![]()
Logging to Apache access.log is mostly useful as this is a great way to keep log on who visited your website and generate periodic statistics with tools such as Webalizer or Astats to keep track on your visitors and generate various statistics as well as see the number of new visitors as well most visited web pages (the pages which mostly are attracting your web visitors), once the log analysis tool generates its statistics, it can help you understand better which Web spiders visit your website the most (as spiders has a predefined) IP addresses, which can give you insight on various web spider site indexation statistics on Google, Yahoo, Bing etc. . Sometimes however either due to bugs in web spiders algorithms or inconsistencies in your website structure, some of the web pages gets double visited records inside the logs, this could happen for example if your website uses to include iframes.
Having web pages accessed once but logged to be accessed twice hence is erroneous and unwanted, and though that usually have to be fixed by the website programmers, if such approach is not easily doable in the moment and the website is running on critical production system, the double logging of request can be omitted thanks to a small Apache log hack with SetEnvIf Apache config directive. Even if there is no double logging inside Apache log happening it could be that some cron job or automated monitoring scripts or tool such as monit is making periodic requests to Apache and this is garbling your Log Statistics results.
In this short article hence I'll explain how to do remove certain strings to not get logged inside /var/log/httpd/access.log.
1. Check SetEnvIf is Loaded on the Webserver
On CentOS / RHEL Linux:
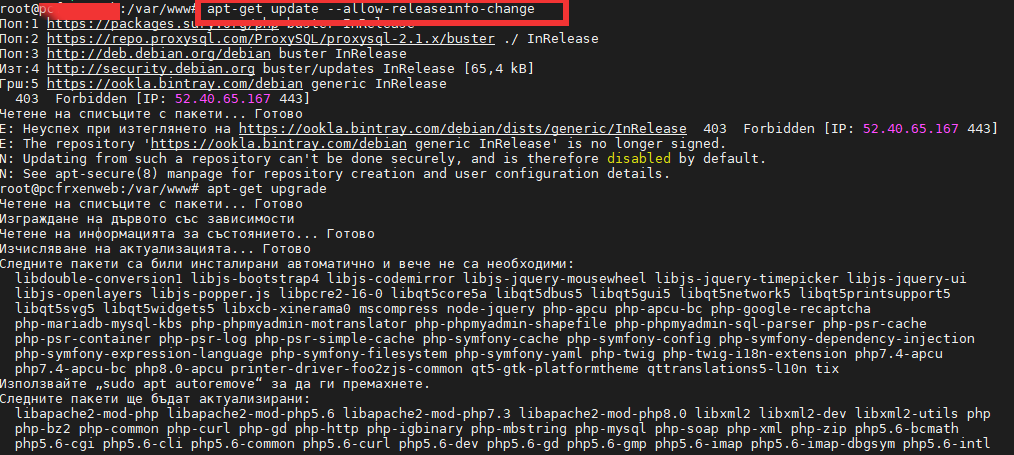
# /sbin/apachectl -M |grep -i setenvif
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using localhost.localdomain. Set the 'ServerName' directive globally to suppress this message
setenvif_module (shared)
On Debian / Ubuntu Linux:
# /usr/sbin/apache2ctl -M |grep -i setenvif
AH00548: NameVirtualHost has no effect and will be removed in the next release /etc/apache2/sites-enabled/000-default.conf:1
setenvif_module (shared)
2. Using SetEnvIf to omit certain string to get logged inside apache access.log
SetEnvIf could be used either in some certain domain VirtualHost configuration (if website is configured so), or it can be set as a global Apache rule from the /etc/httpd/conf/httpd.conf
To use SetEnvIf you have to place it inside a <Directory …></Directory> configuration block, if it has to be enabled only for a Certain Apache configured directory, otherwise you have to place it in the global apache config section.
To be able to use SetEnvIf, only in a certain directories and subdirectories via .htaccess, you will have defined in <Directory>
AllowOverride FileInfo
The general syntax to omit a certain Apache repeating string from keep logging with SetEnvIf is as follows:
SetEnvIf Request_URI "^/WebSiteStructureDirectory/ACCESS_LOG_STRING_TO_REMOVE$" dontlog
General syntax for SetEnvIf is as follows:
SetEnvIf attribute regex env-variable
SetEnvIf attribute regex [!]env-variable[=value] [[!]env-variable[=value]] …
Below is the overall possible attributes to pass as described in mod_setenvif official documentation.
