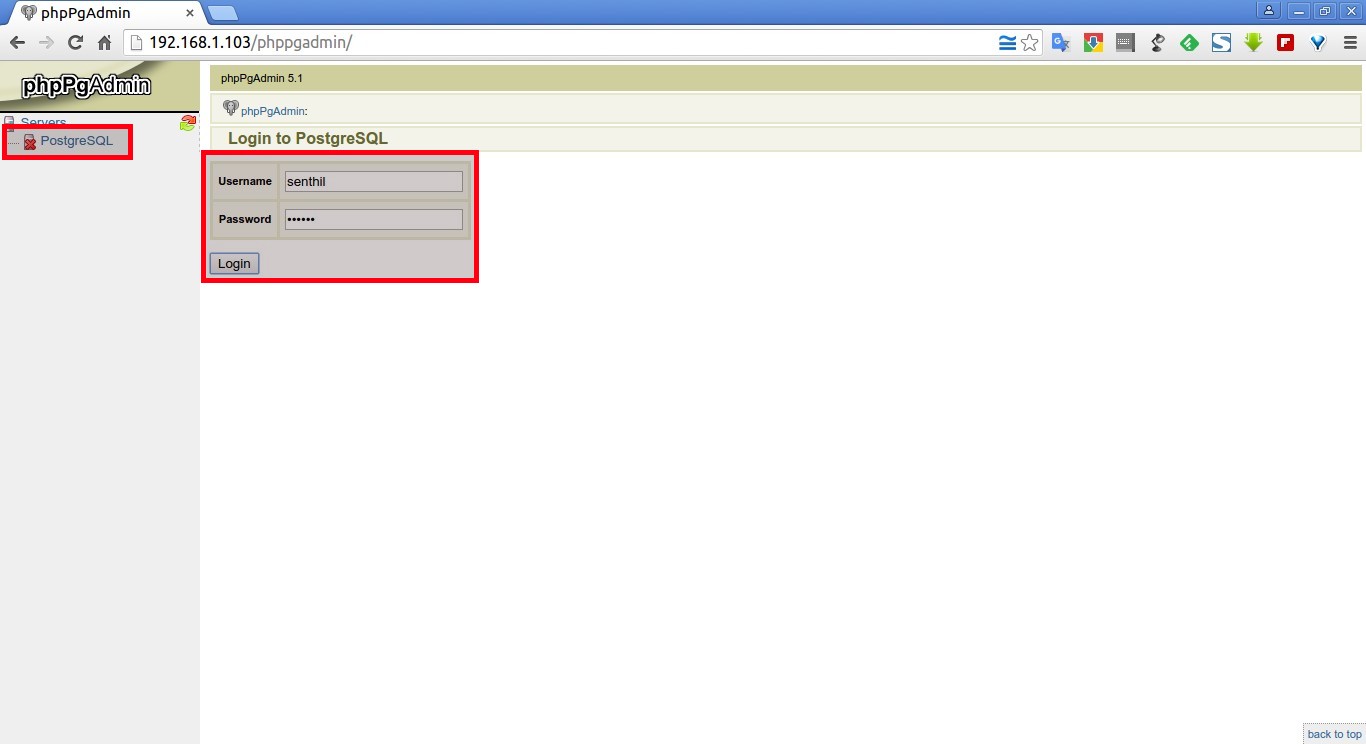
Then to access PostGreSQL PHP Admin interface in Firefox / Chrome open URL:
http://your-default-domain.com/phpposgreadmin
Configure access to a remote PostgreSQL Server
With PhpPgAdmin, you can manage many PostgreSQL servers locally (on the localhost) or on remote hosts.
First, you have to make sure that the distant PostgreSQL server can handle your request, that you can connect to it. You can do this by modifying the /etc/postgresql/9.5/main/file and adding a line like:
# PhpPgAdmin server access host all db_admin xx.xx.xx.xx 255.255.255.255 md5
Then, you need to add your distant PostgreSQL server into the config file for PhpPgAdmin. This file is /etc/phppgadmin/config.inc.php the default postgresql port is 5432, however you might have configured it already to use some different port if you're not sure about the port number the postgresql is listening check it out:
debian:~# grep -i port /etc/postgresql/*/main/postgresql.conf
etc/postgresql/9.5/main/postgresql.conf:port = 5433 # (change requires restart)
/etc/postgresql/9.5/main/postgresql.conf: # supported by the operating system:
/etc/postgresql/9.5/main/postgresql.conf: # supported by the operating system:
/etc/postgresql/9.5/main/postgresql.conf:# ERROR REPORTING AND LOGGING
To login to phppgadmin interface there is no root administrator user such as in PHP so you will need to priorly create some user and later use it for connection from Postgres Web interface.
To create from console new user in postgres:
debian:~# su – postgres
posgres@debian:~$ psql template1
posgres@debian:~$ psql -d template1 -U postgres
Welcome to psql 9.5, the PostgreSQL interactive terminal. Type: \copyright for distribution terms \h for help with SQL commands \? for help on internal slash commands \g or terminate with semicolon to execute query \q to quit template1=#
template1=# CREATE USER MyNewUser WITH PASSWORD 'myPassword';
To add a new database to postgres from shell:
template1=# CREATE DATABASE NewDatabase;
template1=# GRANT ALL PRIVILEGES ON DATABASE NewDatabase to MyNewUser;
template1=# q
Last command instructs it to quit if you want to get more info about possible commands do type instead of q ? for general help or for database / table commands only h
If you need to connect to NewDatabase just to test first it works in console before trying it from postgrepgadmin
posgres@debian:~$ psql -d NewDatabase -U MyNewUser