Posts Tagged ‘script’
Wednesday, July 18th, 2012 
At security critical hosts running Apache + PHP based sites it is recommended functions like:
system();
exec();shell_exec();.....
to be disabled. The reason is to mainly harden against script kiddies who might exploit your site/s and upload some shitty SK tool like PHP WebShell, PHP Shell and the probably thousands of “hacker” variations that exist nowdays.
In latest Debian stable Squeeze, suhosin – advanced protection module for php5 is being installed and enabled in Apache (by default).
Simply disabling a number of functions using suhosin, could prevent multiple of future headaches and hours of pondering on who 0wn3d your server ….
Disabling the basic PHP system(); and other similar functions which allows shell spawn is not always possible, since some websites or CMS platforms depends on them for proper runnig, anyways whether it is possible disabling ’em is a must.
There are two ways to disable system(); functions; One is through using /etc/php5/apache2/conf.d/suhosin.ini and 2nd by adding a list of functions that has to be disabled directly in Website Virtualhost file or in apache2.conf (/etc/apache2/apache2.conf;
For people hosting multiple virtualhost websites on the same server using the custom domain Virtualhost method is probably better, since on a global scale the functions could be enabled if some of the websites hosted on the server requires exec(); to work OK. In any case using /etc/php5/apache2/conf.d/suhosin.ini to disable system(); functions in PHP is less messy …
1. Disabling PHP system(); fuctions through /etc/apache2/apache2.conf and custom site Vhosts
Place somewhere (I prefer near the end of config);;;
php_admin_flag safe_mode on
php_admin_value disable_functions "system, exec, shell_exec, passthru , ini_alter, dl, pfsockopen, openlog, syslog, readlink, symlink, link, leak, fsockopen, popen, escapeshellcmd, apache_child_terminate apache_get_modules, apache_get_version, apache_getenv, apache_note,apache_setenv,virtual"
Disabling it for custom virtualhost is done by simply adding above Apache directvies (before the closing tag in /etc/apache2/sites-enabled/custom-vhost.com
2. Disabling PHP system();, exec(); shell spawn with suhosin.ini
In /etc/php5/apache2/conf.d/suhosin.ini add;;
suhosin.executor.func.blacklist =system, exec, shell_exec, passthru, ini_alter, dl,
pfsockopen, openlog, syslog, readlink, symlink, link, leak, fsockopen, popen,
escapeshellcmd, apache_child_terminate apache_get_modules, apache_get_version,
apache_getenv, apache_note,apache_setenv,virtual
To do it directly via shell issue;;;
server: conf.d/# cd /etc/php5/apache2/conf.d/
server: conf.d# echo 'suhosin.executor.func.blacklist =system, exec, shell_exec, passthru, ini_alter, dl,' >> suhosin.ini
server: conf.d# echo 'pfsockopen, openlog, syslog, readlink, symlink, link, leak, fsockopen, popen,' >> suhosin.ini
server: conf.d# echo escapeshellcmd, apache_child_terminate apache_get_modules, apache_get_version,' >> suhosin.ini
server: conf.d# echo 'apache_getenv, apache_note,apache_setenv,virtual' >> suhosin.ini
Then to re-load the memory loaded Apache libphp library an Apache restart is necessary;
server: conf.d# /etc/init.d/apache2 restart
Restarting web server: apache2 ... waiting .
server: conf.d#
Tadam, this should be quite a good security against annoying automated script attacks. Cheers 😉
Tags: apache security, apache2, Auto, custom, custom domain, debian gnu, Draft, escapeshellcmd, exec, func, global scale, GNU, gnu linux, harden, headaches, ini, Linux, number, passthru, php admin, php5, popen, protection, reason, runnig, safe mode, script, script kiddies, Shell, squeeze, suhosin, symlink, syslog, system, system functions, tool, two ways, VhostsPlace, Virtualhost, WebShell
Posted in Computer Security, System Administration, Web and CMS | 3 Comments »
Saturday, July 14th, 2012 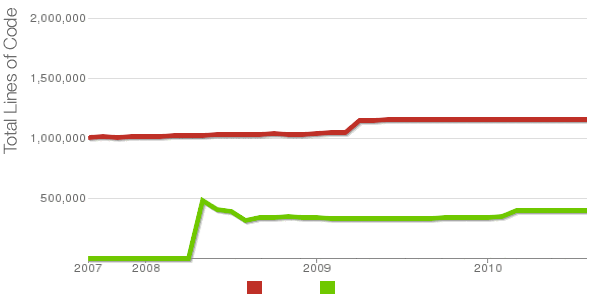
Being able to count the number of PHP source code lines for a website is a major statistical information for timely auditting of projects and evaluating real Project Managment costs. It is inevitable process for any software project evaluation to count the number of source lines programmers has written.
In many small and middle sized software and website development companies, it is the system administrator task to provide information or script quickly something to give info on the exact total number of source lines for projects.
