Lately, I'm starting to use my tty consoles more and more. Most of the people should be probably aware of the existence of lynx, elinks and w3m text browsers enabling the console geeks to browse or debug web pages in plain text mode.
Anyhow, for people who did not used one of the aforementioned browsers to text brose the net I warmly suggest you give them a try. A good review on 'em is in one of my previous post – Text mode console browsing with lynx, elinks, w3m and links text browsers …
For people dedicated to only use console and text mode console on their Personal Computer, simply installing and using this text browsers will not allow you to view any images  tags in the html.
tags in the html.
Nowdays one of the reasons many people would decide not to use console for web is because they want to see pictures. Hence I believe by having the opportunity to have almost fully functional text browsing in Linux cosnole / terminal many might choose not to bother with heavy resource consuming desktop browsers like Firefox, Google Chrome, Opera etc..
Another good reason why you might want to use a console browser instead of its Desktop resource monsters, would be improved efficiency of work. It is a well evident fact keyboard access to commands is always faster than mouse and GUI!
Besides that, I'm convinced there should be many hard core geeks out there, who still can happily live without Macromedia Flash ads and Videos in Web. For this group of users having support for graphical browsing in console is also a must.
Following my previous thoughts there should be many people who doesn't have a specific requirement for GUI programs but still use (mutt, ssh, vim, mpg321, zgv etc.).
I'm sure there are plenty of this people who do most of their work in text console and use the X windows server in conjunction with mimalistic graphical environment like (DropBox, XFCE …) for the one and only reason to view pictures embedded in web pages.
I'm one of all this guys prior mentioned, keen on console tty browsing. Therefore while checking the available console browsers few days ago, I've stumbled on a text console w3m browser capable of displaying website with images in console called w3m-img.
w3m-img is displays pictures in web over a plain console tty or in X terminals (mlterm, xterm etc.).
Here is the description returned by apt-cache show w3m-img
debian:~# apt-cache show w3m-img|grep -i description -A 3
Description: inline image extension support utilities for w3m
w3m-img provides some utilities to support inline images for w3m
on terminal emulator in X Window System environments and Linux
framebuffer.
w3m-img doesn't rely on svgalib for displaying the pictures, but comes with its own written console image display & rendering library called w3mimgdisplay. – /usr/lib/w3m/w3mimgdisplay.
One w3m-img pre-requirement in order to be able to display pictures in plain text console ttys is to have the Linux kernel framebuffer enabled..
Actually, framebuffer is enabled by default on latest stable Debian and derivatives as well as on most other Linux releases as of time of writing.
Framebuffer is also active on other RPM based distros (Fedora, CentOS, SuSE) etc.
The Frambebuffer on or off is controlled via some directives added in grub or lilo configuration files – (depending on the installed boot loader).
Some people can only boot their PCs with the framebuffer kernel support switched off at boot time or the system will not boot Linux at all.
Unfortunately this unlucky ones, would not be able to use the picture rendering w3m-img capabilities but don't be desperate, there is hope 🙂
For people who can't run their Linux distro with a framebuffer kernel support enabled there is a custom hacked version of links – console text browser called links-graphic. links-graphic supports both console graphical text browsing using the framebuffer or alternatively svgalib as a console graphics render machine.
I used to be actively using links-graphics WWW browser quite often about 8 years ago and just remembering it brings me good memories of the good old console "hacking" years 🙂
Anyways, w3m-img packaged version is currently available for both rpm and deb based Linux distributions. Here is how to install on both.
1.Install and use w3m-img on Debian, Ubuntu, Mint Linux-es
debian:~# apt-get --yes install w3m-img
....
This should install w3m-img, if of course there is already no previous install of w3m package on the system.
In case you have the w3m deb installed, you will have to first remove the existing w3m installed version before installing the w3m-img package, otherwise you will probably end up with an installation conflict (at least I got such a dependency conflict while apt-getting). Probably the conflict would never occur if aptitude install w3m-img is used instead of apt ….
Usage of w3m-img is exactly the same as using the w3m text only browser version. Below is a screenshot example of w3m-img in action:
debian:~# w3m http://images.google.com
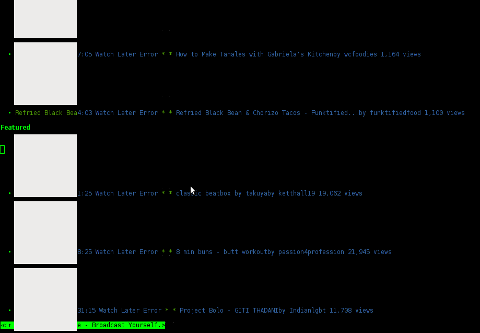
As you can see in the upper screenshots w3m-img displays pictures pretty nice, whether even images.google.com search functionality works fine.
Generally IMHO a lot of pages looks cool with w3m-img.
Some elements placement during rendering, comes at odd positions but this is normal, since original w3m text browser doesn't have any support for Javascript 1 / 2.
For those people who would like to have both javascript basic support and images in a plain text console browsing you, again you will have to compile links2 WWW browser from source manually with svgalib support enabled.
