One good module that helps in mitigating, very basic Denial of Service attacks against Apache 1.3.x 2.0.x and 2.2.x webserver is mod_evasive
I’ve noticed however many Apache administrators out there does forget to install it on new Apache installations or even some of them haven’t heard about of it.
Therefore I wrote this small article to create some more awareness of the existence of the anti DoS module and hopefully thorugh it help some of my readers to strengthen their server security.
Here is a description on what exactly mod-evasive module does:
debian:~# apt-cache show libapache2-mod-evasive | grep -i description -A 7
Description: evasive module to minimize HTTP DoS or brute force attacks
mod_evasive is an evasive maneuvers module for Apache to provide some
protection in the event of an HTTP DoS or DDoS attack or brute force attack.
.
It is also designed to be a detection tool, and can be easily configured to
talk to ipchains, firewalls, routers, and etcetera.
.
This module only works on Apache 2.x servers
How does mod-evasive anti DoS module works?
Detection is performed by creating an internal dynamic hash table of IP Addresses and URIs, and denying any single IP address which matches the criterias:
- Requesting the same page more than number of times per second
- Making more than N (number) of concurrent requests on the same child per second
- Making requests to Apache during the IP is temporarily blacklisted (in a blocking list – IP blacklist is removed after a time period))
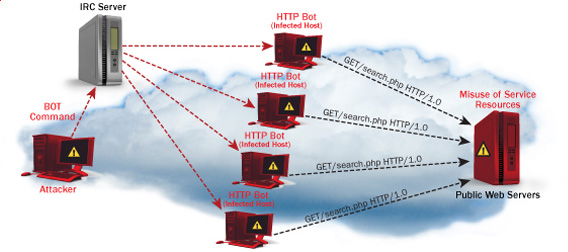
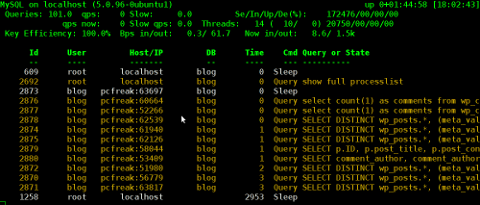
These anti DDoS and DoS attack protection decreases the possibility that Apache gets DoSed by ana amateur DoS attack, however it still opens doors for attacks who has a large bot-nets of zoombie hosts (let’s say 10000) which will simultaneously request a page from the Apache server. The result in a scenario with a infected botnet running a DoS tool in most of the cases will be a quick exhaustion of system resources available (bandwidth, server memory and processor consumption).
Thus mod-evasive just grants a DoS and DDoS security only on a basic, level where someone tries to DoS a webserver with only possessing access to few hosts.
mod-evasive however in many cases mesaure to protect against DoS and does a great job if combined with Apache mod-security module discussed in one of my previous blog posts – Tightening PHP Security on Debian with Apache 2.2 with ModSecurity2
1. Install mod-evasive
Installing mod-evasive on Debian Lenny, Squeeze and even Wheezy is done in identical way straight using apt-get:
deiban:~# apt-get install libapache2-mod-evasive
...