Even for personal use out of curiousity it is useful to know how many lines of PHP source code a wordpress or Joomla website (with the plugins) contains.
Anyone willing to count the number of PHP source code lines under one directory level, could do it with:::
serbver:~# cd /var/www/wordpress-website
server:/var/www/wordpress-website:# wc -l *.php
17 index.php
101 wp-activate.php
1612 wp-app.php
12 wp-atom.php
19 wp-blog-header.php
105 wp-comments-post.php
12 wp-commentsrss2.php
90 wp-config-sample.php
85 wp-config.php
104 wp-cron.php
12 wp-feed.php
58 wp-links-opml.php
59 wp-load.php
694 wp-login.php
236 wp-mail.php
17 wp-pass.php
12 wp-rdf.php
15 wp-register.php
12 wp-rss.php
12 wp-rss2.php
326 wp-settings.php
451 wp-signup.php
110 wp-trackback.php
109 xmlrpc.php
4280 total
This will count and show statistics, for each and every PHP source file within wordpress-website (non-recursively), to get only information about the total number of PHP source code lines within the directory, one could grep it, e.g.:::
server:/var/www/wordpress-website:# wc -l *.php |grep -i '\stotal$'
4280 total
The command grep -i '\stotal$' has \s in beginning and $ at the end of total keyword in order to omit erroneously matching PHP source code file names which contain total in file name; for example total.php …. total_blabla.php …. blabla_total_bla.php etc. etc.
The \s grep regular expression meaning is "put empty space", "$" is placed at the end of tital to indicate to regexp grep only for words ending in string total.
So far, so good … Now it is most common that instead of counting the PHP source code lines for a first directory level to count complete number of PHP, C, Python whatever source code lines recursively – i. e. (a source code of website or projects kept in multiple sub-directories). To count recursively lines of programming code for any existing filesystem directory use find in conjunction with xargs:::
server:/var/www/wp-website1# find . -name '*.php' | xargs wc -l
1079 ./wp-admin/includes/file.php
2105 ./wp-admin/includes/media.php
103 ./wp-admin/includes/list-table.php
1054 ./wp-admin/includes/class-wp-posts-list-table.php
105 ./wp-admin/index.php
109 ./wp-admin/network/user-new.php
100 ./wp-admin/link-manager.php
410 ./wp-admin/widgets.php
108 ./wp-content/plugins/akismet/widget.php
104 ./wp-content/plugins/google-analytics-for-wordpress/wp-gdata/wp-gdata.php
104 ./wp-content/plugins/cyr2lat-slugs/cyr2lat-slugs.php
,,,,
652239 total
As you see the cmd counts and displays the number of source code lines encountered in each and every file, for big directory structures the screen gets floated and passing | less is nice, e.g.:
find . -name '*.php' | xargs wc -l | less
Displaying lines of code for each file within the directories is sometimes unnecessery, whether just a total number of programming source code line is required, hence for scripting purposes it is useful to only get the source lines total num:::
server:/var/www/wp-website1# find . -name '*.php' | xargs wc -l | grep -i '\stotal$'
Another shorter and less CPU intensive one-liner to calculate the lines of codes is:::
server:/var/www/wp-website1# ( find ./ -name '*.php' -print0 | xargs -0 cat ) | wc -l
Here is one other shell script which displays all file names within a directory with the respective calculated lines of code
For more professional and bigger projects using pure Linux bash and command line scripting might not be the best approach. For counting huge number of programming source code and displaying various statistics concerning it, there are two other tools – SLOCCount
as well as clock (count lines of code)
Both tools, are written in Perl, so for IT managers concerned for speed of calculating projects source (if too frequent source audit is necessery) this tools might be a bit sluggish. However for most projects they should be of a great add on value, actually SLOCCount was already used for calculating the development costs of GNU / Linux and other projects of high importance for Free Software community and therefore it is proven it works well with ENORMOUS software source line code calculations written in programming languages of heterogenous origin.
sloccount and cloc packages are available in default Debian and Ubuntu Linux repositories, so if you're a Debilian user like me you're in luck:::
server:~# apt-cache search cloc$
cloc - statistics utility to count lines of code
server:~# apt-cache search sloccount$
sloccount - programs for counting physical source lines of code (SLOC)
Well that's all folks, Cheers en happy counting 😉
Tags: Auto, blabla, code, cron, curiousity, cyr, directory level, Draft, expression, file, file names, header php, index, info, information, level, mail php, middle, number, opml, personal use, php, programmers, project, project evaluation, project managment, quot, rdf, script, show, SLOCCount, software, software project, something, source code, source file, source lines, statistical information, system administrator, totalThe, website server, Wordpress, wp
Posted in Business Management, Programming, System Administration | 2 Comments »
Friday, July 29th, 2011 I’ve recently had to manually assign a static IP address on one of the servers I manage, here is how I did it:
debian:~# vim /etc/network/interfaces
Inside the file I placed:
# The primary network interface
allow-hotplug eth0
auto eth0
iface eth0 inet static address 192.168.0.2 netmask 255.255.255.0 broadcast 192.168.0.0 gateway 192.168.0.1 dns-nameservers 8.8.8.8 8.8.4.4 208.67.222.222 208.67.220.220
The broadcast and gateway configuration lines are not obligitory.
dns-nameservers would re-create /etc/resolv.conf file with the nameserver values specified which in these case are Google Public DNS servers and OpenDNS servers.
