I run into a funny case I went to see some friends in another City and used their Samsung Tablet for some Skype Chatting and few Skype Calls. When logging in I forgot to untick the "Save password" tick and when I left the city and travelled to my home I saw on my wife's Skype (who has my username) logged in that still my Skype keeps logged in. In other words Skype shows I'm online even though I was not really connected.
I remembered I forgot to logoff Skype from the Tablet, so any time the tablet was connected to the internet or restarted Skype started I was automatically logged in Skype. This was pretty annoying because many people write me when I'm in fact offline and the messages end up in the tablet and I'm not answering making truly a bad impression (many friends and relatives, think I'm rude for not answering and even started being angry with me without me knowing why …)
To solve the situation, I had to use /remotelogout Skype Chat Windows command which is not visible as standard commands:
/remotelogout
This command logout all users logged in any device ( Android / iPhones Mobile Phones etc.) so afterwards, one can be sure you're logged in just from one device (the current one from where you execute the command)
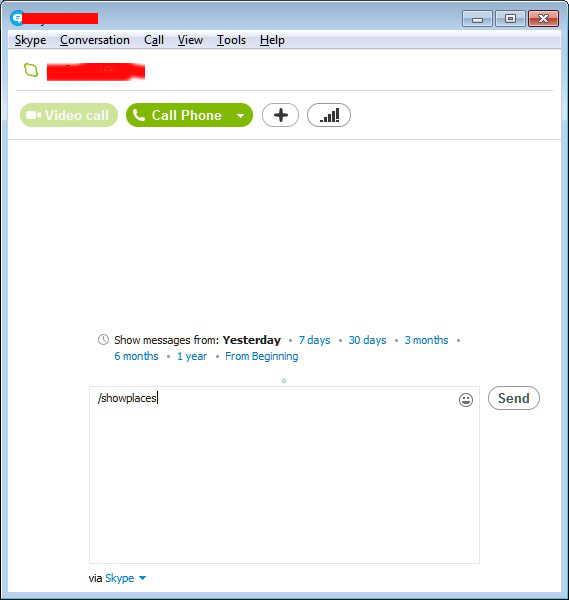
To be absolutely sure, there are no other devices logged in with your credentials there is also /showplaces command:
/showplaces
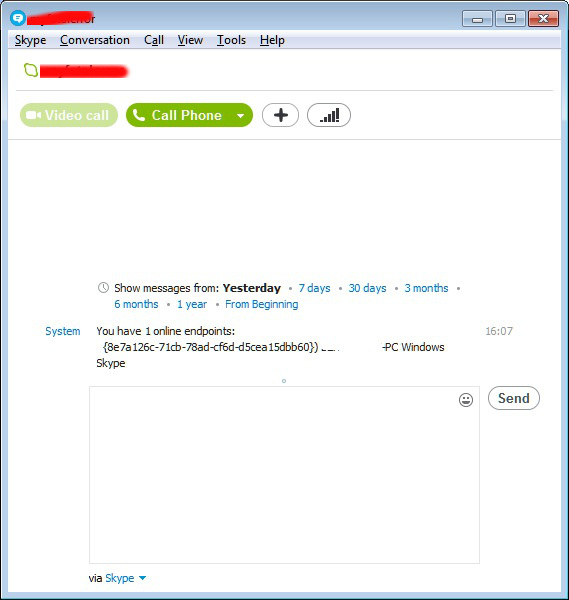
You have 1 online endpoints: {6934eadb-3eec-e001-4bc6-064e0552018f} 'WINDOWSVM' (Windows Skype)
The standard commadns shown in Skype help with /help typed in on any userchat opened Window are:
However there is another less knownComplete list of supported Skype (Hidden) commands you can use to imitiate most of GUI Skype motions + a lot of info you can get only via those commands, here it is:
Command
Description
/add [Skype Name]
Adds a contact to the chat. For instance:/add alex_cooper1 will add that member to the chat.
/alertson [text]
Allows you to specify what needs to appear in a chat for you to be notified. For example, /alertson London will only alert you when the word “London” appears in the chat.
/alertsoff
Disable message notifications.
/clearpassword
Removes the password security.
/find [text]
Finds specific text in a chat. For example,/find Charlie will return the first instance of the word “Charlie” in the chat.
/get allowlist
Details people with access to the chat.
/get banlist
Details people banned from the chat.
/get creator
Details the person who created the chat.
/get guidelines
See the current chat’s guidelines.
/get options
Details active options for current chat – see /set options below for a list of the options available.
/get password_hint
Get the password hint.
/get role
Details your role in the chat.
/get uri
Creates a URL link that other people can use to join the group chat.
/golive
Starts a group call with other participants of the chat.
/info
Details number of people in chat and maximum number available.
/kick [Skype Name]
Eject chat member. For instance,/kick alex_cooper1 will eject that member from the chat.
/kickban [Skype Name]
Ejects chat member and prevents them from rejoining chat. For instance,/kickban alex_cooper1 will eject that member from the chat and ban them from rejoining.
/leave
Leave current group chat.
/me [text]
Your name will appear followed by any text you write. For instance, /me working from home will cause the phrase “working from home” to appear next to your name in the chat. You can use this to send a message about your activities or status.
/remotelogout
Sign out all other instances except the current one. This will also stop push notifications on all other instances.
/set allowlist [[+|-]mask] ..
Sets the members allowed in the chat. For instance, /set allowlist +alex_cooper1 will allow that member to join the chat.
/set banlist [[+|-]mask] ..
Sets which members are banned from the chat. For instance, /set banlist +alex_cooper1 will ban that member from the chat. /set banlist -alex_cooper1will allow them to rejoin it.
/set guidelines [text]
Set a chat’s guidelines. For instance, /set guidelines No spoilers! These can be returned to be viewed in the chat by the command /get guidelines.
/set options [[+|-]flag]
Sets options for this chat. For example: /set options -JOINING_ENABLED switches off the JOINING_ENABLED option, while /set options +JOINERS_BECOME_APPLICANTS will switch on the JOINERS_BECOME_APPLICANTS option.
The available flags to commands are listed below:
HISTORY_DISCLOSED – Joiners can see the conversation that took place before they joined. The limit that they can see is either 400 messages or two weeks of time, depending on which is reached first.
JOINERS_BECOME_APPLICANTS – New users can join the chat, but cannot post or receive messages until authorized by a CREATOR or MASTER (see the table below for more information on roles).<
JOINERS_BECOME_LISTENERS – New users can receive messages but cannot post any until promoted to the USER role.
JOINING_ENABLED – New users can join the chat.
TOPIC_AND_PIC_LOCKED_FOR_USERS – Only a user with a CREATOR role will be able to change the topic text or accompanying picture for the chat.
USERS_ARE_LISTENERS – Users with a USER role will be unable to post messages.
/set password [text]
Create a password (no spaces allowed).
/set password_hint [text]
Create the chat’s password hint text.
/setpassword [password] [password hint]
Create a password and password hint for the chat.