2. Enable mod-evasive in Apache
debian:~# ln -sf /etc/apache2/mods-available/mod-evasive.load /etc/apache2/mods-enabled/mod-evasive.load
3. Configure the way mod-evasive deals with potential DoS attacks
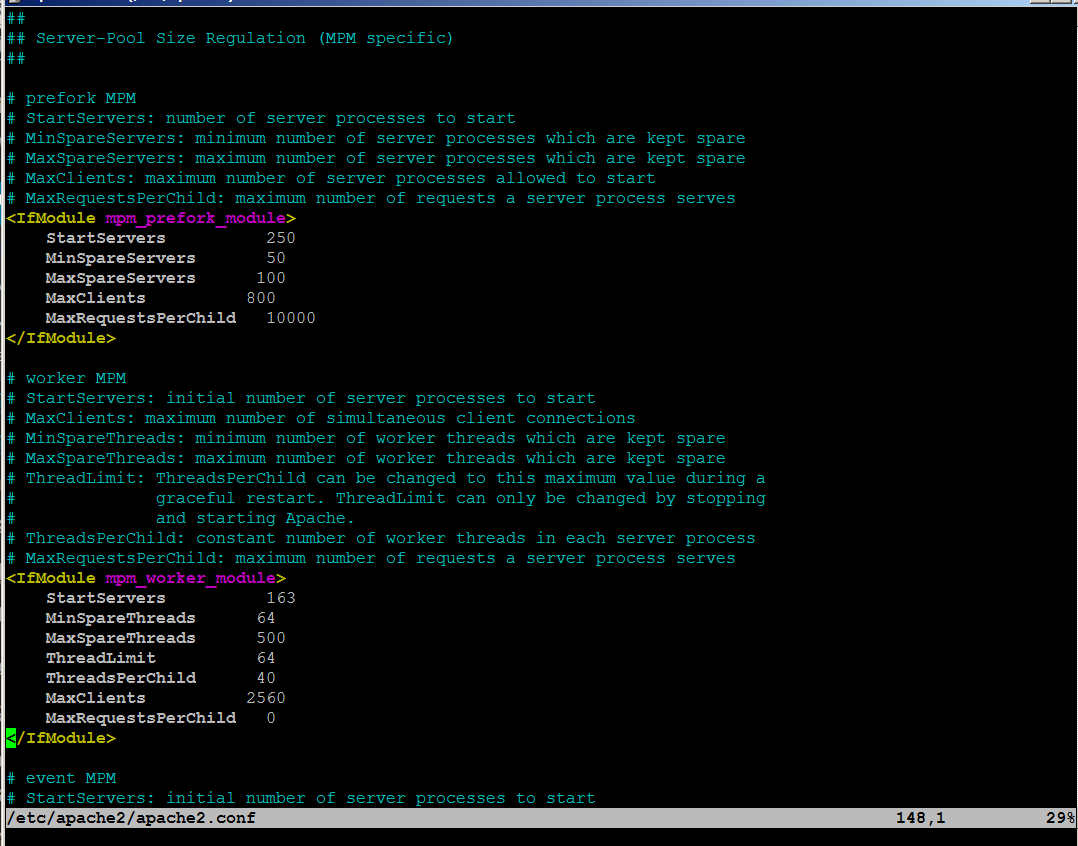
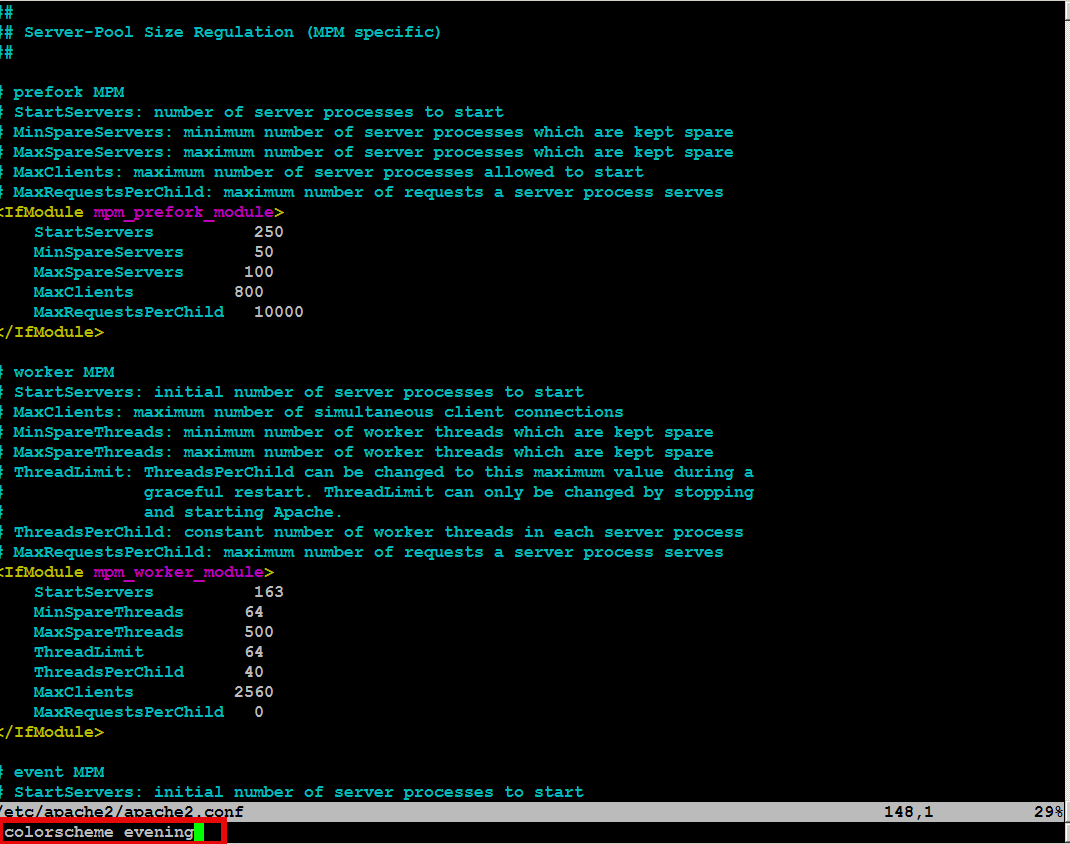
Open /etc/apache2/apache2.conf, go down to the end of the file and paste inside, below three mod-evasive configuration directives:
<IfModule mod_evasive20.c>
DOSHashTableSize 3097DOS
PageCount 30
DOSSiteCount 40
DOSPageInterval 2
DOSSiteInterval 1
DOSBlockingPeriod 120
#DOSEmailNotify hipo@mymailserver.com
</IfModule>
In case of the above configuration criterias are matched, mod-evasive instructs Apache to return a 403 (Forbidden by default) error page which will conserve bandwidth and system resources in case of DoS attack attempt, especially if the DoS attack targets multiple requests to let’s say a large downloadable file or a PHP,Perl,Python script which does a lot of computation and thus consumes large portion of server CPU time.
The meaning of the above three mod-evasive config vars are as follows:
DOSHashTableSize 3097 – Increasing the DoSHashTableSize will increase performance of mod-evasive but will consume more server memory, on a busy webserver this value however should be increased
DOSPageCount 30 – Add IP in evasive temporary blacklist if a request for any IP that hits the same page 30 consequential times.
DOSSiteCount 40 – Add IP to be be blacklisted if 40 requests are made to a one and the same URL location in 1 second time
DOSBlockingPeriod 120 – Instructs the time in seconds for which an IP will get blacklisted (e.g. will get returned the 403 foribden page), this settings instructs mod-evasive to block every intruder which matches DOSPageCount 30 or DOSSiteCount 40 for 2 minutes time.
DOSPageInterval 2 – Interval of 2 seconds for which DOSPageCount can be reached.
DOSSiteInterval 1 – Interval of 1 second in which if DOSSiteCount of 40 is matched the matched IP will be blacklisted for configured period of time.
