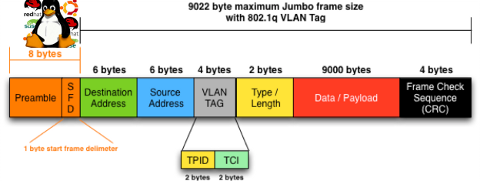
So what is Jumbo Frames? and why, when and how it can increase the network thoroughput on Linux?
Jumbo Frames are Ethernet frames with more than 1500 bytes of payload. They can carry up to 9000 bytes of payload. Many Gigabit switches and network cards supports them.
Jumbo frames is a networking standard for many educational networks like AARNET. Unfortunately most commercial ISPs doesn't support them and therefore enabling Jumbo frames will rarely increase bandwidth thoroughput for information transfers over the internet.
Hopefully in the years to come with the constant increase of bandwidths and betterment of connectivity, jumbo frames package transfers will be supported by most ISPs as well.
Jumbo frames network support is just great for is small local – home networks and company / corporation office intranets.
Thus enabling Jumbo Frame is absolutely essential for "local" ethernet networks, where large file transfers occur frequently. Such networks are networks where, there is often a Video or Audio streaming with high quality like HD quality on servers running File Sharing services like Samba, local FTP sites,Webservers etc.
One other advantage of enabling jumbo frames is reduce of general server overhead and decrease in CPU load / (CPU usage), when transferring large or enormous sized files.Therefore having jumbo frames enabled on office network routers with GNU / Linux or any other *nix OS is vital.
Jumbo Frames traffic is supported in GNU / Linux kernel since version 2.6.17+ in earlier 2.4.x it was possible through external third party kernel patches.
1. Manually increase MTU to 9000 with ifconfig to enable Jumbo frames
debian:~# /sbin/ifconfig eth0 mtu 9000
The default MTU on most GNU / Linux (if not all) is 1500, to check the default set MTU with ifconfig:
linux:~# /sbin/ifconfig eth0|grep -i mtu
UP BROADCAST MULTICAST MTU:1500 Metric:1
To take advantage of Jumbo Frames, all that has to be done is increase the default Maximum Transmission Unit from 1500 to 9000
For those who don't know MTU is the largest physical packet size that can be transferred over the network. MTU is measured by default in bytes. If a information has to be transferred over the network which exceeds the lets say 1500 MTU (bytes), it will be chopped and transferred in few packs each of 1500 size.
MTUs differ on different netework topologies. Just for info here are the few main MTUs for main network types existing today:
- 16 MBit/Sec Token Ring – default MTU (17914)
- 4 Mbits/Sec Token Ring – default MTU (4464)
- FDDI – default MTU (4352)
- Ethernet – def MTU (1500)
- IEEE 802.3/802.2 standard – def MTU (1492)
- X.25 (dial up etc.) – def MTU (576)
- Jumbo Frames – def max MTU (9000)
Setting the MTU packet frames to 9000 to enable Jumbo Frames is done with:
linux:~# /sbin/ifconfig eth0 mtu 9000
If the command returns nothing, this most likely means now the server can communicate on eth0 with MTUs of each 9000 and therefore the network thoroughput will be better. In other case, if the network card driver or card is not a gigabit one the cmd will return error:
SIOCSIFMTU: Invalid argument
2. Enabling Jumbo Frames on Debian / Ubuntu etc. "the Debian way"
a.) Jumbo Frames on ethernet interfaces with static IP address assigned Edit /etc/network/interfaces and you should have for each of the interfaces you would like to set the Jumbo Frames, records similar to:
Raising the MTU to 9000 if for one time can be done again manually with ifconfig
debian:~# /sbin/ifconfig eth0 mtu 9000
iface eth0 inet static
address 192.168.0.5
network 192.168.0.0
gateway 192.168.0.254
netmask 255.255.255.0
mtu 9000
For each of the interfaces (eth1, eth2 etc.), add a chunk similar to one above changing the changing the IPs, Gateway and Netmask.