/setrole [Skype Name] MASTER | HELPER | USER | LISTENER
Allows you to set a role to each chat member. A description of roles is given in the table below.
/showplaces
Lists other instances where this Skype name is currently signed in.
/topic [text]
Changes the chat topic.
/undoedit
Undo the last edit of your message.
/whois [Skype Name]
Provides details about a chat member such as current role.
/fa or /
Repeats the last search.
/history
Loads the complete chat history into the active chat window.
/htmlhistory
Generates a HTML file of the chats history and opens it in the browser. Skype 4: not iplemented in this version anymore.
/clear
Clears the chat window.
/goadmin
Enters the administration mode of the chat (only if creator) and adds a small text “Creator” to the user-icon in the chat. I didn’t find so far a way to leave this mode again. According to the Skype documentation the only effect is the “Creator” tag but I’m not so sure about that.
/dbghelp
Outputs a list of (debug?) commands but without description.
/showmembers
Lists all members of the chat with their currently assigned role.
/showstatus
Prints some infos about the current conversation. Conversation convoi id, Consumption horizon, History date and Message count.
/showname
Displays the name of the original conversation
/verify
Shows some text about missing messages on my computer. Maybe checks the message-database for validity.
/golive [token]
(since Skype4?) Opens a management window in a group conversation which allows to handle conference calls. The sense of the (optional) token is not yet clear to me but seems to give you a link which you can share to others and allow them to join the conference.
/fork [skypename/s]
(since Skype5?) Duplicates the current group chat leaving out the contacts which are added to this command.
/fork [skypename/s]
(since Skype5?) Duplicates the current group chat leaving out the contacts which are added to this command.
/showplaces
Displays a list of the currently online Skype instances using this Skype name (and have Skype version >=6 or recent mobile versions).
/remotelogout
Logs out all other currently online Skype instances which are using this Skype name (and have Skype version >=6 or recent mobile versions).
/get listeners
Shows the list of listeners set with previous command.
/golive [name]
this command starts a call with other participants of the chat. It’s your choice to indicate a call name or not.
Did you ever needed to count, how many files in a directory are there? Having the concrete number of files in a directory is not a seldom task but still very useful especially for scripts or simply for the sake of learning
The quickest and maybe the easiest way to count all files in a directory in Linux is with a combination of find and wc commands:
Here is how;
linux:~# cd ascii
linux:~/ascii# find . -type f -iname '*' -print |wc -l
407
This will find and list all matched files in any directory and subdirectories, print them out and count them with wc command. The -type f argument instructs find to look only for files.
Other helpful variance of finding and listing all files in a directory and subdirectories is to list and count all the files with a certain file extension under a directory. For example, lets list all text files (.txt) contained in a directory and all level sub-directories:
If you need to check the number of files in a directory for multiple directories on a server and you're aiming at doing it efficienly, issung above find .. | wc code will definitely be not a good choice. If used it will generate heavy load for the system and along with that will complete the execution in ages if issued on a large number of files containing dirs.
Thanksfully if efficiency is targetted, there is a command written in C called tree which is more efficient than find. To count the number of files in dir but using tree :
linux:~# cd ascii
linux:/ascii# tree | tail -n 1
32 directories, 407 files
By default tree prints info for both the number of found files and directories. To print out only the files matched, awk comes handy, e.g.:
linux:/ascii# tree |tail -n 1| awk '{ print $3 }'407
To list only the number of files in a directory without its existing sub-directories ls + wc use is also possible:
linux:~/ascii# ls -l | grep ^- | wc -l68
This result the above command would produce is +1 more than the real number of files, as it counts the directory ".." as one file (in UNIX / LINUX everything is file).
A short one liner script that can calculate all files correctly by substracting 1 is and hence present correct result on number of files is like so:
ls can be used to calculate the number of 1-st level sub-directories under certain directory for instance:
linux:~/ascii# ls -l |grep ^d|wc -l
25
You see the ascii directory has 25 subdirectories in its 1st level.
To check symlinks under a directory with ls the command would be:
linux:~/ascii# ls -l | grep ^l | wc -l
0
Note above 3 ls | grep … examples, will not work properly if the directory contains files with SUID or some special properties set. Hence to get the same 3 results for active files, directories and symbolic links, a one liner similar to the one below can be used instead:
linux:~/ascii# for t in files links directories; do echo `find . -type ${t:0:1} | wc -l` $t; done 2> /dev/null
407 files
0 links
33 directories
This will show statistics about all files, links and directories for all directory sub-levels. Just in case if there is need to only count files, links and directories without directory recursion enabled, use:
linux:~/ascii# for t in files links directories; do echo `find . -maxdepth 1 -type ${t:0:1} | wc -l` $t; done 2> /dev/null
68 files
0 links
26 directories
Anyways the above bash loop will be slow, for directories containing thousands of files. For better performance the equivallent of above bash loop rewritten in perl would be:
linux:~/ascii# ls -l |perl -e 'while(<>){$h{substr($_,0,1)}+=1;} END {foreach(keys %h) {print "$_ $h{$_}\n";}}'
- 68
d 25
t 1
linux:~/ascii#
In any case the most preferrable and efficient way to count files en directories is by using tree command. In my view using always tree command instead of code "hacks" is smart idea.
In Slackware tree command is part of the base install, on Debian and CentOS Linux, tree cmd is not part of the base system and requires install via apt / yum e.g.:
I’ve recently built new mail qmail server with vpopmail to serve pop3 connectins and courierimap and courierimaps to take care for IMAP IMAPS.
I further used telnet to test if the Linux server pop3 service on (110) and imap on (143) worked fine, straight after the completed qmail install. Here is how to test mail server with vpopmail listening for connections on pop3 port :
debian:~# telnet mail.mymailserver.com 110
Trying 111.222.333.444...
Connected to mail.mymailserver.com.
Escape character is '^]'.
+OK <2813.1312745988@mymailserver.com>
USER hipo@mymailserver.com
+OK
PASS here_goes_my_secret_pass
+OK
LIST
1 309783
2 64053
3 2119
4 64357
5 317893
RETR 1 My first mail content retrieved with RETR commandgoes here ....
quit
+OK
Connection closed by foreign host.
You see I have 5 messages in my mailbox, as you can see I used RETR command to check the content of my mail, this is handy as I can read my mails straight with telnet (if the mail is in plain text), of course it’s a bit more complicated if I have to read encrypted or html mail, though still its easy to write a tiny parser and pipe the content produced by telnet command to lynx or some other text based browser.
Now another sys admin handy tip is the use of telnet to check my mail servers IMAP servers is correctly operating. Here is how:
debian:~# telnet mail.mymailserver.com 143
Trying 111.222.333.444...
Connected to localhost.
Escape character is '^]'.
* OK [CAPABILITY IMAP4rev1 UIDPLUS CHILDREN NAMESPACE THREAD=ORDEREDSUBJECT THREAD=REFERENCES SORT QUOTA IDLE ACL ACL2=UNION STARTTLS] Courier-IMAP ready. Copyright 1998-2010 Double Precision, Inc. See COPYING for distribution information. 01 LOGIN hipo@mymailserver.com here_goes_my_secret_pass
A OK LOGIN Ok.