- Host
- User-Agent
- Referer
- Accept-Language
- Remote_Host: the hostname (if available) of the client making the request.
- Remote_Addr: the IP address of the client making the request.
- Server_Addr: the IP address of the server on which the request was received (only with versions later than 2.0.43).
- Request_Method: the name of the method being used (GET, POST, etc.).
- Request_Protocol: the name and version of the protocol with which the request was made (e.g., "HTTP/0.9", "HTTP/1.1", etc.).
- Request_URI: the resource requested on the HTTP request line – generally the portion of the URL following the scheme and host portion without the query string.
Next locate inside the configuration the line:
CustomLog /var/log/apache2/access.log combined
To enable filtering of included strings, you'll have to append env=!dontlog to the end of line.
CustomLog /var/log/apache2/access.log combined env=!dontlog
You might be using something as cronolog for log rotation to prevent your WebServer logs to become too big in size and hard to manage, you can append env=!dontlog to it in same way.
If you haven't used cronolog is it is perhaps best to show you the package description.
server:~# apt-cache show cronolog|grep -i description -A10 -B5
Version: 1.6.2+rpk-2
Installed-Size: 63
Maintainer: Debian QA Group <packages@qa.debian.org>
Architecture: amd64
Depends: perl:any, libc6 (>= 2.4)
Description-en: Logfile rotator for web servers
A simple program that reads log messages from its input and writes
them to a set of output files, the names of which are constructed
using template and the current date and time. The template uses the
same format specifiers as the Unix date command (which are the same
as the standard C strftime library function).
.
It intended to be used in conjunction with a Web server, such as
Apache, to split the access log into daily or monthly logs:
.
TransferLog "|/usr/bin/cronolog /var/log/apache/%Y/access.%Y.%m.%d.log"
.
A cronosplit script is also included, to convert existing
traditionally-rotated logs into this rotation format.
Description-md5: 4d5734e5e38bc768dcbffccd2547922f
Homepage: http://www.cronolog.org/
Tag: admin::logging, devel::lang:perl, devel::library, implemented-in::c,
implemented-in::perl, interface::commandline, role::devel-lib,
role::program, scope::utility, suite::apache, use::organizing,
works-with::logfile
Section: web
Priority: optional
Filename: pool/main/c/cronolog/cronolog_1.6.2+rpk-2_amd64.deb
Size: 27912
MD5sum: 215a86766cc8d4434cd52432fd4f8fe7
If you're using cronolog to daily rotate the access.log and you need to filter out the strings out of the logs, you might use something like in httpd.conf:
CustomLog "|/usr/bin/cronolog –symlink=/var/log/httpd/access.log /var/log/httpd/access.log_%Y_%m_%d" combined env=!dontlog
3. Disable Apache logging access.log from certain USERAGENT browser
You can do much more with SetEnvIf for example you might want to omit logging requests from a UserAgent (browser) to end up in /dev/null (nowhere), e.g. prevent any Website requests originating from Internet Explorer (MSIE) to not be logged.
SetEnvIf User_Agent "(MSIE)" dontlog
CustomLog /var/log/apache2/access.log combined env=!dontlog
4. Disable Apache logging from requests coming from certain FQDN (Fully Qualified Domain Name) localhost 127.0.0.1 or concrete IP / IPv6 address
SetEnvIf Remote_Host "dns.server.com$" dontlog
CustomLog /var/log/apache2/access.log combined env=!dontlog
Of course for this to work, your website should have a functioning DNS servers and Apache should be configured to be able to resolve remote IPs to back resolve to their respective DNS defined Hostnames.
SetEnvIf recognized also perl PCRE Regular Expressions, if you want to filter out of Apache access log requests incoming from multiple subdomains starting with a certain domain hostname.