2. Installing w3m-img to text-browse with images on Fedora, CentoS, RHEL, Redhat etc.
[root@centos ~]# yum -y install w3m-img
....
A very cool thing of w3m graphical console browser is it support most major image formats including animated GIF files 🙂
The way animated GIFs are viewed is very old school, here is a notice extracted from README.img contained in the pack.
Notice
If you want to see GIF animation, please hit a suitable key, such
as 'h', 'l', etc., repeatedly, because a frame is rewritten
according to the re-drawing demand from w3m.
Some code in w3mimg/fb/fb.c was originally written by Mr. Yamasaki.
http://www.sainet.or.jp/~yamasaki/download/fb-sample.tar.gz
As one can read in order to see an animated GIF file with w3m you will have to keep pumping the h or l key or Enter key 😀 😀 😀 (like a nintendo game ain't it?)
Here is the also the complete list of Supported browser features mentioned in README.img
Support
* Display inline image (GIF,PNG,JPEG, etc.) on terminals
(xterm,rxvt, etc.) of X11 or Linux framebuffer device.
* Support inline image of img tag.
Support of attributes "width", "height", and "align".
* Direct display of image file which header is "Content-type: image/*"
* Support of
Something else which I find worthy to mention is the browser behaviour, whether a webpage has Adobe Flash .swf or .flv files embedded. If such files are contained in website source code, they will be simply ignored and the w3m keeps running stable (no strange flash crashes! hooray!).
While website with flash is opened in w3m, Adobe Flash's field on the screen shows either a blank rectangle or an empty square (depending on the site embedded flash banner dimensions and form).
Stability of w3m in opening flash website is something really nice. I say this because I still remember how terrible the situation with links with svgalib support compiled in used to be. I remember back in the day with links2 most "flash enabled" websites lead the browser to a ugly core dump.
3. Install and use links2 on Debian and derivatives Linux to browse in console graphically with javascript support
As aforementioned, there is a hacked version of links browser called links-graphics
This hacked version is available as a package within Debian, Ubuntu and presumably most if not all of the rest deb based Linux repos.
On Fedora and the other RPM family Linuces links-graphics, should be downloaded separately as rpm and installed and is inavailable through default rpm repositories.
On Debian distros links-graphics is available by installing links2.
debian:~# apt-get install --yes links2
....
Later to start links2 in graphics mode in lets say tty1 on a machine booted its kernel with framebuffer support, type:
debian:~# links2 -driver fb http://images.google.com
Actually links2 looks, way better in console than w3m but this is quite normal, as links is way more "user friendly GUI text browser".
For those, using their console ttys without framebuffer enabled you can alternatively run links2 with its svgalib graphics support like so:
debian:~# links2 -driver svgalib -mode 320x200x16 http://images.google.com
Note that the svgalib driver is not working on my machine, as my Linux kernel framebuffer is already enabled. Probably if I want to use links2 through svgalib I will have to reboot and boot machine with framebuffer kernel support switched off…
links2 also supports X window graphics and is a great for Graphical environment WWW browser substitute to CPU intensive Iceweasel / Firefox or Google Chrome.
Links2 can be also used as a default browser in X windows (GUI) with any graphic manager. In my view it is perfect web browser for scientists and people who does not need support for Adobe Flash Player or HTML5 standards.
To use links in XFCE or GNOME Desktop env, the quickest way is to prepare new Application Launcher to run command:
debian:~# links2 -g
It is useful to use a quick alias to links -g in my ~/.bashrc in order to allow easier browsing from console by typing xlinks someurladdress.com
If you want to add this xlinks shell alias exec:
debian:~# echo 'alias xlinks='links2 -g $1' >> ~/.bashrc
4. Install links with graphics console support on Fedora, CentOS and RHEL
[root@fedora ~]# cd /usr/local/src
[root@fedora src]# wget -q http://jakub.horky.net/rpm/links/links-2.1pre15-2/links-2.1pre15-2.i386.rpm
[root@fedora src]# rpm -ivh --nodeps links-2.1pre15-2/links-2.1pre15-2.i386.rpm
Preparing... ########################################### [100%]
Installing... ########################################### [100%]
If you get some errors with missing libraries after installing and launching links2, try to resolve them by manually linking them with ln cmd or look for the library package rpm versions and install them via yum. Another way is to fetch the links2 source from Links2 official website links.twibright.com and build from source.
Since the last time in 8 years ago I used links2, it evolved a lot. The version now did not crash as before with flash websites are viewed. Generally Links2 now is way more stable.
To sum it up most people, will probably want to use Links2 for console graphical browsing as the speed and support for HTML and Javascript and web site formatting is way advanced than w3m-img
I haven't compared the speed of opening pages, but since w3m-img is html and graphics render is more simple than xlinks I suppose at some occasions w3m-img will be faster in site rendering.
However still links2 performs really light fast and its web page opening time is swift and more than good.. If xlinks opening performance is compared to most (if not all) traditional desktop browsers used nowdays Links2 will definitely beat them.
A good links2 application instead of a traditional desktop browser is also for people who aim at improving website browsing time.
I haven't thoroughfully enough, researched on other text console grahic browser alternatives programs. If I miss something and you know amy other better ones please let me know.
Wish you a Happy Browsing 😉