02 LIST "" *
* LIST (Unmarked HasNoChildren) "." "INBOX"
02 OK LIST completed
03 SELECT INBOX
* FLAGS (Draft Answered Flagged Deleted Seen Recent)
* OK [PERMANENTFLAGS (* Draft Answered Flagged Deleted Seen)] Limited
* 5 EXISTS
* 5 RECENT
* OK [UIDVALIDITY 1312746907] Ok
* OK [MYRIGHTS "acdilrsw"] ACL
03 OK [READ-WRITE] Ok
04 STATUS INBOX (MESSAGES)
* STATUS "INBOX" (MESSAGES 5)
04 OK STATUS Completed.
05 FETCH 1 ALL
...
06 FETCH 1 BODY
...
07 FETCH 1 ENVELOPE
...
As you can see according to standard to send commands to IMAP server from console after a telnet connection you will have to always include a command line number like 01, 02, 03 .. etc.
Using such a line numbering is not obligitory and also letters like A, B, C could be use still line numbering with numbers is generally a good idea since it’s easier for reading on the screen.
Now line 02 shows you available mailboxes, line 03 SELECT INBOX selects the imap Inbox to be further operated with, 04 STATUS INBOX cmd displays status about current mailboxes in folder. FETCH 1 ALL instructs the imap server to get list of all IMAP message headers. Next command in line 05 FETCH 1 BODY will display the message body of the first message in list. The 07 FETCH 1 ENVELOPE will display the mail headers for the 1 message.
Few other IMAP commands which might be helpfun on connection are:
08 FETCH 1 FULL
09 FETCH * FULL First one would fetch complete content of a message numbered one from the imap server and the second one 09 FETCH * FULL will get all the mail content for all messages located on the remote IMAP server.
The STATUS command aforementioned earlier could take the following list of arguments:
MESSAGES, UNSEEN, RECENT UIDNEXT UIDVALIDITY
These commands are a gold mine for me as a sysadmin as it helps quickly solve problems, hope they would help to somebody out there as well 😉 This way is a way shorter than bothering each time to check, if some customer e-mail account is improperly configured by creating setting up a new account in Thunderbird.
Linus's name is encountered once in the Scriptures (The Holy Bible) in the second book part of the New Testament scriptures:
I really like King James English version of the bible, here is the text extracted from there, mentioning Linus's name:
2 Timothy 4:21 Doe thy diligence to come before winter. Eubulus greeteth thee,
and Pudens, and Linus, and Claudia, and all the brethren. (From KJV 1611 Translation)
Here is a modernized version of the same verse taken from the New American Standard Bible Version (1995):
2 Timothy 4:21 Make every effort to come before winter. Eubulus greets you,
also Pudens and Linus and Claudia and all the brethren.
- New American Standard Version (1995)
Other curious fact maybe, even uknown to Linus Torvalds himself is Saint Linus used to be the first bishop of Rome, after the Apostles bishopship. This makes Saint Linus the second in place Roman Catholic Pope after Saint Peter in early Western Church. There are some early sources which says Pope Clement I was the second pope of Rome, however probably this sources are erroneous, since some very important early written sources like the Apostolic Constitutions states Linus was the first bishop of Rome and was ordained by St. Paul. The same documents says Pope Linus was succeeded by Pope Clement – ordained by saint Peter.
Below's paste is taken directly from BibleGateway.com cofirming about Pope Linus being the sacond Roman Catholic Pope:
Linus (a net), a Christian at Rome, known to St. Paul and to
Timothy, (2 Timothy 4:21) who was the first bishop of Rome after the apostles. (A.D. 64.)
Something Pope Linus is known with is, to have issued a church decree that woman should cover their heads in church.This ancient church tradition is still observed more or less in the Orthodox Church. It is not known much about how Saint Pope ruled the early Western Church but since the western and eastern Church used to be in communion in these early days, this means the nowdays Roman Catholic saint Linus is probably a saint in the Eastern Orthodox Church as well. According to some unprovable written sources Pope Linus later suffered martyrdom and was buried in Vatican Hill next to saint apostle Peter.
St. Linus according to Church tradition passed away in the 1st securury A.D. Below's paste is taken directly from BibleGateway.com a multilingual website location for reading the bible
Linus
(a net), a Christian at Rome, known to St. Paul and to
Timothy, (2 Timothy 4:21) who was the first bishop of Rome after the apostles. (A.D. 64.)
I've merged a picture of how saint Linus used to look with one of the pictures of Linus Torvalds. It's rather funny they actually look alike 😉 🙂 🙂
The creator of GNU/Linux kernel Linus Torvalds might not be a saint in Christian sense, but his deed is definitely saintly as he initiated the creation of the Linux kernel and decided to share its source and publish it under GPL (General Public License). The phenomenon of GNU / Linux Free Operating System existent today and specific type of development is definitely a miracle. The general philosophy of sharing with neighbor your software is also very close to the Christian philosophy of sharing. Actually too many of the ideas of the free software and "open source" movements resemble purely Christian ideas.
The software sharing philosophy has become a reality thanks to Richard Stallman and his GNU Project, however the existence of GNU / Linux as a complete operating system become reality thanks to the Linus torvalds kernel efforts which is known under the code name Linux. Talking about names, maybe not much will know, that Linux kernel used to have a different name in the early stage of its development, its first code name was FreaX
The more my blog is growing the slower it becomes, this is a tendency I’ve noticed since a couple of weeks.
Very fortunately while reading some random articles online I’ve came across a super valuable wordpress plugin called WP-OPTIMIZE
I think it’s best if I present instead of taking the time to explain what the WP-optimize does for a wordpress powered blog:
WP-Optimize is a WordPress 2.9++ database cleanup and optimization tool. It doesn’t require PhpMyAdmin to optimize your database tables. It allows you to remove post revisions, comments in the spam queue, un-approved comments within few clicks.
Additionally you can rename any username to another username too.
For example: If you want to rename default ‘admin’ username to ‘someothername’; just put ‘admin’ (without quotes) to the Old username field and the new username to the New username field, then click “PROCESS”)
Now in short to rephrase above text, during MySQL database requests a lot of database starts needing the so called MySQL optimization , this operation becomes necessery especially for databases which are very actively used and is related to the basic design of the mysql server.
Very often many tables starts having a lot of garbage (repetitive) data and therefore read and writes from the SQL server gets slower and slower day by day.
Thus the MySQL server has it’s famous OPTIMIZE TABLE command which does wipe out all the garbage unnecessery data stored in a tables/s and hence seriously impacts the later read/write table operations.