If the server is with two gigabit cards (eth0, eth1) supporting Jumbo frames add to /etc/network/interfaces :
iface eth0 inet static
address 192.168.0.5
network 192.168.0.0
gateway 192.168.0.254
netmask 255.255.255.0
mtu 9000
iface eth1 inet static
address 192.168.0.6
network 192.168.0.0
gateway 192.168.0.254
netmask 255.255.255.0
mtu 9000
b.) Jumbo Frames on ethernet interfaces with dynamic IP obtained via DHCP
Again in /etc/network/interfaces put:
auto eth0
iface eth0 inet dhcp
post-up /sbin/ifconfig eth0 mtu 9000
3. Setting Jumbo Frames on Fedora / CentOS / RHEL "the Redhat way"
Enabling jumbo frames on all Gigabit lan interfaces (eth0, eth1, eth2 …) in Fedora / CentOS / RHEL is done through files:
- /etc/sysconfig/network-script/ifcfg-eth0
- /etc/sysconfig/network-script/ifcfg-eth1
etc. …
append in each one at the end of the respective config:
MTU=9000
[root@fedora ~]# echo 'MTU=9000' >> /etc/sysconfig/network-scripts/ifcfg-eth
a quick way to set Maximum Transmission Unit to 9000 for all network interfaces on on Redhat based distros is by executing the following loop:
[root@centos ~]# for i in $(echo /etc/sysconfig/network-scripts/ifcfg-eth*); do \echo 'MTU=9000' >> $i
done
P.S.: Be sure that all your interfaces are supporting MTU=9000, otherwise increase while the MTU setting is set will return SIOCSIFMTU: Invalid argument err.
The above loop is to be used only, in case you have a group of identical machines with Lan Cards supporting Gigabit networks and loaded kernel drivers supporting MTU up to 9000.
Some Intel and Realtek Gigabit cards supports only a maximum MTU of 7000, 7500 etc., so if you own a card like this check what is the max MTU the card supports and set it in the lan device configuration.
If increasing the MTU is done on remote server through SSH connection, be extremely cautious as restarting the network might leave your server inaccessible.
To check if each of the server interfaces are "Gigabit ready":
[root@centos ~]# /sbin/ethtool eth0|grep -i 1000BaseT
1000baseT/Half 1000baseT/Full
1000baseT/Half 1000baseT/Full
If you're 100% sure there will be no troubles with enabling MTU > 1500, initiate a network reload:
[root@centos ~]# /etc/init.d/network restart
...
4. Enable Jumbo Frames on Slackware Linux
To list the ethernet devices and check they are Gigabit ones issue:
bash-4.1# lspci | grep [Ee]ther
0c:00.0 Ethernet controller: D-Link System Inc Gigabit Ethernet Adapter (rev 11)
0c:01.0 Ethernet controller: D-Link System Inc Gigabit Ethernet Adapter (rev 11)
Setting up jumbo frames on Slackware Linux has two ways; the slackware way and the "universal" Linux way:
a.) the Slackware way
On Slackware Linux, all kind of network configurations are done in /etc/rc.d/rc.inet1.conf
Usual config for eth0 and eth1 interfaces looks like so:
# Config information for eth0:
IPADDR[0]="10.10.0.1"
NETMASK[0]="255.255.255.0"
USE_DHCP[0]=""
DHCP_HOSTNAME[1]=""
# Config information for eth1:
IPADDR[1]="10.1.1.1"
NETMASK[1]="255.255.255.0"
USE_DHCP[1]=""
DHCP_HOSTNAME[1]=""
To raise the MTU to 9000, the variables MTU[0]="9000" and MTU[1]="9000" has to be included after each interface config block, e.g.:
# Config information for eth0:
IPADDR[0]="172.16.1.1"
NETMASK[0]="255.255.255.0"
USE_DHCP[0]=""
DHCP_HOSTNAME[1]=""
MTU[0]="9000"
# Config information for eth1:
IPADDR[1]="10.1.1.1"
NETMASK[1]="255.255.255.0"
USE_DHCP[1]=""
DHCP_HOSTNAME[1]=""
MTU[1]="9000"
bash-4.1# /etc/rc.d/rc.inet1 restart
...
b.) The "Universal" Linux way
This way is working on most if not all Linux distributions.