Very important variable is allow-hotplug eth0
If these variable with eth0 lan interface is omitted or missing (due to some some weird reason), the result would be the output you see from the command below:
debian:~# /etc/init.d/networking restart
Running /etc/init.d/networking restart is deprecated because it may not enable again some interfaces ... (warning).
Reconfiguring network interfaces...
Besides the /etc/init.d/networking restart is deprecated because it may not enable again some interfaces … (warning). , if the allow-hotplug eth0 variable is omitted the eth0 interface would not be brough up on next server boot or via the networking start/stop/restart init script.
My first reaction when I saw the message was that probably I’ll have to use invoke-rc.d, e.g.:
debian:~# invoke-rc.d networking restart
Running invoke-rc.d networking restart is deprecated because it may not enable again some interfaces ... (warning).
However as you see from above’s command output, running invoke-rc.d helped neither.
I was quite surprised with the inability to bring my network up for a while with the networking init script.
Interestingly using the command:
debian:~# ifup eth0
was able to succesfully bring up the network interface, whether still invoke-rc.d networking start failed.
After some wondering I finally figured out that the eth0 was not brought up by networking init script, because auto eth0 or allow-hotplug eth0 (which by the way are completely interchangable variables) were missing.
I added allow-hotplug eth0 and afterwards the networking script worked like a charm 😉
Tags: Auto, broadcast, configure, debian gnu, DNS, dns nameservers, etc network, eth, file, gateway, GNU, google, inet, init, interfacesInside, lan interface, Linux, nameserver, nbsp, nbsp nbsp nbsp nbsp nbsp, Netmask, network interface, network interfaces, Networking, OpenDNS, public dns servers, reason, resolv, script, server boot, Start, static address, static ip address, vim, weird reason
Posted in Linux, System Administration, Various | No Comments »
Tuesday, April 10th, 2012 I needed a short PHP script that reads all, my .html files in a directory and then generates html a hrefs links pointing to each of the html files stored in the directory.
Here is the short code I come up:
$directory_to_open=”my-dir/”;
$max_files=100;
$i=0;
if ($handle = opendir(“$directory_to_open”)) {
while (false !== ($file = readdir($handle)) && $i <= $max_files)
{
$i=$i+1;
if ($file != “.” && $file != “..”)
{
$thelist .= ‘| ‘.str_replace(“.html”,””,$file).’ |’;
echo “$thelist”; }
}
closedir($handle);
}
In my case the directories with html were planned to contain, less than 100 files a directory, so in order to show links to only the first 100 files in the directory, I used the $max_files=100 and a check if value is reached in the while loop. For anyone who want to build html you see in above while if $max_files is reached then the while loop exits.
Because by default the files returned contained the naming format file_name.html, whether I wanted to show only the file name without the .html extensions used str_replace(); to get rid of file extensions string.
Tags: Auto, code, directory, Draft, Files, HTML, html files, max, max files, opendir, php, php script, readdir, script, URLs, web, web urls
Posted in System Administration | No Comments »
Monday, April 2nd, 2012 I've hit an interesting article explaining how to check unread gmail email messages in Linux terminal. The original article is here
Being able to read your latest gmail emails in terminal/console is great thing, especially for console geeks like me.
Here is the one liner script:
curl -u GMAIL-USERNAME@gmail.com:SECRET-PASSWORD \
--silent "https://mail.google.com/mail/feed/atom" | tr -d '\n' \
| awk -F '' '{for (i=2; i<=NF; i++) {print $i}}' \
| sed -n "s/
Linux Users Group M. – [7] discussions, [10] comments and [2] jobs on LinkedIn
Twitter – Lynn Serafinn (@LynnSerafinn) has sent you a direct message on Twitter!
Facebook – Sys, you have notifications pending
Twitter – Email Marketing (@optinlists) is now following you on Twitter!
Twitter – Lynn Serafinn (@LynnSerafinn) is now following you on Twitter!
NutshellMail – 32 New Messages for Sat 3/31 12:00 PM
Linux Users Group M. – [10] discussions, [5] comments and [8] jobs on LinkedIn
eBay – Deals up to 60% OFF + A Sweepstakes!