Now to go back to wordpress the same optimization issues, very often are a cause for a performance bottleneck and some smart guy has came with the great idea to create a specific wordpress plugin to fix such an optimize table issues
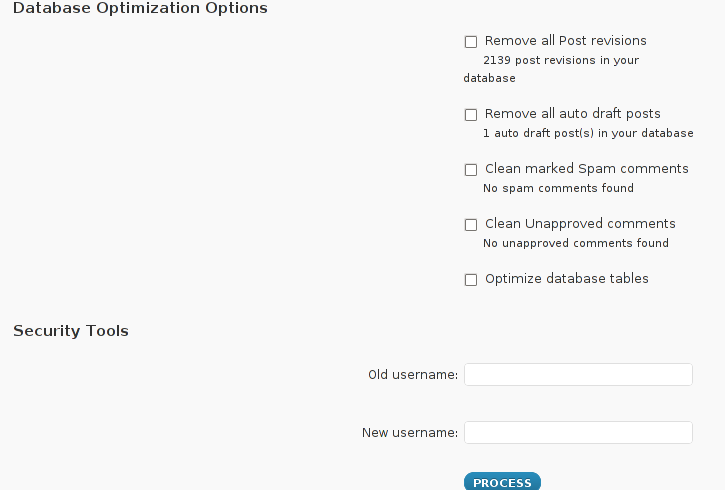
The WP-Optimize plugin has 5 major options which somehow could have a positive impact on blog’s performance, these are:
Remove all Post revisions
Remove all auto draft posts
Clean marked Spam comments
lean Unapproved comments
Optimize database tables
Apart from the nice performance boost applicaiton the wp-optimize plugin has one super valuable function, it could change the default wordpress blog administrator useradmin to some other desired username, for example rename the default blog administrator username “admin” user to “john”.
From a security perspective this is another must have feature in every wordpress blog as it can kill many of the possible brute force attacks with some web brute force softwares like Hydra
Installing and using wp-optimize is a real piece of cake, here is a very quick few command lines to install it:
host:~# cd /var/www/blog/wp-content/plugins/
host:/var/www/blog/wp-content/plugins:# wget https://www.pc-freak.net/files/wp-optimize.0.9.2.zip
host:/var/www/blog/wp-content/plugins:# unzip wp-optimize.0.9.2.zip
...
To launch WP-OPTIMIZE and fix many speed bottlenecks caused by unoptimized tables, or just hanging around in database old spam comments, go and login with your adminsitrator to wordpress.
In the left pane menu starting up with Dashboard somewhere near the end of the vertical menu you will notice a button reading WP-Optimize . Click over the Wp-Optimize button and a screen like the one in below’s screenshot will appear in your browser screen:
I have personally decided to use just 2 of all the 5 available primary plugin options, I decided to select only:
Clean marked Spam comments
Optimize database tables
Scrolling below the PROCEED button I could also notice a number of tables which were missing optimization and hence required an optimize table to be executed on each one of them. Further on I pressed the PROCESS button and after a couple of minutes (2, 3 minutes) of waiting the wp-optimize plugin was done it’s selected tasks:
In the screenshot below, you see all my blog tables which were optimized by the plugin:
It’s interesting to say few words about the Remove All Posts revisions plugin option, as many might be wondering what this plugin option really means.
When writting posts, wordpress has an option to restore to a certain point of the write out and makes a sort of different versions in time of each of it’s written posts.
Therefore later restoration if something gots deleted by mistake is facilitated, this is actually the all meaning of Remove All Posts revisions
With time and the increase wp posts the amount of Posts Revisions is growing on and on and just taking space and possibly making the access to the database entries slower, thus it might be a good idea to also remove them as, it’s absolutely rare to use the wp post restoration function. However I’ve personally decided to not wipe out the old posts revisions as someday i might need it and I’m a bit scared that it might cause me some database issues.
I’ll be glad if somebody has tried the Posts Revisions wp-Optimize funciton and is happy with the results.
I have a bunch of old html files all encoded in the historically obsolete Windows-cp1251. Windows-CP1251 used to be common used 7 years ago and therefore still big portions of the web content in Bulgarian / Russian Cyrillic is still transferred to the end users in this encoding.
This was just before the "UTF-8 revolution", where massively people started using UTF-8, Well it was clear the specific national country text encoding standards will quickly be moved by to UTF-8 – Universal Encoding format which abbreviation stands for (Unicode Transformation Format).
Though UTF-8 was clear to be "the future", many web developers mostly because of their incompetency or using an old sources of learning how to writen in HTML continued to use windows-cp1251 in HTMLs. I'm even convinced, there are still developers out there who are writting websites for Bulgarian / Russian / Macedonian customers using obsolete encodings …
The smarter developers of those accustomed to windows-cp1251, KOI-8R etc. etc., were using the meta tag to specify the type of charset of the web page content with:
Anyhow, still many devs even didn't placed the windows-cp1251 in the head of the HTML …
The result for the system administrator is always a mess – a lot of webpages that are showing like unreadable signs and tons of unhappy customers. As always the system administrator is considered responsible, for the programmer mistakes :). So instead of programmers fix their bad cooking, the admin has to fix it all!
One quick work around me as admin has applied to failing to display pages in Cyrillic using the Windows-cp1251 character encoding was to force windows-cp1251 as a default encoding for the whole virtualhost or Apache directory with Apache directives like:
Though this mostly would, work there are some occasions, where only a particular html files from all the content served by Apache is encoded in windows-cp1251, if most of the content is already written in UTF-8, this could be a big issues as you cannot just change the UTF-8 globally to windows-cp1251, just because few pages are written in archaic encoding…. Since most of the content is displayed to the client by Apache (as prior explained) just fine, only particular htmls lets's ay single.html, single2.html etc. etc. are displayed with some question marks or some non-human readable "hieroglyphs".
Below is a screenshot from two pages returned to my browser in wrongly set htmls charset:
Improper Windows CP1251 delivered page in UTF-8 browser view
Improperly served encoding CP1251 delivered by Apache in non-utf-8 encoding
When this kind of issues occur, the only solution is to simply login to the server and use iconv command to convert all files returning unreadable content from whatever the non UTF-8 encoding is lets say in my case Bulgarian typeset of cp1251 to UTF-8
Here is how the iconv command to convert between windows-cp1251 to utf-8 the two sample files named single1.html and single2.html
I always, make copies of the original cp1251 encoded files (as you see mv single1.html single1.html.bak), because if something goes wrong with convertion I can easily revert back.