mod-evasive also supports IP whitelisting with its option DOSWhitelist , handy in cases if for example, you should allow access to a single webpage from office env consisting of hundred computers behind a NAT.
Another handy configuration option is the module capability to notify, if a DoS is originating from a number of IP addresses using the option DOSEmailNotify
Using the DOSSystemCommand in relation with iptables, could be configured to filter out any IP addresses which are found to be matching the configured mod-evasive rules.
The module also supports custom logging, if you want to keep track on IPs which are found to be trying a DoS attack against the server place in above shown configuration DOSLogDir “/var/log/apache2/evasive” and create the /var/log/apache2/evasive directory, with:
debian:~# mkdir /var/log/apache2/evasive
I decided not to log mod-evasive DoS IP matches as this will just add some extra load on the server, however in debugging some mistakenly blacklisted IPs logging is sure a must.
4. Restart Apache to load up mod-evasive
debian:~# /etc/init.d/apache2 restart
...
Finally a very good reading which sheds more light on how exactly mod-evasive works and some extra module configuration options are located in the documentation bundled with the deb package to read it, issue:
debian:~# zless /usr/share/doc/libapache2-mod-evasive/README.gz










A must have collection of WordPress plugins that enpowers your blog and improves SEO
Tuesday, April 5th, 2011Since I’m using wordpress as a blogging platform for about two years now and I’m constantly experimenting with valueable wordpress plugins.
I’ve decided to publish a compilation of wordpress plugins that empowers my blog
The plugins included in the compilation are quite various, some of the plugins aims at easy post sharing via the general social networks and main websites used by users today, others significantly helps in increasing the blog ranking in major search engines, there are some that adds like button to the blog.