LinkedIn Today – Top news today: The Magic of Doing One Thing at a Time
NutshellMail – 29 New Messages for Fri 3/30 12:00 PM
Linux Users Group M. – [16] discussions, [8] comments and [8] jobs on LinkedIn
Ervan Faizal Rizki . – Join my network on LinkedIn
Twitter – LEXO (@LEXOmx) retweeted one of your Tweets!
NutshellMail – 24 New Messages for Thu 3/29 12:00 PM
Facebook – Your Weekly Facebook Page Update
Linux Users Group M. – [11] discussions, [9] comments and [16] jobs on LinkedIn
As you see this one liner uses curl to fetch the information from mail.google.com's atom feed and then uses awk and sed to parse the returned content and make it suitable for display.
If you want to use the script every now and then on a Linux server or your Linux desktop you can download the above code in a script file -quick_gmail_new_mail_check.sh here
Here is a screenshot of script's returned output:
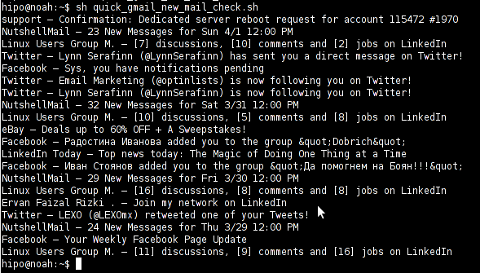
A good use of a modified version of the script is in conjunction with a 15 minutes cron job to launch for new gmail mails and launch your favourite desktop mail client.
This method is useful if you don't want a constant hanging Thunderbird or Evolution, pop3 / imap client on your system to just take up memory or dangle down the window list.
I've done a little modification to the script to simply, launch a predefined email reader program, if gmail atom feed returns new unread mails are available, check or download my check_gmail_unread_mail.sh here
Bear in mind, on occasions of errors with incorrect username or password, the script will not return any errors. The script is missing a properer error handling.Therefore, before you use the script make sure:
gmail_username='YOUR-USERNAME';
gmail_password='YOUR-PASSWORD';
are 100% correct.
To launch the script on 15 minutes cronjob, put it somewhere and place a cron in (non-root) user:
# crontab -u root -e
...
*/15 * * * * /path/to/check_gmail_unread_mail.sh
Once you read your new emails in lets say Thunderbird, close it and on the next delivered unread gmail mails, your mail client will pop up by itself again. Once the mail client is closed the script execution will be terminated.
Consised that if you get too frequently gmail emails, using the script might be annoying as every 15 minutes your mail client will be re-opened.
If you use any of the shell scripts, make sure there are well secured (make it owned only by you). The gmail username and pass are in plain text, so someone can steal your password, very easily. For a one user Linux desktops systems as my case, security is not such a big concern, putting my user only readable script permissions (e.g. chmod 0700)is enough.
Tags: article, atom, Auto, awk, client, com, cron, Desktop, download, Draft, ebay, email, email marketing, email messages, facebook, Fri, geeks, Gmail, GMAIL-USERNAME, GNU, gnu linux, google, Group, https mail, liner, LinkedIn, Linux, linux server, linux users group, mail, marketing, news today, OFF, original article, password, quot, rizki, sat 3, script, SECRET-PASSWORD, terminal, thing, top news, twitter, username, Users, Weekly
Posted in Linux, System Administration, Various | 2 Comments »
Friday, March 30th, 2012 While browsing I stumbled upon a nice blog article
Dumping HTTP headers
The arcitle, points at few ways to DUMP the HTTP headers obtained from user browser.
As I'm not proficient with Ruby, Java and AOL Server what catched my attention is a tiny php for loop, which loops through all the HTTP_* browser set variables and prints them out. Here is the PHP script code:
<?php<br />
foreach($_SERVER as $h=>$v)<br />
if(ereg('HTTP_(.+)',$h,$hp))<br />
echo "<li>$h = $v</li>\n";<br />
header('Content-type: text/html');<br />
?>
The script is pretty easy to use, just place it in a directory on a WebServer capable of executing php and save it under a name like:
show_HTTP_headers.php
If you don't want to bother copy pasting above code, you can also download the dump_HTTP_headers.php script here , rename the dump_HTTP_headers.php.txt to dump_HTTP_headers.php and you're ready to go.
Follow to the respective url to exec the script. I've installed the script on my webserver, so if you are curious of the output the script will be returning check your own browser HTTP set values by clicking here.