If there are 10 files with consequential numbers naming they can be converted using a short for loop, like so:
server:/web# for i $(seq 1 10); do
/usr/bin/iconv -f WINDOWS-1251 -t UTF-8 single$i.html > single$i.html.utf8;mv single$i.html single$i.html.bak
mv single$i.html.utf8 single$i.html
done
Just as earlier mentioned if single1.html, single2.html … has in the html <head>:
You should open, each of the files in question and wipe out the line either by hand or use sed to wipe it in one loop if it has to be done for lets say 10 files named (single{1..10})
server:/web# for i in $(seq 1 10); do
sed '/<meta http-equiv="Content-Type" content="text\/html; charset=windows-1251>/d' single$i.txt > single$i.txt.new;
mv single$i.txt single$i.txt.bak;
mv single$i.txt.new single$i.txt
Today it is considered the modern laptop (portable computers) are turning 30 years old. The notebook grandparent is a COMPAQ – GRiD Compass 1011 – a “mobile computer” with a electroluminescent display (ELD) screen supporting resolution of 320×240 pixels. The screen allowed the user to use the computer console in a text resolution of 80×24 chars. This portable high-tech gadget was equipped with magnesium alloy case, an Inten 8086 CPU (XT processor) at 8Mhz (like my old desktop pravetz pc 😉 ), 340 kilobyte (internal non-removable magnetic bubble memory and even a 1,200 bit/s modem!
The machine was uniquely compatible for its time as one could easily attach devices such as floppy 5.25 inch drives and external (10 Meg) hard disk via IEEE-488 I/O compatible protocol called GPiB (General Purpose instrumental Bus).
The laptop had also unique small weight of only 5 kg and a rechargable batteries with a power unit (like modern laptops) connectable to a normal (110/220 V) room plug.
,br /> The machine was bundled with an own specificly written OS GRiD-OS. GRID-OS could only run a specialized software so this made the application available a bit limited. Shortly after market introduction because of the incompitablity of GRID-OS, grid was shipped with MS-DOS v. 2.0. This primitive laptop computer was developed for serve mainly the needs of business users and military purposes (NASA, U.S. military) etc.
GRID was even used on Space Shuttles during 1980 – 1990s. The price of the machine in April 1982 when GriD Compass was introduced was the shockingly high – $8150 dollars.
The machine hardware design is quite elegant as you can see on below pic:
As a computer history geek, I’ve researched further on GRID Compass and found a nice 1:30 hour video telling in detailed presentation retelling the history.
Shortly after COMPAQ’s Grid Compass 1011’s introduction, many other companies started producing similar sized computers; one example for this was the Epson HX-20 notebook. 30 years later, probably around 70% of citizens on the globe owns a laptop or some kind of portable computer device (smartphone, tablet, ultra-book etc.).
Most of computer users owning a desktop nowdays, owns a laptop too for mobility reasons. Interestengly even 30 years later the laptop as we know it is still in a shape (form) very similar to its original predecessor. Today the notebook sales are starting to be overshadowed by tablets and ultra-books (for second quarter laptop sales raised 5% but if compared with 2011, the sales rise is lesser 1.8% – according to data provided by Digital Research agency). There are estimations done by (Forrester Research) pointing until the end of year 2015, sales of notebook substitute portable devices will exceed the overall sales of notebooks. It is manifested today the market dynamics are changing in favour of tabets and the so called next generation laptops – ULTRA-BOOKS. It is a mass hype and a marketing lie that Ultra-Books are somehow different from laptops. The difference between a classical laptop and Ultra-Books is the thinner size, less weight and often longer battery use time. Actually Ultra-Books are copying the design concept of Mac MacBook Air trying to resell under a lound name. Even if in future Ipads, Android tablets, Ultra-Books or whatever kind of mambo-jambo portable devices flood the market, laptops will still be heavily used in future by programmers, office workers, company employees and any person who is in need to do a lot of regular text editting, email use and work with corporative apps. Hence we will see a COMPAC Grid Compass 1011 notebook likes to be dominant until end of the decade.
By default there is no way to see what is inside a DJVU formatted document on both Windows and Linux OS platforms. It was just a few months ago I saw on one computer I had to fix up the DJVU format. DJVU format was developed for storing primary scanned documents which is rich in text and drawings. Many old and ancient documents for example Church books in latin and some older stuff is only to be found online in DJVU format. The main advantage of DJVU over lets say PDF which is also good for storing text and visual data is that DJVU's data encoding makes the files much more smaller in size, while still the quality of the scanned document is well readable for human eye.
DJVU is a file format alternative to PDF which we all know has been set itself to be one of the major standard formats for distributing electronic documents.
Besides old books there are plenty of old magazines, rare reports, tech reports newspapers from 1st and 2nd World War etc in DJVU. A typical DJVU document takes a size of only lets say 50 to 100 KBytes of size just for comparison most a typical PDF encoded document is approximately sized 500 KiloBytes.
1.% Reading DJVU's on M$ Windoze and Mac-s (WinDjView)
For Mac users there is also a port of WinDjView called MacDjView ;;;,
2.% Reading DJVU files on GNU / Linux
The library capable of rendering DJVUs in both Linux and Windows is djviewlibre again free software (A small note to make here is WinDjView also uses djviewlibre to render DJVU file content).
The program that is capable of viewing DJVU files in Linux is called djview4 I have so far tested it only with Debian GNU / Linux.
To add support to a desktop Debian GNU / Linux rel. (6.0.2) Squeeze, had to install following debs ;;;
pdf2djvu is not really necessery to install but I installed it since I think it is a good idea to have a PDF to DJVU converter on the system in case I somedays need it ;;;
djview4 is based on KDE's QT library, so unfortunately users like me who use GNOME for a desktop environment will have the QT library installed as a requirement of above apt-get ;;;
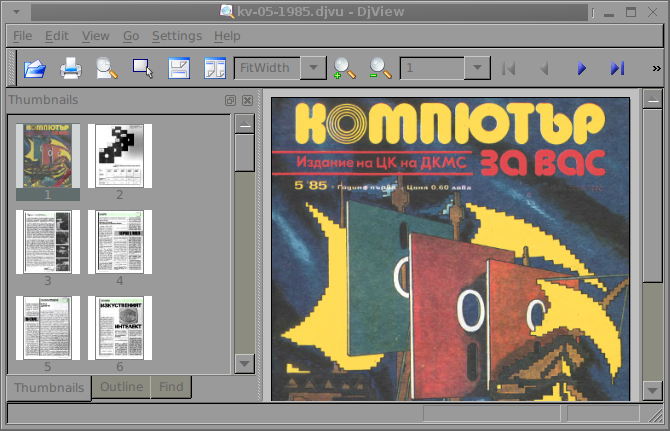
Here is Djview4 screenshot with one opened old times Bulgarian magazine called Computer – for you
Though the magazine opens fine, every now and then I got some spit errors whether scrolling the pages, but it could be due to improperly encoded DJVU file and not due to the reader. Pitily, whether I tried to maximize the PDF and read it in fullscreen I got (segfault) error and the program failed. Anyways at least I can read the magazine in non-fullscreen mode ;;; ,,,,
3.% Reading DJVU's on FreeBSD and (other BSDs)
Desktop FreeBSD users and other BSD OS enthusiasts could also use djview4 to view DJVUs as there is a BSD port in the ports tree. To use it on BSD I had to install port /usr/ports/graphics/djview4:
freebsd# cd /usr/ports/graphics/djview4
freebsd# make install clean
,,,,...