These plugins also strenghthen the easy blog RSS file sharing, some post straight to twitter all your blog posts, generate tags automatically, puts a better features to the default wordpress commenting mechanism, prevent from spam comments, add features for easily adding Google adsense to the wordpress installation to help you advertise on your blog.
There are also plugins which delete duplicate posts (if you have such), puts better wordpress blog search bar, generates a sitemap to the blog, add an option to include php codes straight into your posts, adds wordpress an option to easily put mod rewrite rules straight from the wordpress interface, boost wordpress speed by adding static html generation cache, boost performance etc. etc.
Here is the complete list of wordpress plugins which I have currently installed on my wordpress blog:
ad-squares-widgetadd-to-any-subscribe
advertising-manager
ajax-comments
akismet
all-in-one-adsense-and-ypn
all-in-one-seo-pack
askapache-google-404
auto-tag
bm-custom-login
commentluv
comments-statistics
cyr2lat-slugs
delete-duplicate-posts
easy-adsenser
extended-search-plugin
facebook-share-new
favourite-bible-verse
feedburner-plugin
feedburner-widget
feedburner_feedsmith_plugin_2.3
feedlist
force-publish-schedule
google-analytics-for-wordpress
google-sitemap-generator
headspace2
my-link-order
php-code-widget
platinum-seo-pack
post-plugin-library
post-to-twitter
profile-pic
profile-pics
redirection
rss-atom-avatar
seo-automatic-links
seo-slugs
share-on-facebook
share-this
similar-posts
simple-tags
subscribe-to-comments-reloaded
subscribe-to-comments
subscribe2
text-control
tidy-up
tinymce-advanced
what-would-seth-godin-do
wordbook
wordpress-23-related-posts-plugin
wordpress-mobile-edition
wordpress-thread-comment
wp-codebox
wp-keiths-easy-rss
wp-likes
wp-o-matic
wp-postviews
wp-super-cache
wp-syntax
yourls-wordpress-to-twitter
I do have enabled most of the plugins, though some are disabled but still might be helpful somewhere in the close-future thus I still keep them installed.
I would skip the time to describe one by one what each of the above list of plugins will do for your wordpress, since the list is quite long.
However I defnitely think this is a list of plugins you might want to have installed in a newly established wordpress blog for sure.
Note that the versions of the plugins which are included in this must have wordpress plugins collection might not be the latest as the included ones are the ones I do have installed at the time of writting of this article.
Also be aware that some of the plugins might create some issues with newer versions of wordpress (your blog might beak up!), however most of the plugins should work out of the box by just enabling each one of them from the wordpress interface via the menus:
Settings -> Plugins -> InactiveTo straight install my bundled package of plugins you have to issue the commands:
linux:~# cd /var/www/blog/wp-content/pluginslinux:/var/www/blog/wp-content/plugins# wget https://www.pc-freak.net/files/a_must_have_wordpress_plugins_collection.tar.gz
linux:/var/www/blog/wp-content/plugins# tar -zxvf a_must_have_wordpress_plugins_collection.tar.gz
...
linux:/var/www/blog/wp-content/plugins# unzip *.zip
Now as they should be installed under the plugins directory go and enable the plugins.
Further on many of the plugins will require configuration from the menus:
Settingsor in the menu
Tools
After being setup up your new wordpress installation will look significantly better, you will notice a tons of useful features which you might have previously missing and desperately needed 😉
Most of the bundled package of wordpress plugins works fine with wordpress version 3.1, if you’re trying to install enable and configure the plugins on some other versions of wordpress, there might be problems!
If you experience problems by trying out my bunch of wordpress plugins please drop me a comment.
I hope you enjoyed this improvised article, if these bunch of plugins are useful to you please give me a thanks 🙂
Thanks!
Tags: adsense, advertising manager, aims, ajax, analytics, auto tag, bible, bible verse, blog, boost, Button, collection, commentluv, compilation, complete list, configure, custom login, cyr, drop, extended search, generation, google, google sitemap generator, html generation, Inactive, installation, interface, major search engines, mechanism, mod, option, package, php, platform, plugin, post, Search, search bar, search plugin, SEO, Settingsor, Slugs, social networks, squares, time, twitter, wget, widget, wordbook, Wordpress, wordpress blog, wordpress plugins, ypn
Posted in SEO, Web and CMS, Wordpress | 8 Comments »