PHP will produce output like the one in the screenshot you see below, the shot is taken from my Opera browser:
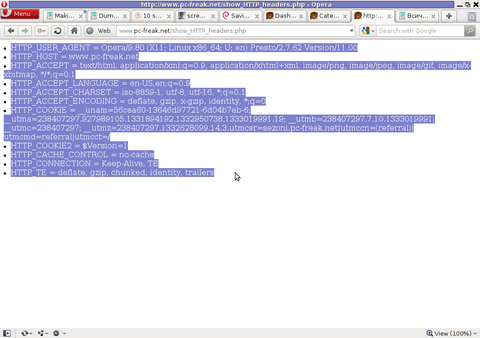
Another sample of the text output the script produce whilst invoked in my Epiphany GNOME browser is:
HTTP_HOST = www.pc-freak.net
HTTP_USER_AGENT = Mozilla/5.0 (X11; U; Linux x86_64; en-us) AppleWebKit/531.2+ (KHTML, like Gecko) Version/5.0 Safari/531.2+ Debian/squeeze (2.30.6-1) Epiphany/2.30.6
HTTP_ACCEPT = application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
HTTP_ACCEPT_ENCODING = gzip
HTTP_ACCEPT_LANGUAGE = en-us, en;q=0.90
HTTP_COOKIE = __qca=P0-2141911651-1294433424320;
__utma_a2a=8614995036.1305562814.1274005888.1319809825.1320152237.2021;wooMeta=MzMxJjMyOCY1NTcmODU1MDMmMTMwODQyNDA1MDUyNCYxMzI4MjcwNjk0ODc0JiYxMDAmJjImJiYm; 3ec0a0ded7adebfeauth=22770a75911b9fb92360ec8b9cf586c9;
__unam=56cea60-12ed86f16c4-3ee02a99-3019;
__utma=238407297.1677217909.1260789806.1333014220.1333023753.1606;
__utmb=238407297.1.10.1333023754; __utmc=238407297;
__utmz=238407297.1332444980.1586.413.utmcsr=www.pc-freak.net|utmccn=(referral)|utmcmd=referral|utmcct=/blog/
You see the script returns, plenty of useful information for debugging purposes:
HTTP_HOST – Virtual Host Webserver name
HTTP_USER_AGENT – The browser exact type useragent returnedHTTP_ACCEPT – the type of MIME applications accepted by the WebServerHTTP_ACCEPT_LANGUAGE – The language types the browser has support for
HTTP_ACCEPT_ENCODING – This PHP variable is usually set to gzip or deflate by the browser if the browser has support for webserver returned content gzipping.
If HTTP_ACCEPT_ENCODING is there, then this means remote webserver is configured to return its HTML and static files in gzipped form.
HTTP_COOKIE – Information about browser cookies, this info can be used for XSS attacks etc. 🙂
HTTP_COOKIE also contains the referrar which in the above case is:
__utmz=238407297.1332444980.1586.413.utmcsr=www.pc-freak.net|utmccn=(referral)
The Cookie information HTTP var also contains information of the exact link referrar:
|utmcmd=referral|utmcct=/blog/
For the sake of comparison show_HTTP_headers.php script output from elinks text browser is like so:
* HTTP_HOST = www.pc-freak.net
* HTTP_USER_AGENT = Links (2.3pre1; Linux 2.6.32-5-amd64 x86_64; 143x42)
* HTTP_ACCEPT = */*
* HTTP_ACCEPT_ENCODING = gzip,deflate * HTTP_ACCEPT_CHARSET = us-ascii, ISO-8859-1, ISO-8859-2, ISO-8859-3, ISO-8859-4, ISO-8859-5, ISO-8859-6, ISO-8859-7, ISO-8859-8, ISO-8859-9, ISO-8859-10, ISO-8859-13, ISO-8859-14, ISO-8859-15, ISO-8859-16, windows-1250, windows-1251, windows-1252, windows-1256,
windows-1257, cp437, cp737, cp850, cp852, cp866, x-cp866-u, x-mac, x-mac-ce, x-kam-cs, koi8-r, koi8-u, koi8-ru, TCVN-5712, VISCII,utf-8 * HTTP_ACCEPT_LANGUAGE = en,*;q=0.1
* HTTP_CONNECTION = keep-alive
One good reason, why it is good to give this script a run is cause it can help you reveal problems with HTTP headers impoperly set cookies, language encoding problems, security holes etc. Also the script is a good example, for starters in learning PHP programming.
Tags: AOL, arcitle, article, attention, Auto, blog, browser, code, code lt, content type, copy, debugging, download, Draft, dump, Dumping, ENCODING, ereg, freak, gecko, Gnome, gzip, host, host www, HTTP, image png, information, Java, khtml, linux x86, loop, nbsp, opera browser, php, php script, php txt, place, prints, quot, ruby, Safari, screenshot, script, script code, server, set variables, shot, show, squeeze, support, text, Tiny, type, unam, User, utmb, utmcsr, xml
Posted in Programming, System Administration | No Comments »
Monday, March 19th, 2012 
One of the company Debian Lenny 5.0 Webservers, where I'm working as sys admin sometimes stops to properly server HTTP requests.