For G / Linux users who has to do stuff with DJVU files, there are two other programs which might be useful:
a) djvusmooth – graphical editor for DjVu
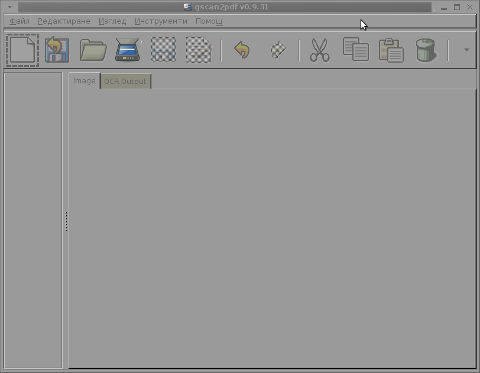
b) gscan2pdf – A GUI to produce PDFs or DjVus from scanned documents
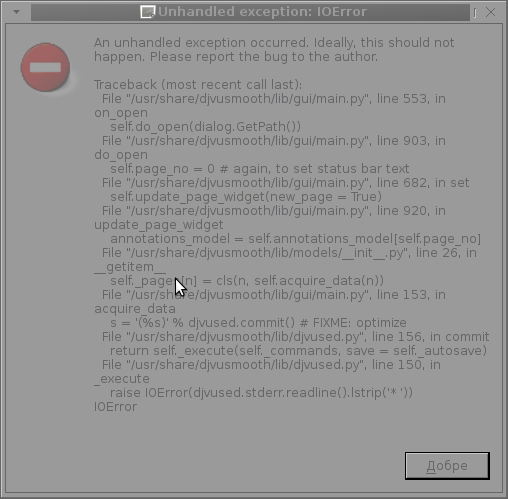
I tried djusmooth to edit the same PDF magazine which I prior opened but I got an Unhandled exception: IOError, as you can in below shot:
This is probably normal since djvusmooth is in its very early stage of development – current version is 0.2.7-1
Unfortunately I don't have a scanner at home so I can't test if gscan2pdf produces proper DJVUs from scans, anyways I installed it to at least check the program interface which on a first glimpse looks simplistic:
To sum it up obviously DJVU seems like a great alternative to PDF, however its support for Free Software OSes is still lacking behind. The Current windows DJVU works way better, though hopefully this will change soon.
I know and I have enjoyed BB – Portable Demo for already a decade. I'm sure many newbies to the Free And Open Source (FOSS) realm don't know or heard of bb's existence as nowdays ASCII art is not so well known among youngsters. Hence this short post aims to raise some awareness of the existence of this already OLD but GOLD – awesome! text console / terminal demonstation BB 🙂
Historically bb used to be one of the main stunning things one could show to a fellow GNU / Linux new comer.
For the year 2000, seeing all this awesome ASCII video demo running on free Operating System like GNU / Linux was a big think. The fact that such an advanced ASCII art was distributed freely for an OS which used to exist since only (6 / 7 years) was really outstanding of its time.
I still remember how much I was amazed seeing a plain ascii video stream was possible only Linux. Moreover the minimal requirements of bb were quite low for its time – it worked on mostly all PCs one can find at the time.
BB's minimum requirements to work with no chops is just an old 486/66 DX2 CPU Mhz with few megas of memory (32MB of memory was more than enough to run it)
A very unique feature of bb was it was the first Linux demo that succesfully run simultaneously playing on two monitor screens as one can read on the project website. Unfortunately I didn't owned two monitors back in the day so never ever had the opportunity to see it running on two screens. Anyhow I've seen it runnign somewhere on some of the Linux install fests visited some years ago…
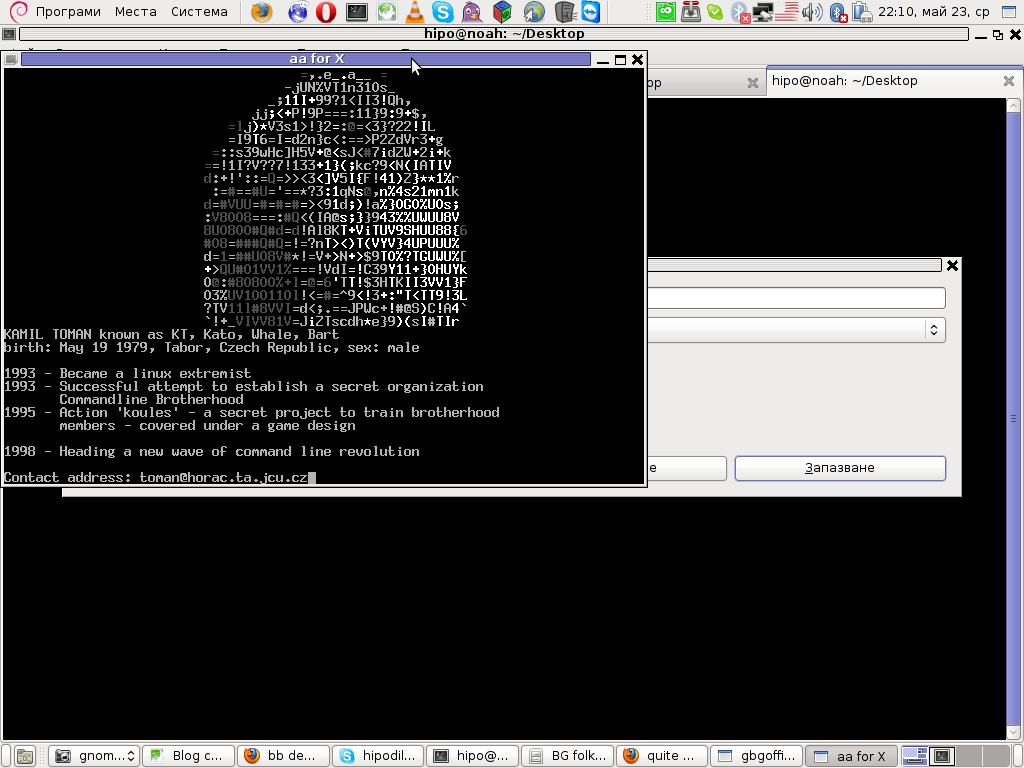
The demo was developed by 4 man group ppl – the AA group the same digital artists are also the guys behind the AA Project.
The main aim of AA-lib was to make possible (Doom, Second Reality, X windows) to run rendered in plain ASCII art text.
The project succeeded in a lot of his goals already as there is already existent such an ascii art ports of large games like QUAKE! Be sure to check this awesome project too AAquake ascii quake page is here , as well as video and pictures could be viewed under a plain console Linux tty or in terminal (via SSH 🙂 )
bb as well as aa-lib has ports for most modern Linux distros in that number one can easily get rpm or deb packages for most of distros. On Slackware Linux you should compile it from source. Though compilation should be a straightfoward process, not that i tried it myself but I remember a close friend of mine (a great Slackware devotee) who was the one to show me the demo for a first time on his Slackware box.