Insert in /etc/rc.local:
/sbin/ifconfig eth0 mtu 9000 up
/sbin/ifconfig eth1 mtu 9000 up
5. Check if Jumbo Frames are properly enabled
There are at least two ways to display the MTU settings for eths.
a.) Using grepping the MTU from ifconfig
linux:~# /sbin/ifconfig eth0|grep -i mtu
UP BROADCAST MULTICAST MTU:9000 Metric:1
linux:~# /sbin/ifconfig eth1|grep -i mtu
UP BROADCAST MULTICAST MTU:9000 Metric:1
b.) Using ip command from iproute2 package to get MTU
linux:~# ip route get 192.168.2.134
local 192.168.2.134 dev lo src 192.168.2.134
cache
linux:~# ip route show dev wlan0
192.168.2.0/24 proto kernel scope link src 192.168.2.134
default via 192.168.2.1
You see MTU is now set to 9000, so the two server lans, are now able to communicate with increased network thoroughput.
Enjoy the accelerated network transfers 😉








How to resolve (fix) WordPress wp-cron.php errors like “POST /wp-cron.php?doing_wp_cron HTTP/1.0″ 404” / What is wp-cron.php and what it does
Monday, March 12th, 2012One of the WordPress websites hosted on our dedicated server produces all the time a wp-cron.php 404 error messages like:
xxx.xxx.xxx.xxx - - [15/Apr/2010:06:32:12 -0600] "POST /wp-cron.php?doing_wp_cron HTTP/1.0
I did not know until recently, whatwp-cron.php does, so I checked in google and red a bit. Many of the places, I've red are aa bit unclear and doesn't give good exlanation on what exactly wp-cron.php does. I wrote this post in hope it will shed some more light on wp-config.php and how this major 404 issue is solved..
So
what is wp-cron.php doing?
Suppose you're writting a new post and you want to take advantage of WordPress functionality to schedule a post to appear Online at specific time:
The Publish Immediately, field execution is being issued on the scheduled time thanks to the wp-cron.php periodic invocation.
Another example for wp-cron.php operation is in handling flushing of WP old HTML Caches generated by some wordpress caching plugin like W3 Total Cache
wp-cron.php takes care for dozens of other stuff silently in the background. That's why many wordpress plugins are depending heavily on wp-cron.php proper periodic execution. Therefore if something is wrong with wp-config.php, this makes wordpress based blog or website partially working or not working at all.
Our company wp-cron.php errors case
In our case the:
212.235.185.131 – – [15/Apr/2010:06:32:12 -0600] "POST /wp-cron.php?doing_wp_cron HTTP/1.0" 404
is occuring in Apache access.log (after each unique vistor request to wordpress!.), this is cause wp-cron.php is invoked on each new site visitor site request.
This puts a "vain load" on the Apache Server, attempting constatly to invoke the script … always returning not found 404 err.
As a consequence, the WP website experiences "weird" problems all the time. An illustration of a problem caused by the impoper wp-cron.php execution is when we are adding new plugins to WP.
Lets say a new wordpress extension is download, installed and enabled in order to add new useful functioanlity to the site.
Most of the time this new plugin would be malfunctioning if for example it is prepared to add some kind of new html form or change something on some or all the wordpress HTML generated pages.WP cache directory is manually deleted with rm -rf /var/www/blog/wp-content/cache/…
This troubles are result of wp-config.php's inability to update settings in wp SQL database, after each new user request to our site.
So the newly added plugin website functionality is not showing up at all, until
I don't know how thi whole wp-config.php mess occured, however my guess is whoever installed this wordpress has messed something in the install procedure.
Anyways, as I researched thoroughfully, I red many people complaining of having experienced same wp-config.php 404 errs. As I red, most of the people troubles were caused by their shared hosting prohibiting the wp-cron.php execution.