Whenever this oddity happens, the Apache server seems to be running okay but it is not failing to return requested content
I can see the webserver listens on port 80 and establishing connections to remote hosts – the apache processes show normally as I can see in netstat …:
apache:~# netstat -enp 80
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 xxx.xxx.xxx.xx:80 46.253.9.36:5665 SYN_RECV 0 0 -
tcp 0 0 xxx.xxx.xxx.xx:80 78.157.26.24:5933 SYN_RECV 0 0 -
...
Also the apache forked child processes show normally in process list:
apache:~# ps axuwwf|grep -i apache
root 46748 0.0 0.0 112300 872 pts/1 S+ 18:07 0:00 \_ grep -i apache
root 42530 0.0 0.1 217392 6636 ? Ss Mar14 0:39 /usr/sbin/apache2 -k start
www-data 42535 0.0 0.0 147876 1488 ? S Mar14 0:01 \_ /usr/sbin/apache2 -k start
root 28747 0.0 0.1 218180 4792 ? Sl Mar14 0:00 \_ /usr/sbin/apache2 -k start
www-data 31787 0.0 0.1 219156 5832 ? S Mar14 0:00 | \_ /usr/sbin/apache2 -k start
In spite of that, in any client browser to any of the Apache (Virtual hosts) websites, there is no HTML content returned…
This weird problem continues until the Apache webserver is retarted.
Once webserver is restarted everything is back to normal.
I use Apache Check Apache shell script set on few remote hosts to regularly check with nmap if port 80 (www) of my server is open and responding, anyways this script just checks if the open and reachable and thus using it was unable to detect Apache wasn't able to return back HTML content.
To work around the malfunctions I wrote tiny script – retart_apache_if_empty_content_is_returned.sh
The scripts idea is very simple;
A request is made a remote defined host with lynx text browser, then the output of lines is counted, if the output returned by lynx -dump http://someurl.com is less than the number returned whether normally invoked, then the script triggers an apache init script restart.
I've set the script to periodically run in a cron job, every 5 minutes each hour.
# check if apache returns empty content with lynx and if yes restart and log it
*/5 * * * * /usr/sbin/restart_apache_if_empty_content.sh >/dev/null 2>&1
This is not perfect as sometimes still, there will be few minutes downtime, but at least the downside will not be few hours until I am informed ssh to the server and restart Apache manually …
A quick way to download and set from cron execution my script every 5 minutes use:
apache:~# cd /usr/sbin
apache:/usr/sbin# wget -q https://www.pc-freak.net/bscscr/restart_apache_if_empty_content.sh
apache:/usr/sbin# chmod +x restart_apache_if_empty_content.sh
apache:/usr/sbin# crontab -l > /tmp/file; echo '*/5 * * * *' /usr/sbin/restart_apache_if_empty_content.sh 2>&1 >/dev/null
Tags: address state, apache processes, apache server, apache webserver, apache2, apacheroot, Auto, checks, child processes, client, client browser, content, cron, Draft, enp, everything, grep, HTML, HTTP, internet connections, lenny, Lynx, nmap, oddity, program, proto, Restart, restart apache, root, script, scripts, Shell, shell script, show, spite, ss, SYN, User, Virtual, virtual hosts, webservers, weird problem
Posted in System Administration, Web and CMS | 7 Comments »
Friday, March 9th, 2012 
A friend of mine has Fujitsu Siemens Amilo laptop and is full time using his computer with Slackware Linux.
He is quite happy with Slackware Linux 13.37 on the laptop, but unfortunately sometimes his screen brightness lowers. One example when the screen gets darkened is when he switch the computer on without being plugged in the electricity grid. This lowered brightness makes the screen un-user friendly and is quite tiring for the eye …
By default the laptop has the usual function keys and in theory pressing Function (fn) + F8 / F7 – should increase / decrease the brightness with no problems, however on Slackware Linux (and probably on other Linuxes too?), the function keys are not properly recognized and not responding whilst pressed.
I used to have brigtness issues on my Lenovo notebook too and remember how irritating this was.
After a bit of recalling memories on how I solved this brightness issues I remembered the screen brigthness on Linux is tunable through /proc virtual (memory) filesystem.
The laptop (Amilo) Fujitsu Siemens video card is:
lspci |grep -i vga
00:02.0 VGA compatible controller: Intel Corporation Mobile GM965/GL960 Integrated Graphics Controller (primary) (rev 03)
I took a quick look in /proc and found few files called brightness:
- /proc/acpi/video/GFX0/DD01/brightness
- /proc/acpi/video/GFX0/DD02/brightness
- /proc/acpi/video/GFX0/DD03/brightness
- /proc/acpi/video/GFX0/DD04/brightness
- /proc/acpi/video/GFX0/DD05/brightness
cat-ting /proc/acpi/video/GFX0/DD01/brightness, /proc/acpi/video/GFX0/DD03/brightness, /proc/acpi/video/GFX0/DD04/brightness all shows not supported and therefore, they cannot be used to modify brightness:
bash-4.1# for i in $(/proc/acpi/video/GFX0/DD0{1,3,4,5}/brightness); do \
cat $i;
done
<not supported>
<not supported>
<not supported>
<not supported>
After a bit of testing I finally succeeded in increasing the brightness.