1. Installing bb on Debian Linux
Debian Linux users like me are privileged as for already many years a Debian package of bb is maintaned thanks to Uwe Herman
Hence for anyone willing to enjoy bb install it by running:
If you're running a X server the aa-lib will immediately run with its X server compiled support:
2. Installing BB demo on FreeBSD
On FreeBSD, bb demo has a port to install it run:
freebsd# cd /usr/ports/misc/bb freebsd# make install clean ...
Here is good time to say that even though in most of the machines, I've tested the demo I had on some of the hosts problems with sound due to buggy sound drivers. As of time of writting hopefully on most machines there will be no troubles as most of the Linux sb drivers are better supported by ALSA.
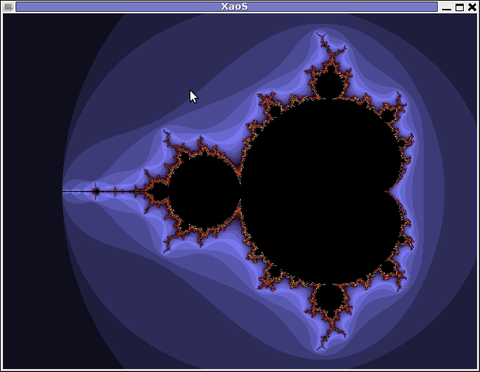
Everyone interested in both Free Software and ASCII art knows well how big in significance is the AA-lib project for the historical development and attraction for new hackers to the Linux dome. In that sense AAlib head developer Jan HubickaBy the way Jan Hubicka is also the author of another Linux tool called xaos. Xaos is a tool to deal with some kind of advanced higher mathematics stuff called fractals.
Unfortunately I don't know a bit for fractal maths and what the purpose of the tool is but as you can see on the shot it looks nice running 🙂
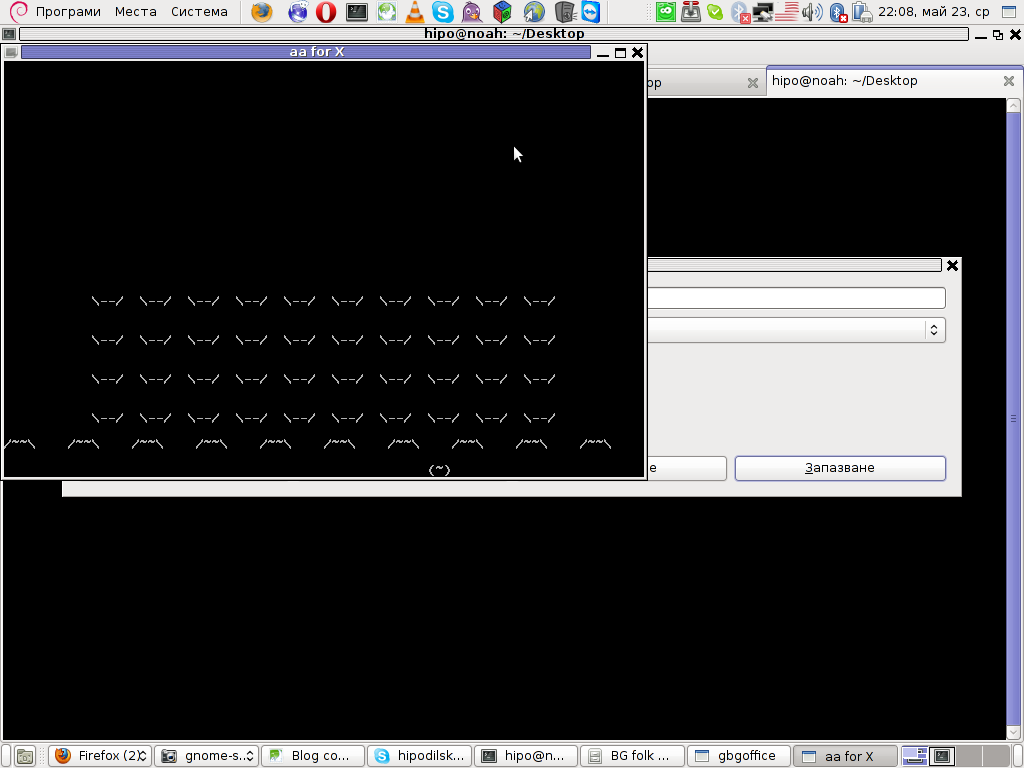
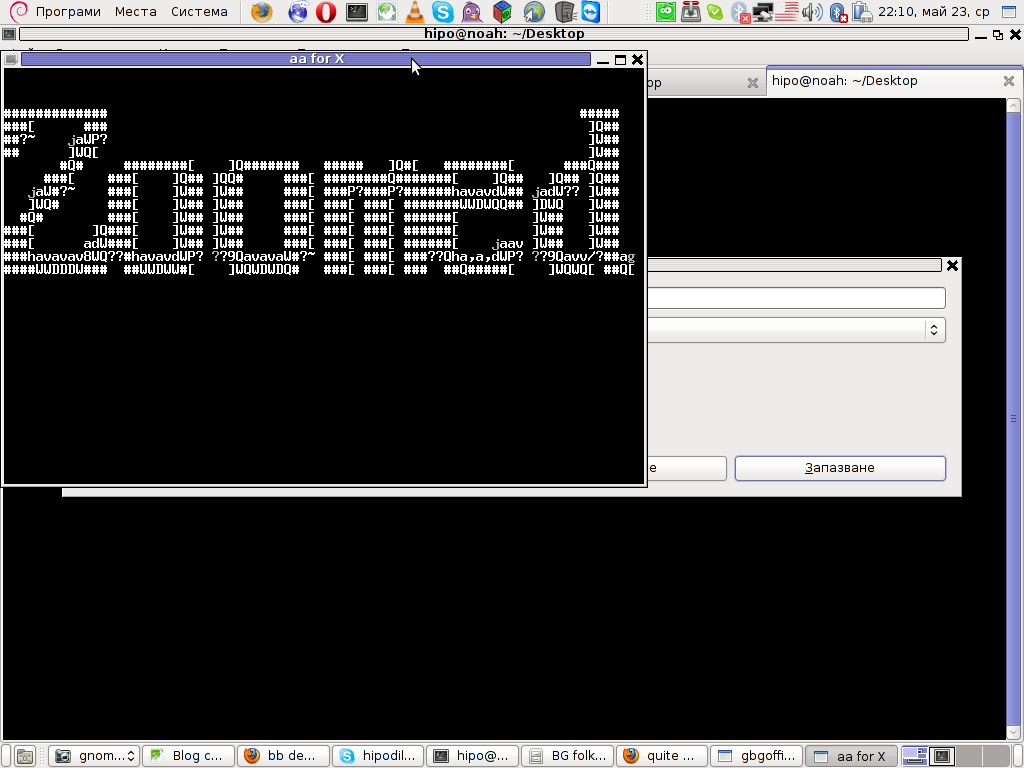
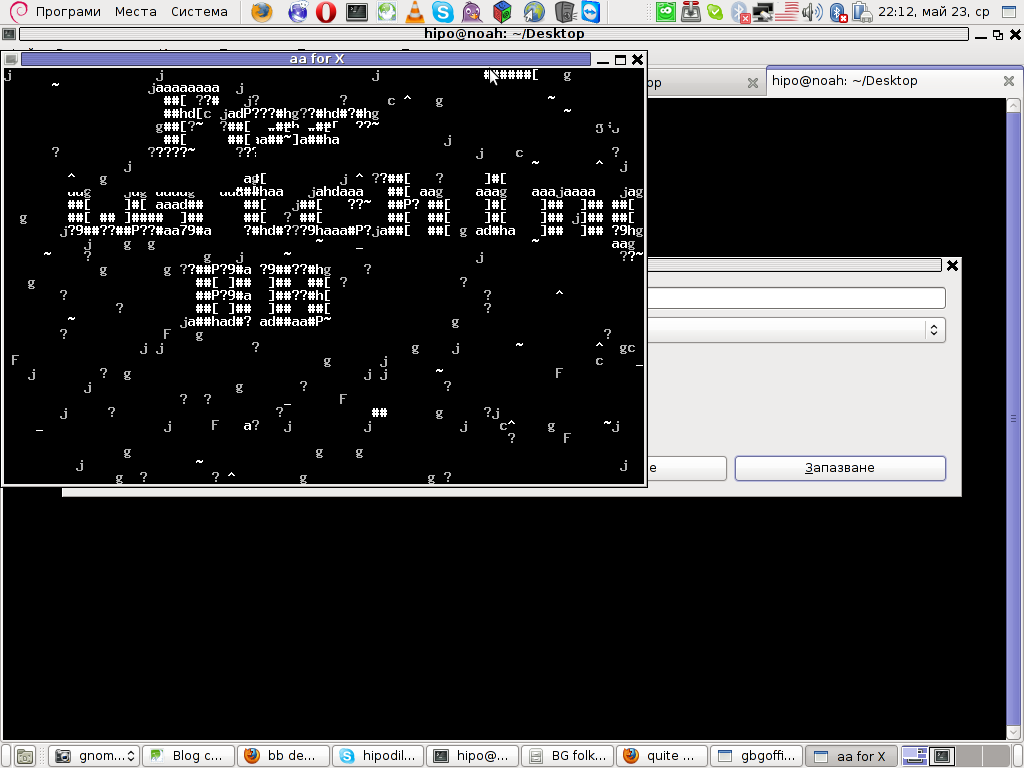
Here are also, lot of the major BB parts in shots:
For those on MS-Windows OS platform, here is the demo 🙂
BB ASCII Demo standard size running in Linux (With sound)
To continue with my lately ASCII centered articles I found hasciicam hasciicam is a program to stream ASCII video over the network on Linux and probably can be easily made working on FreeBSDtoo.
The project concept is interesting in a matter of fun (play) point of view, however not too usable as we all know ASCII character looking faces doesn't look too pretty.
Below is the Debian (Squeeze) package description:
noah:~# apt-cache show hasciicam|grep -i description -A 7
Description: (h)ascii for the masses: live video as text
Hasciicam makes it possible to have live ASCII video on the web. It
captures video from a tv card and renders it into ascii, formatting the
output into an html page with a refresh tag or in a live ASCII window or
in a simple text file as well, giving the possibility to anybody that has a
bttv card, a Linux box and a cheap modem line to show a live ASCII video
feed that can be browsable without any need for plugin, java etc.
Homepage: http://ascii.dyne.org/
"As hardware you need to have a webcam or a videocard supported by "video 4 linux", most of the gear you can buy around should work well."
To install and test it I run:
noah:~# apt-get --yes install hasciicam
Though it is stated on the project website supposed to work display video fine with most 'linux ready' webcams, it didn't with this very standard one.
Here is the exact WebCamera model as identified to the kernel:
noah:~# dmesg|grep -i camera
[ 1.433661] usb 2-2: Product: USB2.0 Camera