It appears many shared hostings providers choose, to disable the wordpress default wp-cron.php execution. The reason is probably the script puts heavy load on shared hosting servers and makes troubles with server overloads.
Anyhow, since our company server is adedicated server I can tell for sure in our case wordpress had no restrictions for how and when wp-cron.php is invoked.
I've seen also some posts online claiming, the wp-cron.php issues are caused of improper localhost records in /etc/hosts, after a thorough examination I did not found any hosts problems:
hipo@debian:~$ grep -i 127.0.0.1 /etc/hosts
127.0.0.1 localhost.localdomain localhost
You see from below paste, our server, /etc/hosts has perfectly correct 127.0.0.1 records.
Changing default way wp-cron.php is executed
As I've learned it is generally a good idea for WordPress based websites which contain tens of thousands of visitors, to alter the default way wp-cron.php is handled. Doing so will achieve some efficiency and improve server hardware utilization.
Invoking the script, after each visitor request can put a heavy "useless" burden on the server CPU. In most wordpress based websites, the script did not need to make frequent changes in the DB, as new comments in posts did not happen often. In most wordpress installs out there, big changes in the wordpress are not common.
Therefore, a good frequency to exec wp-cron.php, for wordpress blogs getting only a couple of user comments per hour is, half an hour cron routine.
To disable automatic invocation of wp-cron.php, after each visitor request open /var/www/blog/wp-config.php and nearby the line 30 or 40, put:
define('DISABLE_WP_CRON', true);
An important note to make here is that it makes sense the position in wp-config.php, where define('DISABLE_WP_CRON', true); is placed. If for instance you put it at the end of file or near the end of the file, this setting will not take affect.
With that said be sure to put the variable define, somewhere along the file initial defines or it will not work.
Next, with Apache non-root privileged user lets say www-data, httpd, www depending on the Linux distribution or BSD Unix type add a php CLI line to invoke wp-cron.php every half an hour:
linux:~# crontab -u www-data -e
0,30 * * * * cd /var/www/blog; /usr/bin/php /var/www/blog/wp-cron.php 2>&1 >/dev/null
To assure, the php CLI (Command Language Interface) interpreter is capable of properly interpreting the wp-cron.php, check wp-cron.php for syntax errors with cmd:
linux:~# php -l /var/www/blog/wp-cron.php
No syntax errors detected in /var/www/blog/wp-cron.php
That's all, 404 wp-cron.php error messages will not appear anymore in access.log! 🙂
Just for those who can find the root of the /wp-cron.php?doing_wp_cron HTTP/1.0" 404 and fix the issue in some other way (I'll be glad to know how?), there is also another external way to invoke wp-cron.php with a request directly to the webserver with short cron invocation via wget or lynx text browser.
– Here is how to call wp-cron.php every half an hour with lynxPut inside any non-privileged user, something like:
01,30 * * * * /usr/bin/lynx -dump "http://www.your-domain-url.com/wp-cron.php?doing_wp_cron" 2>&1 >/dev/null
– Call wp-cron.php every 30 mins with wget:
01,30 * * * * /usr/bin/wget -q "http://www.your-domain-url.com/wp-cron.php?doing_wp_cron"
Invoke the wp-cron.php less frequently, saves the server from processing the wp-cron.php thousands of useless times.
Altering the way wp-cron.php works should be seen immediately as the reduced server load should drop a bit.
Consider you might need to play with the script exec frequency until you get, best fit cron timing. For my company case there are only up to 3 new article posted a week, hence too high frequence of wp-cron.php invocations is useless.
With blog where new posts occur once a day a script schedule frequency of 6 up to 12 hours should be ok.
Tags: akismet, Auto, caches, checks, commentor, cr, cron, daySuppose, dedicated server, doesn, dozens, Draft, email, error messages, execution, exlanation, file, google, HTML, HTTP, invocation, localhost, nbsp, newsletter, operation, periodic execution, php, plugin, quot, request, scheduler, someone, something, spam, SQL, time, time thanks, Wordpress, wordpress plugins, wp
Posted in System Administration, Web and CMS, Wordpress | 3 Comments »