Increasing the brightness on the notebook Intel GM965 video card model is done, through file:
/proc/acpi/video/GFX0/DD02/brightness
To see all the brightness levels the Fujitsu LCD display supports:
bash-4.1# cat /proc/acpi/video/GFX0/DD02/brightness
levels: 13 25 38 50 63 75 88 100
current: 25
As you can see the dark screen was caused cause the current: brightness is set to a low value of 25.
To light up the LCD screen and make the screen display fine again, I increased the brightness to the maximum level 100, e.g.:
bash-4.1# echo '100' > /proc/acpi/video/GFX0/DD02/brigthness
Just for the fun, I've written also a two lines script which gradually increases LCDs brightness 🙂
bash-4.1# echo '13' > /proc/acpi/video/GFX0/DD02/brightness;
bash-4.1# for i in \
$(cat /proc/acpi/video/GFX0/DD02/brightness|grep 'levels'|sed -e 's#levels:##g'); do \
echo $i > /proc/acpi/video/GFX0/DD02/brightness; sleep 1; \done
fujitsu_siemens_brightness_fun.sh script is fun to observe in changing the LCD screen gradually in one second intervals 🙂
Here is also a tiny program that reduces and increases the notebook laptop brightness written in C. My friend Dido, coded it in just few minutes just for the fun 🙂
To permanently solve the issues with darkened screen on boot time it is a good idea to include echo '100' > /proc/acpi/video/GFX0/DD02/brigthness in /etc/rc.local:
bash-4.1# echo '100' > /proc/acpi/video/GFX0/DD02/brigthness
I've also written another Universal Linux Increase laptop screen brightness Shell script which should be presumable also working for all Laptop models running Linux 🙂
My maximize_all_linux_laptops_brightness.sh "universal increase Linux brightness" script is here
I'll be glad to hear from people who had tested the script on other laptops and can confirm it works fine for them.
Tags: Amilo, Auto, bit, card, Display, Draft, electricity, electricity grid, eye, f7, f8, file, fn, Fujitsu, fujitsu siemens amilo, fujitsu siemens amilo laptop, full time, fun, function, function keys, Graphics, graphics controller, integrated graphics, intel corporation, laptop, LCD, level, Linux, linuxes, lt, Mobile, nbsp, quot, screen, screen brightness, script, siemens, slackware linux, time, ting, value, video, video card, virtual memory
Posted in Linux, Linux and FreeBSD Desktop, Linux Audio & Video, System Administration | No Comments »
Wednesday, March 7th, 2012 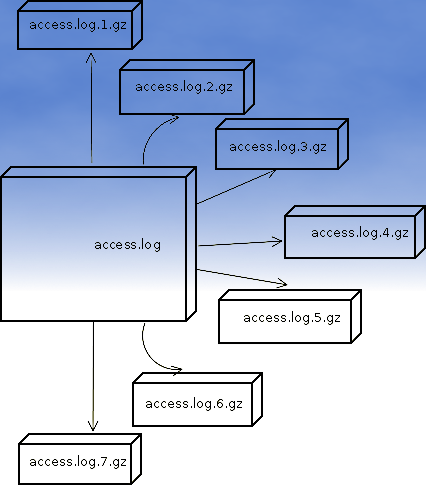
If you are sys admin of Apache Webserver running on Debian Linux relying on logrorate to rorate logs, you might want to change the default way logroration is done.
Little changes in the way Apache log files are served on busy servers can have positive outcomes on the overall way the server CPU units burden. A good logrotation strategy can also prevent your server from occasional extra overheads or downtimes.
The way Debian GNU / Linux process logs is well planned for small servers, however the default logroration Apache routine doesn't fit well for servers which process millions of client requests each day.
I happen to administrate, few servers which are constantly under a heavy load and have occasionally overload troubles because of Debian's logrorate default mechanism.
To cope with the situation I have made few modifications to /etc/logrorate.d/apache2 and decided to share it here hoping, this might help you too.
1. Rotate Apache acccess.log log file daily instead of weekly
On Debian Apache's logrorate script is in /etc/logrotate.d/apache2
The default file content will be like so like so:
debian:~# cat /etc/logrotate.d/apache2
/var/log/apache2/*.log {
weekly
missingok
rotate 52
size 1G
compress
delaycompress
notifempty
create 640 root adm
sharedscripts
postrotate
if [ -f "`. /etc/apache2/envvars ; echo ${APACHE_PID_FILE:-/var/run/apache2.pid}`" ]; then
/etc/init.d/apache2 reload > /dev/null
fi
endscript
}
To change the rotation from weekly to daily change:
weekly
to
#weekly
2. Disable access.log log file gzip compression
By default apache2 logrotate script is tuned ot make compression of rotated file (exmpl: copy access.log to access.log.1 and gzip it, copy access.log to access.log.2 and gzip it etc.). On servers where logs are many gigabytes, once logrotate initiates its scheduled work it will have to compress an enormous log record of apache requests. On very busy Apache servers from my experience, just for a day the log could grow up to approximately 8 / 10 Gigabytes.