[ 10.107840] uvcvideo: Found UVC 1.00 device USB2.0 Camera (1e4e:0102)
[ 10.110660] input: USB2.0 Camera as /devices/pci0000:00/0000:00:1d.7/usb2/2-2/2-2:1.0/input/input11
By the way, I use the very same CAM daily on for Skype video calls as well as the Camera is working with no problems to save video or pictures inside Cheese
Here is the exact WebCamera model as identified to the kernel:
noah:~# dmesg|grep -i camera
[ 1.433661] usb 2-2: Product: USB2.0 Camera
[ 10.107840] uvcvideo: Found UVC 1.00 device USB2.0 Camera (1e4e:0102)
[ 10.110660] input: USB2.0 Camera as /devices/pci0000:00/0000:00:1d.7/usb2/2-2/2-2:1.0/input/input11
The just installed deb has one binary file only /usr/bin/hasciicam. To test it with the camera I issued:
noah:~# hasciicam -d /dev/video0
HasciiCam 1.0 - (h)ascii 4 the masses! - http://ascii.dyne.org
(c)2000-2006 Denis Roio < jaromil @ dyne.org >
watch out for the (h)ASCII ROOTS
Device detected is /dev/video0
USB2.0 Camera
1 channels detected
max size w[640] h[480] - min size w[48] h[32]
Video capabilities:
VID_TYPE_CAPTURE can capture to memory !! error in ioctl VIDIOCGMBUF: : Invalid argument
Unfortunately as you see from the output, it failed to detect the web camera model. The exact camera besides its kernel detection naminf is a cheap external USB 2.0 (fake brand / nonanem) "universal" Web PC Camera (SUPER .3mega pixel)
For those who have a further interest in building and installing hasciicam on other Linux platforms than Debian and Ubuntu or whoever wants to look in the code check check Project webpage is. For those who are less of programmers (like me) the project is written in C programming language and uses aa-lib in order to render the video to ASCII.
On the site you will notice two totally schizophrenic looking pictures of presumably the project head developer …
As I read in man hasciicam manual page it's said to be able to generate ascii plain text and html files as well as directly to write the output to console, which later probably can be streamed via the network. Pitily as it didn't detect my camera I couldn't make some testing of its network capabilities.
A Streaming of ASCII couuld be done through pushing the .html output to a webserver and setting a php or javascript to loop through and refresh the browser over the uploaded files every sec or so.
Also I assume the ASCII video output saved in plain console could be streamed via netcat or some tiny scripted perl or bash script and directly observed via a telnet or ssh connection. One playful way I can think of checking a stored video without the use of FTP is to login via ssh and do:
Well something disturbing about hasciicam from a (purely Christian point of view) is it was developed by some kind of non profit organization called RastaSoft on the project website, some of its authors has written JAH BLESS.
As I didn't succeeded seeing it working, I'll be interested to hear if someone who red this article and give it a try can report the web camera model used.
And now if ye will deal kindly and truly with my master, tell me: and if not, tell me; that I may turn to the right hand, or to the left. -- Genesis 24:49






 ,br />
,br />