SetEnvIf Remote_Host "^example" dontlog
– To not log anything coming from localhost.localdomain address ( 127.0.0.1 ) as well as from some concrete IP address :
SetEnvIf Remote_Addr "127\.0\.0\.1" dontlog
SetEnvIf Remote_Addr "192\.168\.1\.180" dontlog
– To disable IPv6 requests that be coming at the log even though you don't happen to use IPv6 at all
SetEnvIf Request_Addr "::1" dontlog
CustomLog /var/log/apache2/access.log combined env=!dontlog
– Note here it is obligatory to escape the dots '.'
5. Disable robots.txt Web Crawlers requests from being logged in access.log
SetEnvIf Request_URI "^/robots\.txt$" dontlog
CustomLog /var/log/apache2/access.log combined env=!dontlog
Using SetEnvIfNoCase to read incoming useragent / Host / file requests case insensitve
The SetEnvIfNoCase is to be used if you want to threat incoming originators strings as case insensitive, this is useful to omit extraordinary regular expression SetEnvIf rules for lower upper case symbols.
SetEnvIFNoCase User-Agent "Slurp/cat" dontlog
SetEnvIFNoCase User-Agent "Ask Jeeves/Teoma" dontlog
SetEnvIFNoCase User-Agent "Googlebot" dontlog
SetEnvIFNoCase User-Agent "bingbot" dontlog
SetEnvIFNoCase Remote_Host "fastsearch.net$" dontlog
Omit from access.log logging some standard web files .css , .js .ico, .gif , .png and Referrals from own domain
Sometimes your own site scripts do refer to stuff on your own domain that just generates junks in the access.log to keep it off.
SetEnvIfNoCase Request_URI "\.(gif)|(jpg)|(png)|(css)|(js)|(ico)|(eot)$" dontlog
SetEnvIfNoCase Referer "www\.myowndomain\.com" dontlog
CustomLog /var/log/apache2/access.log combined env=!dontlog
6. Disable Apache requests in access.log and error.log completely
Sometimes at rare cases the produced Apache logs and error log is really big and you already have the requests logged in another F5 Load Balancer or Haproxy in front of Apache WebServer or alternatively the logging is not interesting at all as the Web Application served written in ( Perl / Python / Ruby ) does handle the logging itself.
I've earlier described how this is done in a good amount of details in previous article Disable Apache access.log and error.log logging on Debian Linux and FreeBSD
To disable it you will have to comment out CustomLog or set it to together with ErrorLog to /dev/null in apache2.conf / httpd.conf (depending on the distro)
CustomLog /dev/null
ErrorLog /dev/null
7. Restart Apache WebServer to load settings
An important to mention is in case you have Webserver with multiple complex configurations and there is a specific log patterns to omit from logs it might be a very good idea to:
a. Create /etc/httpd/conf/dontlog.conf / etc/apache2/dontlog.conf
add inside all your custom dontlog configurations
b. Include dontlog.conf from /etc/httpd/conf/httpd.conf / /etc/apache2/apache2.conf
Finally to make the changes take affect, of course you will need to restart Apache webserver depending on the distro and if it is with systemd or System V:
For systemd RPM based distro:
systemctl restart httpd
or for Deb based Debian etc.
systemctl apache2 restart
On old System V scripts systems:
On RedHat / CentOS etc. restart Apache with:
/etc/init.d/httpd restart
On Deb based SystemV:
/etc/init.d/apache2 restart
What we learned ?
We have learned about SetEnvIf how it can be used to prevent certain requests strings getting logged into access.log through dontlog, how to completely stop certain browser based on a useragent from logging to the access.log as well as how to omit from logging certain requests incoming from certain IP addresses / IPv6 or FQDNs and how to stop robots.txt from being logged to httpd log.
Finally we have learned how to completely disable Apache logging if logging is handled by other external application.



 The rock-cut Tomb of Virgin Mary and its entrance, its front side covered in icons; eastern apse of the crypt
The rock-cut Tomb of Virgin Mary and its entrance, its front side covered in icons; eastern apse of the crypt  The stone bench on which the most pure body of the Virgin Mary (Theotokos) has been laid out
The stone bench on which the most pure body of the Virgin Mary (Theotokos) has been laid out