I'm sure there are more busy servers out there, which log files are growing to over 100GB for just a single day.
Gzipping a 100GB file piece takes an enormous load on the CPU, as well as often takes long time. When this logrotation gzipping occurs at a moment where the servers CPU cores are already heavy loaded from Apache serving HTTP requests, Apache server becomes inaccessible to most of the clients.
Then for end clients various oddities are experienced, for example Apache dropped connection errors, webserver returning empty pages, or simply inability to respond to the client browser.
Sometimes as a result of the overload, even secure shell connection to SSHD to the server is impossible …
To prevent your server from this roration overloads remove logrorate's default access.log gzipping by commenting:
compress
to
#comment
3. Change maximum log roration by logrorate to be up to 30
By default logrorate is configured to create and keep up to 52 rotated and gzipped access.log files, changing this to a lower number is a good practice (in my view), in cases where log files grow daily to 10 or more GBs. Doing so will save a lot of disk space and reduce the chance the hard disk gets filled in because of the multiple rorated ungzipped enormous access.log files.
To tune the default keep max rorated logs to 30, change:
rotate 52
to
rotate 30
The way logrorate's apache log processing on RHEL / CentOS Linux is working better on high load servers, by default on CentOS logrorate is not configured to do log gzipping at all.
Here is the default /etc/logrorate.d/httpd script for
CentOS release 5.6 (Final)
[hipo@centos httpd]$ cat /etc/logrotate.d/httpd /var/log/httpd/*log {
missingok
notifempty
sharedscripts
postrotate
/bin/kill -HUP `cat /var/run/httpd.pid 2>/dev/null` 2> /dev/null || true
endscript
}
Tags: adm, apache linux, apache log files, apache webserver, apache2, Auto, burden, CentOS, change, client, client requests, compression, connection, copy, cpu units, default mechanism, Disk, doesn, Draft, enormous log, fi, file, gnu linux, gzip, heavy load, init, Linux, linux servers, logrorate, logrotation, logs, mechanism, notifempty, overheads, PID, postrotate, quot, root, rotation, script, server cpu, weeklyto
Posted in Linux, System Administration | No Comments »
Thursday, December 2nd, 2010 It’s actually very easy in order to enable this authentication via your website VirtualHost find the;
<Directory /var/www/yourwebsite>
....
</Directory>
Substitute the /var/www/yourwebsite with your correct website location in between the opening and closing Directory apache directive place something similar to the following lines:
AllowOverride All
AuthName “Add your login message here.”
AuthType Basic
AuthUserFile /etc/apache2/.htpasswd
AuthGroupFile /dev/null
require user name-of-user
Eventually your Directory directive in your let’s say /etc/apache2/apache2.conf should look something like the example in below
<Directory /var/www/yourwebsite>
AllowOverride All
AuthName "Add your login message here."
AuthType Basic
AuthUserFile /etc/apache2/.htpasswd
AuthGroupFile /dev/null
require user name-of-user
</Directory>
Of course in this example you need to set the name-of-user to an actual user name let’s say you want your login user to be admin, then substitute the name-of-user with admin
Of course set the desirable location for your .htpasswd in the AuthUserFile. Just in case if you decide to keep the same location as in my example you will further need to create the /etc/apache2/.htpasswd file.
Note here that in the above exapmle the AllowOverride All could also be substituted for AllowOverride AuthConfig , you might need to put this one if you don’t want that all .htaccess directives are recognized by Apache.
To create the .htpasswd issue the command:
debian~:# htpasswd -c /etc/apache2/.htpasswd admin
New password:
Re-type new password:
In the passwords prompts just type in your password of choice. Now we’re almost ready to have the website apache authentication working, only thing left is to reastart Apache.
I’m using Debian so restarting my apache is done via:
debian:~# /etc/init.d/apache2 restart
In other Linux distributions exec the respective script for Apache restart.
Now access your website and the password protection dialog asking for your credentials to login should popup.
Tags: Allowoverride, apache authentication, apache configuration, AuthConfig, AuthType, AuthUserFile, course, desirable location, directive, file, How to secure site with htpassword using Apache configuration instead of through external .htaccess file, htpasswd, init, Linux, location, login, login user, lt, opening, password, passwords, place, protection, quot, script, something, type, Virtualhost, website location, working
Posted in Linux, System Administration, Web and CMS | No Comments »




